









小序
赌书消得泼茶香,
当时只道是寻常。
本篇涉及Python的文件操作,尤指对word文件的操作
涉及文本读写与正则表达式的文本处理
基础的内容可看之前的 Python文件 管理文章
正文
本文就对word 文档的读写和处理进行阐述
简单实现
要读取.doc文件的内容,可以使用Python的python-docx库。
python-docx库是一个用于读取和操作Microsoft Word文件的库。
以下是一个示例,展示如何使用python-docx库读取.doc文件的内容:
首先,确保已经安装了python-docx库。可以使用以下命令进行安装:
pip install python-docx
然后,使用以下代码读取.doc文件的内容
from docx import Document
# 打开.doc文件
doc = Document('example.doc')
# 读取每个段落的内容
for paragraph in doc.paragraphs:
print(paragraph.text)
在上面的代码中,我们首先导入Document类和docx模块。
然后,使用Document类打开.doc文件,并将其赋值给doc变量。
接下来,使用for循环遍历doc.paragraphs,其中doc.paragraphs是一个包含所有段落的列表。
在循环中,我们使用paragraph.text来获取每个段落的文本内容,并打印出来。
运行上面的代码,将输出.doc文件中每个段落的内容。
请注意,python-docx库仅支持.docx文件格式,不支持旧的.doc二进制文件格式。如果要读取旧的.doc文件,可以尝试使用其他库,如pywin32或python-doc。
复杂文本处理示例
doc文件中有名词解释,怎么实现读取和正确分配好每个名词的解释
要实现读取.doc文件中的名词解释并正确分配每个名词的解释,可以使用一些文本处理技术,如关键词匹配或自然语言处理。以下是一个示例,展示如何使用Python来实现
import re
from docx import Document
# 打开.doc文件
doc = Document('example.doc')
# 定义名词和解释的字典
definitions = {
"academic departments": "",
"academic titles": ""
}
# 读取每个段落的内容
for paragraph in doc.paragraphs:
text = paragraph.text
# 匹配名词和解释
for term, definition in definitions.items():
if term.lower() in text.lower():
# 提取解释
match = re.search(r"(?i)" + term + r":\s*(.*)", text)
if match:
definition = match.group(1)
definitions[term] = definition
# 打印名词和解释
for term, definition in definitions.items():
print(term + ": " + definition)
在上面的代码中,我们首先导入re模块和Document类。然后,使用Document类打开.doc文件,并将其赋值给doc变量。接下来,我们定义了一个名词和解释的字典definitions,其中名词作为键,初始解释为空字符串。
在循环中,我们遍历doc.paragraphs,并使用re.search()函数在每个段落的文本中进行匹配。如果匹配到了名词,我们使用正则表达式提取解释,并更新对应名词的解释。
最后,我们打印出每个名词和对应的解释。
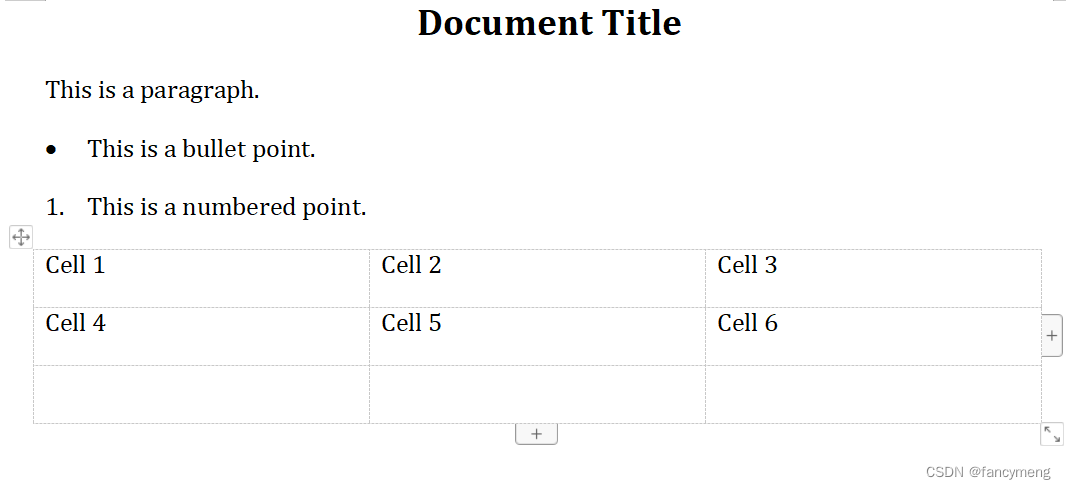
利用Python 实现文档编写
from docx import Document
from docx.shared import Pt
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
# 创建一个新的Word文档
doc = Document()
# 添加标题
title = doc.add_paragraph()
title_run = title.add_run('Document Title')
title_run.bold = True
title_run.font.size = Pt(16)
title.alignment = WD_PARAGRAPH_ALIGNMENT.CENTER
# 添加段落
paragraph = doc.add_paragraph('This is a paragraph.')
# 添加列表
doc.add_paragraph('This is a bullet point.', style='List Bullet')
doc.add_paragraph('This is a numbered point.', style='List Number')
# 添加表格
table = doc.add_table(rows=3, cols=3)
table.cell(0, 0).text = 'Cell 1'
table.cell(0, 1).text = 'Cell 2'
table.cell(0, 2).text = 'Cell 3'
table.cell(1, 0).text = 'Cell 4'
table.cell(1, 1).text = 'Cell 5'
table.cell(1, 2).text = 'Cell 6'
doc.save('output.docx')
output.docx 结果
插入图片
要在Word文档中插入图片,可以使用docx库的add_picture()方法。
以下是一个示例代码,演示了如何将图片插入到Word文档中
from docx import Document
# 创建一个新的Word文档
doc = Document()
# 插入图片
doc.add_picture('image.jpg', width=doc.shared.Cm(10), height=doc.shared.Cm(10))
# 保存文档
doc.save('output.docx')
在上面的代码中,我们假设有一张名为image.jpg的图片文件,它位于当前工作目录中。
代码使用add_picture()方法将该图片插入到Word文档中。
width和height参数用于设置图片的宽度和高度,这里我们将宽度和高度都设置为10厘米
最后,使用save()方法将生成的Word文档保存为output.docx文件。
简单总结
具体的文档操作依据本人的需求有着不同的方法,读者可依据自己的具体需求进行尝试和练习
学会利用Python 进行文档操作,实质上节省了不少的气力
当然,更多的是读取文件/处理后写入文件
这大多都应用了数据库的操作
下面,我用我的实际案例来展示一下 读取内容–> 处理内容 --> 写入数据库 的过程
import pymysql
from docx import Document
def save_to_database(first_word, words, words_exp):
db = pymysql.connect(
host='localhost',
port=3306,
user='xxx',
passwd='xxx',
database='xxx',
charset='utf8'
)
cur = db.cursor()
cur.execute("insert into table_name(w1, w2, w3) values (%s, %s, %s)",(w1, w2, w3))
db.commit()
def get_information():
file_path = 'xxx'
# 打开文件
doc = Document(file_path)
# 以下为方便判断和顺利分开读取信息
# explain 为每个词语的解释 list 索引词 dict为存储正式的词与解释
explain = ''
list = []
dict = {}
# 读取每个段落的内容
for paragraph in doc.paragraphs:
text = paragraph.text
if is_text_bold(paragraph):
if not list:
list.append(text)
else:
dict[list[0]] = explain
list = []
explain = ''
list.append(text)
else:
if text == ' ':
continue
explain = explain + text + '\n'
dict[list[0]] = explain
return dict
# 判断是否为大写
def is_text_bold(paragraph):
for run in paragraph.runs:
if run.bold:
return True
return False
def save():
dict = get_information()
# 遍历取键和值
for key, value in dict.items():
first_word = key[0].upper()
save_to_database(first_word, key, value)
save()
处理的内容如上,为 专业词 和 相关解释
(内容涉及隐私,就不再上传了)
最终插入数据库,便于后续的编程

只能说尝试过,实验过,自然就能掌握的更为顺畅
结束语
偷偷挤进一缕斜阳,送来满满幸福
盼一切顺利~















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











