






对于初学者来说,学会spark的初级三种部署方式还是特别重要的。
(本人是小白,以下是学习笔记,如果有哪里错的或者有疑问的,欢迎指正!谢谢!)
Spark的三种部署方式分别是standalone,Spark on yarn,Spark on mesos.
Standalone 方式:类似于mapreduce1.0,实现了容错性和资源管理,用的是Spark自带的资源管理器standaloe.
后两者是未来的发展趋势,如果让Spark运行在一个通用的资源管理器上,这样就可以与其他计算框架公用一个集群资源,降低运维成本和提高资源利用率(资源按需分配),下面介绍下他们的优缺点和如何部署他们。
local(本地模式):常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
standalone(集群模式):典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark支持ZooKeeper来实现 HA
on yarn(集群模式): 运行在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算
on mesos(集群模式): 运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算
on cloud(集群模式):比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3;Spark 支持多种分布式存储系统:HDFS 和 S3
一、Standalone模式:
也称为独立模式。自带一套服务系统,可以直接部署到集群中去,所以不要依赖于其他的资源管理系统。可以这么说,此模式是其他两种模式的基础。所以有一种开发新型计算框架的思路:先设计它的standalone模式,为了快速开发,起初不需要考虑服务(比如master/slave)的容错性,之后再开发相应的wrapper(封装),将standalone模式下的服务全部移动到yarn或者mesos上,由资源管理负责服务本身的容错。目前Spark在standalone模式下是没有单点故障问题的(是单个点发生故障的时候会波及到整个系统或者网络,从而导致整个系统或者网络的瘫痪。在设计IT基础设施时应避免的。)借助于zookeeper实现的,类似于Hbase master单点故障解决方案。将Spark standalone与mapreduce比较,就会发现他们在架构上是完全一致的:
1、都是master/slave服务组成的,且起初均存在单点故障,但都通过zookeeper解决了;
2、各个节点上的资源被抽象成粗粒度的slot,有多少个slot,就有多少个Task。spark的slot只有一种,可以供各种task使用,可以提高资源利用率。
关于如何部署Spark yarn模式?
Yarn模式部署:
准备工作,首先要安装hadoop,布置hadoop集群。
1.安装java
jdk下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.htmlz
然后将下载的安装包解压到一个指定的目录
例如:
tar -zxvf jdk-8u101-Linux-x64.tar.gz -C /project/java
然后修改环境变量文件 vi /etc/profile,在末尾添加:
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_101
export JRE_HOME=/home/hadoop/software/jdk1.8.0_101/jre
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export CLASSPATH=$CLASSPATH:.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
`
wq!保存之后,;利用source /etc/profile,使修改生效。
此时出现这种状态就是安装成功

2.修改计算机环境
首先要计划一下,这里使用1台master,2台slave的结构。
我们搭建虚拟机集群,一般是在一台上把全部配置好了,然后再克隆出两台来,再去修改一小部分配置,集群就能够用的起来了。
在master节点上,为了方便,先把此台主机的名字改为vi /etc/hostname,将里面的主机名字改为master。
之后利用ifconfig看一下每台机子的ip
最后修改hosts文件:vi /etc/hosts
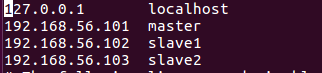
`注意:hosts文件里正常会存在一个localhost 及其 对应的IP地址,千万不要删除它,直接把以上三行信息给加到后边就行了,删除了localhost,Spark会找不到入口!“
3 安装SSH服务
命令:apt-get install openssh-server
SSH具体的配置在克隆出两台虚拟slave后再配置。
这里可能会出现问题,有可能你的机子上还没有安装这样的服务
例如:安装不成功,是因为没有update 的缘故
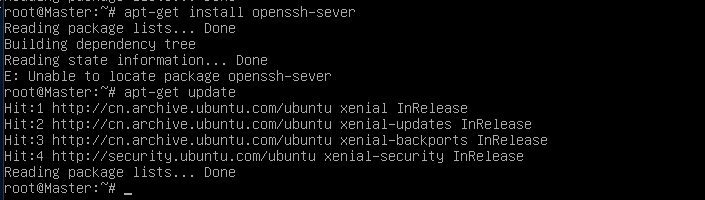
所以要先更新
更新之后,安装ssh,
apt-get install openssh-server
之后启动ssh

启动成功
接着下面是SSH免登陆密码设置:
首先用ssh 命令可以生成 known-hosts,之后用ssh-keygen -t rsa命令可以生成 id——rsa(私钥) id——rsa.pub(公钥)
但是这时候发现被拒绝了
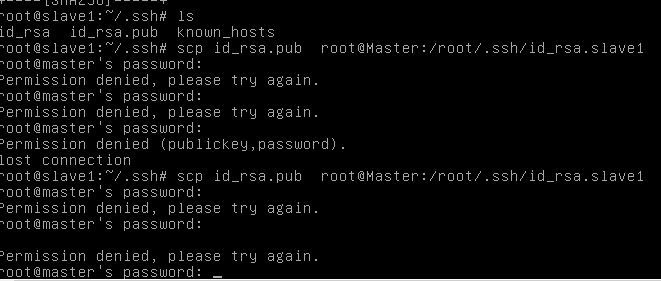
how to do?
解决方法:将ssh配置文件中的PermitRootLogin no 改为PermitRootLogin yes就可以登陆了。
将slave1和slave2中的密钥id_rsa.pub发送到master,分别变成id_rsa.pub.slave1和id_rsa.pub.slave2
Master 收到后。用cat id_rsa.pub.slave1 >>authorized_keys cat id_rsa.pub >>authorized_keys
cat id_rsa.pub.slave>>authorized_keys
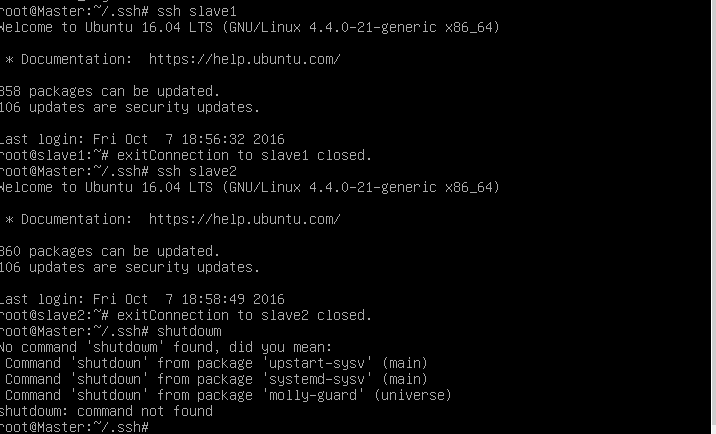
然后Master用scp _authorized_keys root@slave1:/root/.ssh/authorized_keys传到slave1中
同理传到slave2中
这时,再用ssh验证,可以发现可以免密钥登陆了
4.安装hadoop
如果SSH安装好之后,接着安装hadoop
步骤:1、解压安装hadoop安装包,利用tar -zxvf 命令
2、修改配置文件:
- hadoop-env.sh,在里面设置JAVA_HOME。
# The java implementation to use.
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_101- yarn-env.sh,在里面设置JAVA_HOME。
# some Java parameters
export JAVA_HOME=/home/hadoop/software/jdk1.8.0_101
- slaves,在这个文件里面加入作为slave的IP地址或者对应的hosts映射名字。
slave1
slave2- core-site.xml,右键编辑。
< configuration>
< property>
< name>fs.defaultFS</name>
< value>hdfs://master:9000/</value>
< /property>
< property>
< name>hadoop.tmp.dir</name>
< value>file:/home/hadoop/software/hadoop-2.7.3/tmp</value>
< /property>
< /configuration>- hdfs-site.xml修改
< configuration>
< property>
< name>dfs.namenode.secondary.http-address</name>
< value>master:9001</value>
< /property>
< property>
< name>dfs.namenode.name.dir</name>
< value>file:/home/hadoop/software/hadoop-2.7.3/dfs/name</value>
< /property>
< property>
< name>dfs.datanode.data.dir</name>
< value>file:/home/hadoop/software/hadoop-2.7.3/dfs/data</value>
< /property>
< property>
< name>dfs.replication</name>
< value>3</value>
< /property>
< /configuration>- mapred-site.xml编辑
< configuration>
< property>
< name>mapreduce.framework.name</name>
< value>yarn</value>
< /property>
< /configuration>- yarn-site.xml编辑
< configuration>
< property>
< name>yarn.nodemanager.aux-services</name>
< value>mapreduce_shuffle</value>
< /property>
< property>
< name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
< value>org.apache.hadoop.mapred.ShuffleHandler</value>
< /property>
< property>
< name>yarn.resourcemanager.address</name>
< value>master:8032</value>
< /property>
< property>
< name>yarn.resourcemanager.scheduler.address</name>
< value>master:8030</value>
< /property>
< property>
< name>yarn.resourcemanager.resource-tracker.address</name>
< value>master:8035</value>
< /property>
< property>
< name>yarn.resourcemanager.admin.address</name>
< value>master:8033</value>
< /property>
< property>
< name>yarn.resourcemanager.webapp.address</name>
< value>master:8088</value>
< /property>
< /configuration>














 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









