






一、题目
本实验,有两个任务:
- 任务1:你需要修改rowcol.c,跑得尽可能高的得分。注意考虑矩阵元素在存储器中的排列;
- 任务2:你需要修改poly.c,跑得尽可能高的得分。注意你需要首先实现一个指定学号的常系数多项式,然后才能实现其他函数。
【提升】建议有能力的同学考虑能否用SIMD指令完成。
具体请参考实验文档。
二、一些见解
性能优化其实主要考虑时间、空间局部性的利用,相关知识好好上课看看课本就能理解,其实不难理解。做完之后有个同学跟我分享了他的SIMD实现,跑的飞快~!!!建议硬件和能力支持的可以考虑用SIMD来实现(我的设备不允许我这样做哈哈哈哈哈……阴暗爬行🧗(我的为什么不支持)……(扭曲🌀)……(尖叫🙀))还有,注意,如果是笔记本,记得插电做,不要开省电模式,因为插电之后笔记本本身工作频率啥的会比较高,结果会比较好,亲测我的代码插电120,不插电0分……
三、开源代码:重生之学姐为你当牛马
poly.c
/**************************************************************************
多项式计算函数。按下面的要求编辑此文件:
1. 将你的学号、姓名,以注释的方式写到下面;
2. 实现不同版本的多项式计算函数;
3. 编辑peval_fun_rec peval_fun_tab数组,将你的最好的答案
(最小CPE、最小C10)作为数组的前两项
***************************************************************************/
/*
*/
#include <stdio.h>
#include <stdlib.h>
typedef int (*peval_fun)(int*, int, int);
typedef struct {
peval_fun f;
char *descr;
} peval_fun_rec, *peval_fun_ptr;
/**************************************************************************
Edit this comment to indicate your name and Andrew ID
#ifdef ASSIGN
Submission by Harry Q. Bovik, bovik@andrew.cmu.edu
#else
Instructor's version.
Created by Randal E. Bryant, Randy.Bryant@cs.cmu.edu, 10/07/02
#endif
***************************************************************************/
/*
实现一个指定的常系数多项式计算
第一次,请直接运行程序,以便获知你需要实现的常系数是啥
*/
/*
1、register 是表示使用cpu内部寄存器(寄存器是中央处理器内的组成部分。
寄存器是有限存贮容量的高速存贮部件)的变量,而平时的int是把变量放在内存中,
存到寄存器中可以加快变量的读写速度。
2、位移比直接乘除法消耗的时间要短得多
*/
//35 69 50 92
int const_poly_eval(int *not_use, int not_use2, int x)
{
register int result = 0;
register int x1, x2, x3;
register int tmp = x;
register int tmp1 = tmp * tmp;
register int tmp2 = tmp1 * tmp;
x1 = (tmp << 6) + (tmp << 2) + tmp;
x2 = (tmp1 << 5) + (tmp1 << 4) + (tmp1 << 1) ;
x3 = (tmp2 << 6) + (tmp2 << 5) - (tmp2 << 2);
result = 35 + x1 + x2 + x3;
return result;
}
/* 多项式计算函数。注意:这个只是一个参考实现,你需要实现自己的版本 */
/*
友情提示:lcc支持ATT格式的嵌入式汇编,例如
_asm("movl %eax,%ebx");
_asm("pushl %edx");
可以在lcc中project->configuration->Compiler->Code Generation->Generate .asm,
将其选中后,可以在lcc目录下面生成对应程序的汇编代码实现。通过查看汇编文件,
你可以了解编译器是如何实现你的代码的。有些实现可能非常低效。
你可以在适当的地方加入嵌入式汇编,来大幅度提高计算性能。
*/
int poly_eval(int *a, int degree, int x)
{
int result = 0;
int i;
int xpwr = 1; // x的幂次
// printf("阶=%d\n",degree);
for (i = 0; i <= degree; i++) {
result += a[i]*xpwr;
xpwr *= x;
}
return result;
}
/*
1、并行设计:①如果最高幂次不超过10:每两项做一次运算(如果i=0说明a[0]没有纳入运算,如果不为0则说明刚好算完)
②如果超过10:则每10项一算
为什么选10做分界线?因为答案测试要测10项的😅
2、次方仍然沿用上面的,提前算好!!!
*/
int poly_eval12(int* a, int degree, int x)
{
register int result = 0;
register int i=degree, tmp = x;
register int x2 = tmp * tmp;
if (i >= 10) {
register int x3 = x2 * tmp, x4 = x2 * x2, x5 = x3 * x2, x6 = x3 * x3, x7 = x4 * x3, x8 = x4 * x4, x9 = x5 * x4, x10 = x5 * x5;
for (; i > 8; i -= 10) {
result = result * x10 + a[i] * x9 + a[i - 1] * x8 + a[i - 2] * x7 + a[i - 3] * x6 + a[i - 4] * x5
+ a[i - 5] * x4 + a[i - 6] * x3 + a[i - 7] * x2 + a[i - 8] * tmp + a[i - 9];
}
}
if (i > 0) {
for (; i > 0; i -= 2) {
result = result * x2 + a[i] * tmp + a[i - 1];
}
}
result = i == 0 ? result * x + a[0] : result;
return result;
}
/*
这个表格包含多个数组元素,每一组元素(函数名字, "描述字符串")
将你认为最好的两个实现,放在最前面。
比如:
{my_poly_eval1, "超级垃圾实现"},
{my_poly_eval2, "好一点的实现"},
*/
peval_fun_rec peval_fun_tab[] =
{
/* 第一项,应当是你写的最好CPE的函数实现 */
{poly_eval12, "my CPE"},
/* 第二项,应当是你写的在10阶时具有最好性能的实现 */
{poly_eval12, "my degree=10"},
{poly_eval, "poly_eval: reference implementation"},
/* 下面的代码不能修改或者删除!!表明数组列表结束 */
{NULL, ""}
};
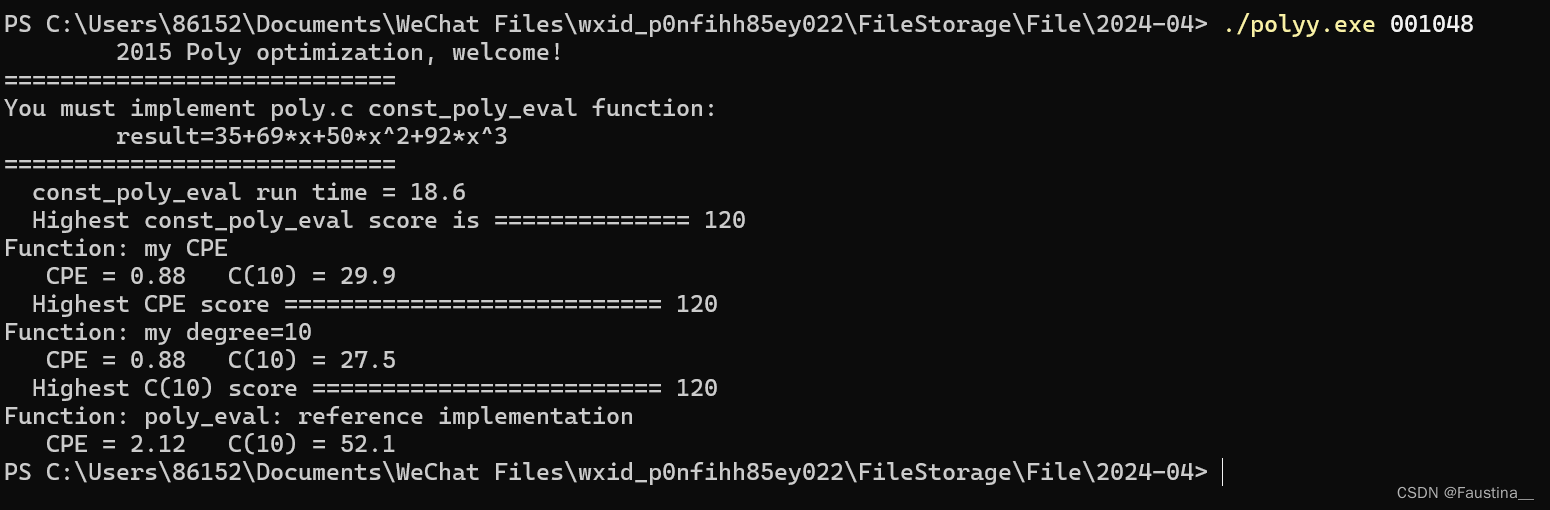
结果是这样的:
matrix.c
/**************************************************************************
行/列求和函数。按下面的要求编辑此文件:
1. 将你的学号、姓名,以注释的方式写到下面;
2. 实现不同版本的行列求和函数;
3. 编辑rc_fun_rec rc_fun_tab数组,将你的最好的答案
(最好的行和列求和、最好的列求和)作为数组的前两项
***************************************************************************/
/*
*/
#include <stdio.h>
#include <stdlib.h>
#include "rowcol.h"
#include <math.h>
/* 参考的列求和函数实现 */
/* 计算矩阵中的每一列的和。请注意对于行和列求和来说,调用参数是
一样的,只是第2个参数不会用到而已
*/
/*传统双循环遍历求和*/
void c_sum(matrix_t M, vector_t rowsum, vector_t colsum)
{
int i,j;
for (j = 0; j < N; j++) {
colsum[j] = 0;
for (i = 0; i < N; i++)
colsum[j] += M[i][j];
}
}
/*
矩阵的双循环遍历是不可避免的
but!!!
由于指针的跳跃遍历导致传统的求和效率很低
so
不妨一行一行的遍历,让指针不再跨区跳跃!!!
变量仍然和poly里的一样选择register int
另外,根据一些博主的blog,++i要比i++快!!!
*/
void mybest_c_sum(matrix_t M, vector_t rowsum, vector_t colsum)
{
register int i, j=0;
for (; j < N; ++j) {
colsum[j] = 0;
for (i=0; i < N; i = i + 2) {
colsum[j] += M[i][j];
colsum[j] += M[i + 1][j];
}
}
}
/* 参考的列和行求和函数实现 */
/* 计算矩阵中的每一行、每一列的和。 */
/*传统双循环遍历求和*/
void rc_sum(matrix_t M, vector_t rowsum, vector_t colsum)
{
int i,j;
for (i = 0; i < N; i++) {
rowsum[i] = colsum[i] = 0;
for (j = 0; j < N; j++) {
rowsum[i] += M[i][j];
colsum[i] += M[j][i];
}
}
}
/*
既然双循环遍历无法更改,那怎么办?怎么改进???
并行!!!
可是……我总不能行列同时并行,那样那面让读指针来回跳,效率不升反降
所以我只能一维并行
同上,变量仍然选择register int,用++i而不用i++
*/
void mybest_rc_sum(matrix_t M, vector_t rowsum, vector_t colsum)
{
register int i=0, j;
register int h, l, c = N - 3;
for (; i < N; ++i)
{
h = 0, l = 0;
j = 0;
for (; j < c; j += 4)
{
h += (M[i][j] + M[i][j + 1]) + (M[i][j + 2] + M[i][j + 3]);
l += (M[j][i] + M[j + 1][i]) + (M[j + 2][i] + M[j + 3][i]);
}
for (; j < N;)
{
h += M[i][j], l += M[j++][i];
}
rowsum[i] = h, colsum[i] = l;
}
}
/*
这个表格包含多个数组元素,每一组元素(函数名字, COL/ROWCOL, "描述字符串")
COL表示该函数仅仅计算每一列的和
ROWCOL表示该函数计算每一行、每一列的和
将你认为最好的两个实现,放在最前面。
比如:
{my_c_sum1, "超级垃圾列求和实现"},
{my_rc_sum2, "好一点的行列求和实现"},
*/
rc_fun_rec rc_fun_tab[] =
{
/* 第一项,应当是你写的最好列求和的函数实现 */
{mybest_c_sum, COL, "Best column sum"},
/* 第二项,应当是你写的最好行列求和的函数实现 */
{mybest_rc_sum, ROWCOL, "Best row and column sum"},
{c_sum, COL, "Column sum, reference implementation"},
{rc_sum, ROWCOL, "Row and column sum, reference implementation"},
/* 下面的代码不能修改或者删除!!表明数组列表结束 */
{NULL,ROWCOL,NULL}
};
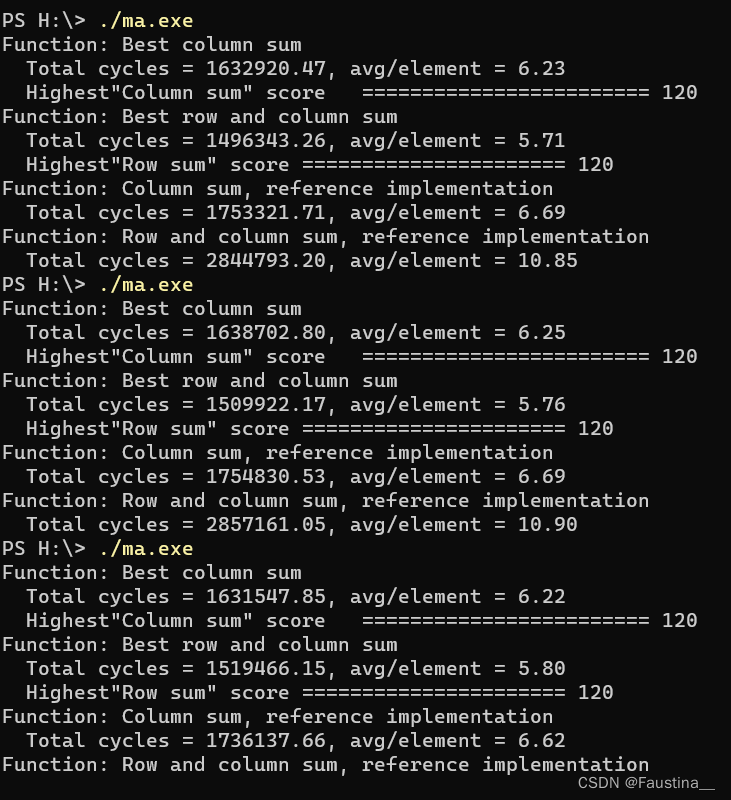
结果:















 7869
7869











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









