










1 - Python语法复习:__call__的用法
创建一个新的python文件,输入
class Person:
def __call__(self, name):
print("__call__"+"hello "+name)
def hello(self, name):
print("hello"+ name)
person = Person()
person("zhangsan")
person.hello("lisi")
输出结果为
__call__hello zhangsan
hellolisi
2 - Normalize的使用
Normalize的作用为归一化和标准化

输入下述代码
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/hymenoptera_data/train/ants_image/0013035.jpg")
print(img)
# ToTensor PIL改为Tensor类型
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize 计算均值和标准差
# """Normalize a tensor image with mean and standard deviation.
# This transform does not support PIL Image.
# Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``
# channels, this transform will normalize each channel of the input
# ``torch.*Tensor`` i.e.,
# ``output[channel] = (input[channel] - mean[channel]) / std[channel]``
# tensor (0,1) -> (-1,1)
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
writer.close()
运行后,可以发现输出
D:\Anaconda3\envs\pytorch\python.exe D:/研究生/代码尝试/P10_UsefulTransforms.py
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=768x512 at 0x20B126FA040>
tensor(0.3137)
tensor(-0.3725)
在终端输入
(pytorch) D:\研究生\代码尝试>tensorboard --logdir=logs
打开网址
TensorFlow installation not found - running with reduced feature set.
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.8.0 at http://localhost:6006/ (Press CTRL+C to quit)
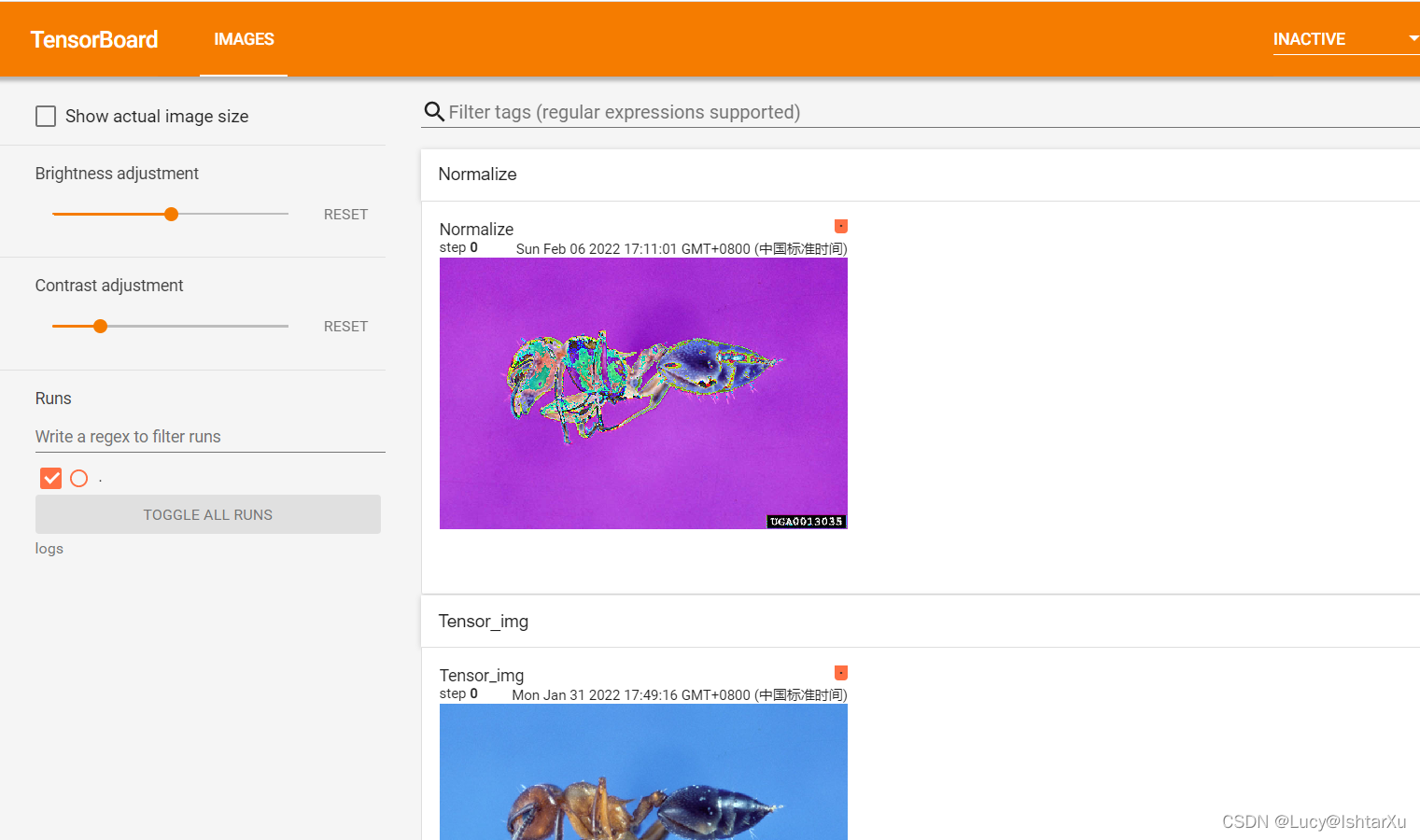
阴间的蚂蚁就出现啦
3 - Resize的使用
Resize的作用为缩放
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/hymenoptera_data/train/ants_image/0013035.jpg")
print(img)
# ToTensor PIL改为Tensor类型
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize 计算均值和标准差
# """Normalize a tensor image with mean and standard deviation.
# This transform does not support PIL Image.
# Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``
# channels, this transform will normalize each channel of the input
# ``torch.*Tensor`` i.e.,
# ``output[channel] = (input[channel] - mean[channel]) / std[channel]``
# tensor (0,1) -> (-1,1)
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
# Resize
"""Resize the input image to the given size.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions"""
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> Totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
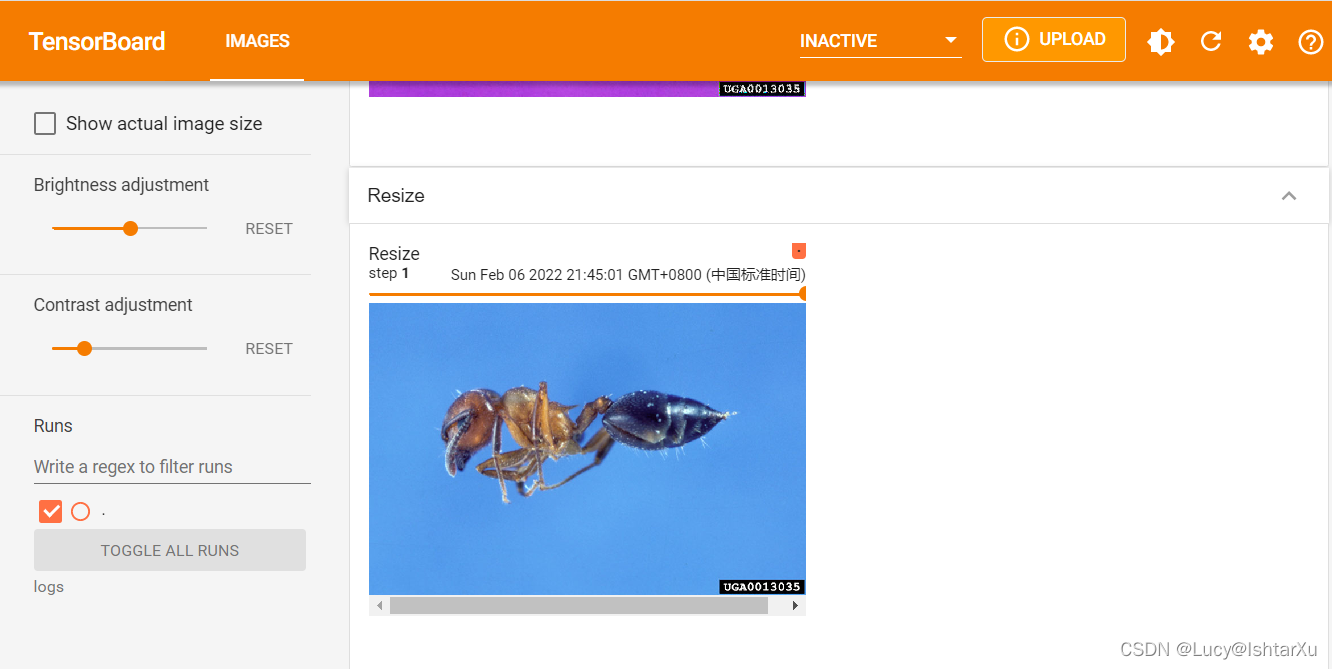
writer.add_image("Resize", img_resize, 0)
print(img_resize)
writer.close()
输出结果为
<PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=768x512 at 0x18990DDA040>
tensor(0.3137)
tensor(-0.3725)
(768, 512)
tensor([[[0.3137, 0.3137, 0.3176, ..., 0.3137, 0.3137, 0.3020],
[0.3176, 0.3176, 0.3176, ..., 0.3098, 0.3137, 0.3020],
[0.3216, 0.3216, 0.3176, ..., 0.3059, 0.3137, 0.3059],
...,
[0.3412, 0.3373, 0.3373, ..., 0.0196, 0.2196, 0.3608],
[0.3412, 0.3373, 0.3373, ..., 0.3490, 0.3373, 0.3373],
[0.3412, 0.3373, 0.3373, ..., 0.3529, 0.3137, 0.3216]],
[[0.5922, 0.5922, 0.5961, ..., 0.5922, 0.5922, 0.5804],
[0.5961, 0.5961, 0.5961, ..., 0.5882, 0.5922, 0.5804],
[0.6000, 0.6000, 0.5961, ..., 0.5843, 0.5922, 0.5843],
...,
[0.6275, 0.6235, 0.6235, ..., 0.1020, 0.4157, 0.6157],
[0.6275, 0.6235, 0.6235, ..., 0.5373, 0.5882, 0.6078],
[0.6275, 0.6235, 0.6235, ..., 0.6392, 0.6275, 0.6275]],
[[0.9137, 0.9137, 0.9176, ..., 0.9137, 0.9137, 0.9020],
[0.9176, 0.9176, 0.9176, ..., 0.9098, 0.9137, 0.9020],
[0.9216, 0.9216, 0.9176, ..., 0.9059, 0.9137, 0.9059],
...,
[0.9294, 0.9255, 0.9255, ..., 0.1961, 0.6353, 0.9059],
[0.9294, 0.9255, 0.9255, ..., 0.7922, 0.9098, 0.9451],
[0.9294, 0.9255, 0.9255, ..., 0.9412, 0.9569, 0.9373]]])
打开Tensorboard看看吧~

4 - Compose的使用
将几种transform进行组合

from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/hymenoptera_data/train/ants_image/0013035.jpg")
print(img)
# ToTensor PIL改为Tensor类型
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize 计算均值和标准差
# """Normalize a tensor image with mean and standard deviation.
# This transform does not support PIL Image.
# Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``
# channels, this transform will normalize each channel of the input
# ``torch.*Tensor`` i.e.,
# ``output[channel] = (input[channel] - mean[channel]) / std[channel]``
# tensor (0,1) -> (-1,1)
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
# Resize
"""Resize the input image to the given size.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions"""
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> Totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize, 0)
print(img_resize)
# Compose - resize - 2
# Compose就是将函数的功能进行整合,设定一个模板,按照模板中设定好的操作处理
"""Composes several transforms together. This transform does not support torchscript.
Please, see the note below."""
trans_resize_2 = transforms.Resize(512)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
writer.close()
输出结果为
5 - RandomCrop的用法
作用:随机裁剪图片
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img = Image.open("dataset/hymenoptera_data/train/ants_image/0013035.jpg")
print(img)
# ToTensor PIL改为Tensor类型
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("ToTensor", img_tensor)
# Normalize 计算均值和标准差
# """Normalize a tensor image with mean and standard deviation.
# This transform does not support PIL Image.
# Given mean: ``(mean[1],...,mean[n])`` and std: ``(std[1],..,std[n])`` for ``n``
# channels, this transform will normalize each channel of the input
# ``torch.*Tensor`` i.e.,
# ``output[channel] = (input[channel] - mean[channel]) / std[channel]``
# tensor (0,1) -> (-1,1)
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize", img_norm)
# Resize
"""Resize the input image to the given size.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions"""
print(img.size)
trans_resize = transforms.Resize((512, 512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_resize(img)
# img_resize PIL -> Totensor -> img_resize tensor
img_resize = trans_totensor(img_resize)
writer.add_image("Resize", img_resize, 0)
print(img_resize)
# Compose - resize - 2
# Compose就是将函数的功能进行整合,设定一个模板,按照模板中设定好的操作处理
trans_resize_2 = transforms.Resize(512)
# PIL -> PIL -> tensor
trans_compose = transforms.Compose([trans_resize_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2, 1)
# RandomCrop
"""Crop the given image at a random location.
If the image is torch Tensor, it is expected
to have [..., H, W] shape, where ... means an arbitrary number of leading dimensions,
but if non-constant padding is used, the input is expected to have at most 2 leading dimensions"""
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
writer.close()
不知道返回值的时候
*print
*print(type())
*debug














 3482
3482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









