






一、打开文件
完整的语法格式:
open(file,mode = 'r',buffering = -1,encoding = None,errors = None,newline = None,closefd = True,opener = None)
- file: 必需,文件路径(相对或者绝对路径)。
- mode: 可选,文件打开模式
- buffering: 设置缓冲
- encoding: 一般使用utf8
- errors: 报错级别
- newline: 区分换行符
- closefd: 传入的file参数类型
- opener: 设置自定义开启器,开启器的返回值必须是一个打开的文件描述符。
mode的类型
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。要求操作文件必须已存在。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。(可读取可写入)写入时,将追加在文件内容结尾。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。(只能执行写不能读) |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。若刚用‘a+’打开一个文件,一般不能直接读取。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认mode为文本模式r。
文件数据的读和写
#先打开文件:
f = open('C:\\Users\\Administrator\\Desktop\\python.txt','r',encoding = 'utf-8')
#使用read()方法,查看文件里的内容:
print(f.read())
#关闭文件
f.close()
运行结果:
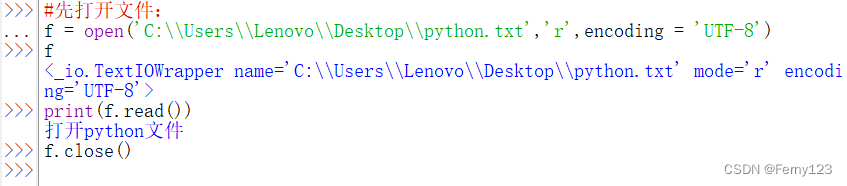
1、当未指定文件编码格式时,如果文件编码格式与当前默认的编码格式不一致,那么文件内容的读写将出现错误,在python3下,可以通过encoding参数指定编码方式。
2、结尾一定要使用close()来关闭文件。原因主要是:
- 节约资源和内存耗损;
- 可以释放所占用的系统资源并尽早将文件置于更安全的状态,只有关闭文件后,文件内容才能同步到磁盘。
3、当读写文件本身有错误时,即使使用close()也可能会出现文件无法正常关闭的现象。
二、witn open()方法
with 的作用相当于调用close()方法,因此当我们使用with open( )在对文件操作完成后,无需通过close()关闭文件,文件会自动关闭。这种方法的安全系数更高,同时也避免了忘记关闭文件的问题。
with open('file','r',encoding = 'utf-8') as f:
#使用with open 打开文件
with open('C:\\Users\\Administrator\\Desktop\\python.txt','r',encoding = 'utf-8') as f:
#查看文件内容
print(f.read())运行结果:
















 356
356











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









