









图片中的文字怎么在线识别?很多小伙伴在接收到图片类型的文件时,不知道怎么处理其中记录的信息。打字整理嫌麻烦怕出错的话,可以借助识别软件来处理,下面给大家介绍三种比较好用的工具,希望能解决你的问题。

方法一、在线识别图片文字
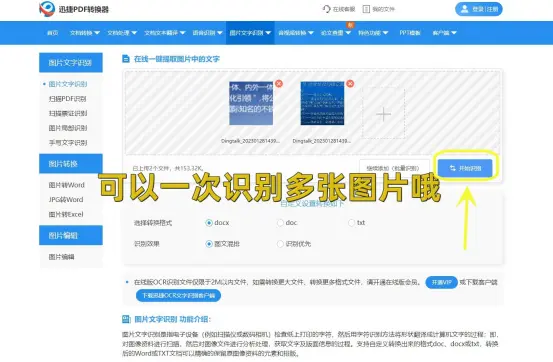
打开网页后点击图片文字识别。

之后点击选择文件来上传图片,转换格式可自行设置哦~

这里可以一次上传多张图片进行识别,点击开始识别后可以在界面上方我的文件处,查收识别结果。
方法二、软件识别图片文字
软件识别的好处是不限图片大小,速度也很快。
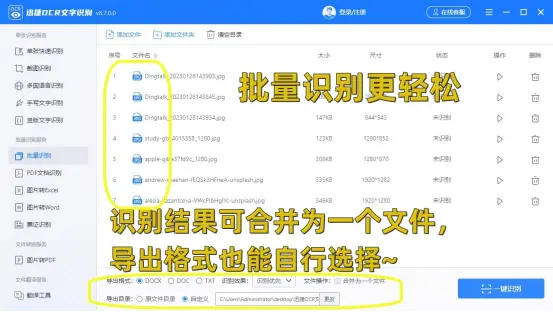
1.首先打开软件,左侧功能栏中有单张和多张批量识别,可按需选择。之后点击界面中央的添加文件来上传图片,软件支持PNG、JPG、JPEG和BMP格式。

2.图片添加进来后,设置好下方的导出格式和导出目录等参数,点击一键识别即可。
识别结果如下,识别后的图片文字很清晰,段落格式也和原图一致。

方法三、微信识别图片文字
微信除了聊天社交,还可以用来办公,比如它的文字识别功能,手机电脑都可以,这里以手机为例。
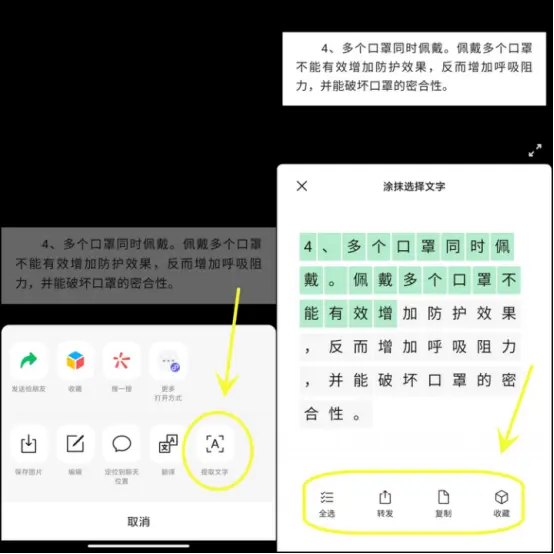
将待识别的图片发到微信里后,点击图片,选择右下角“...”

之后点击提取文字,等待识别完毕后,涂抹选择需要的文字,下方的复制等选项自行选择即可。
关于怎么在线识别图片文字就介绍到这,在线识别很方便,但电脑或手机软件识别也很高效哦。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









