







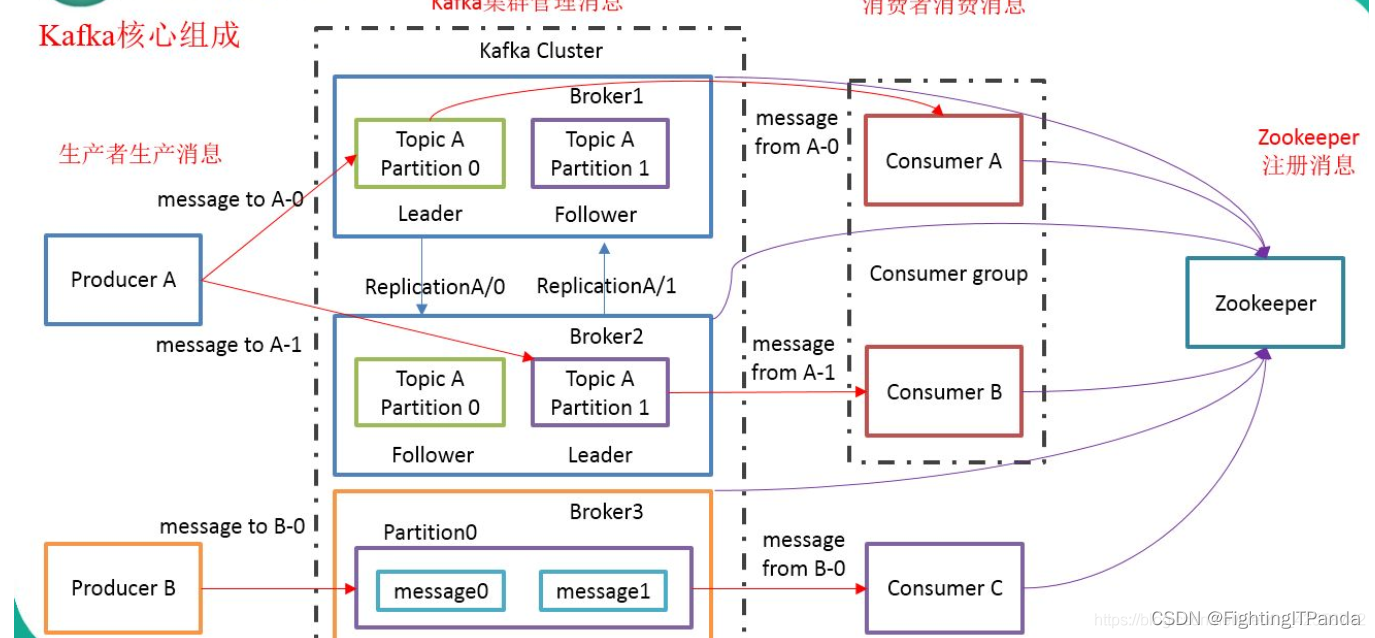
在kafka之旅,我们会大量讨论Kafka中的术语,那么就让我们先来了解一下这些核心概念
消息(Message):
kafka的数据单元称为消息,相当于DB里的一行数据或一条记录
消息由字节数组组成
批次:
生产者组一批数据再向kafka推送,批次大小可以通过参数配置
把消息分成批次传输(消息属于同一个主题,同一个分区),减少网络开销
批次越大,单位时间内处理的消息越多,单个消息传输时间越长
批次数据进行压缩,吞吐量可达千万条消息每秒(rabblitMQ 只能达到万级消息/s,延迟低,微妙级)
producer在向topic发送消息前,会对这一批次消息进行压缩处理
压缩需要CPU进行计算,对CPU性能有要求
压缩带来的磁盘空间和带宽的节省,远大于CPU开销的代价,这样的压缩是值得的
模式:
数据序列化、反序列化方式
主题(Topic):
消息通过主题进行分类
生产者向指定Topic发送数据,消费者订阅该Topic消费数据
逻辑概念,相当于数据库里的表或文件系统的文件夹
分区(Partition):
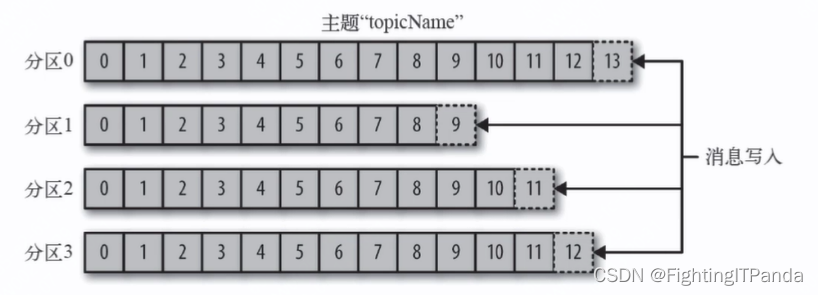
topic物理上的分组,就是把一个主题下的消息分散存储
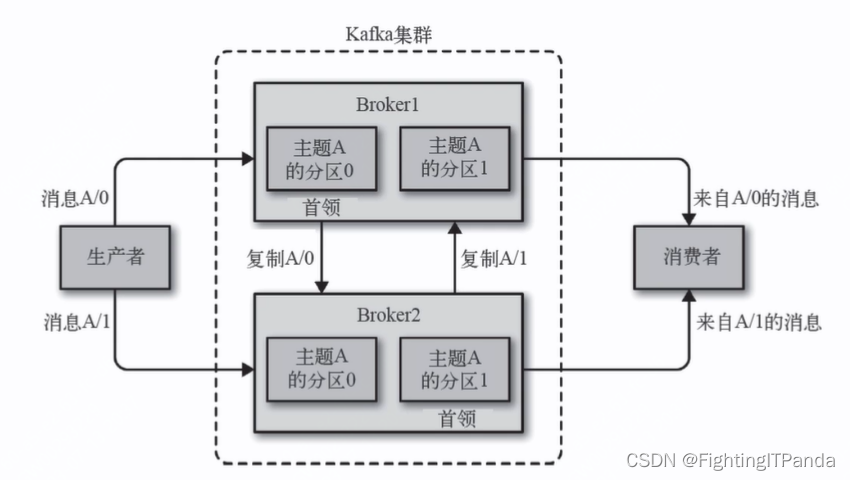
通常一个topic下的分区分散在kafka集群的不同实例(broker)上,producer向一个topic发送消息会发送给不同分区中,这样消息就可以实现并行发送与处理,增加吞吐量
当一台机器能力不足时,可以通过添加机器横向扩展broker,在新的机器上创建分区,这样就可以实现无限水平扩展
一个主题可以有多个分区,可以横向扩展
Kafka 通过分区来实现数据冗余和伸缩性
消息顺序写入分区,每个分区时一个有序队列,kafka不保证跨分区消息有序
片段(Segment): 每个分区物理上由多个segment组成,实际存储消息的物理文件,一个片段默认大小为1GB,可以通过配置文件修改,当消息追加到1GB大小后,会创建新的segment文件
一个segment包含3个文件,命名规则:每个segment文件最后一条消息offset的值,没有数字用0补充
00000000000000000000.index 索引文件
00000000000000000000.log 数据文件,实际存储消息数据的文件,二进制格式
00000000000000000000.timeindex 基于消息日期的索引文件 (根据日期或者时间查找消息)
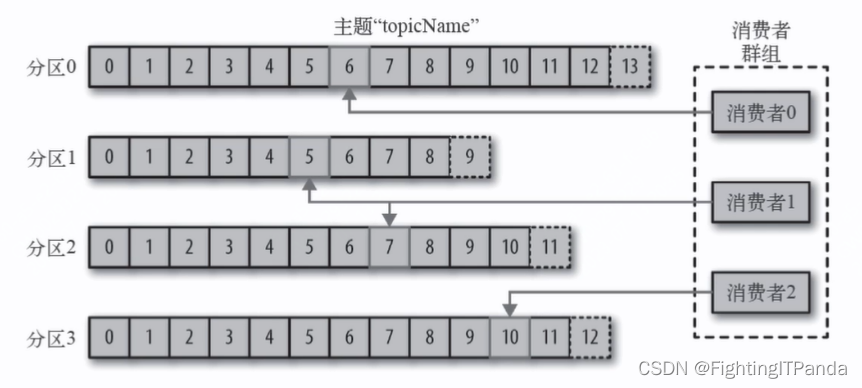
消费者组:
消费者组保证每一个分区消息只被消费者组内一个消费者消费
broker:
每个broker就是kafka集群一个实例,一个节点,一台独立的服务器
broker 接收来自producer的message,为message设置offset,提交消息到磁盘保存
broker为consumer提供服务,对consumer读取分区消息的请求做出响应
单个broker可以处理多个分区、每秒百万级吞吐量
集群:















 3533
3533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









