







Spark笔记
参考资料:
- Spark中文指南(入门篇)-Spark编程模型(一)
- 适合小白入门Spark的全面教程
- Spark教程
- Spark修炼之道
- spark入门介绍(菜鸟必看)
- Spark学习总结(一)
- Spark(一): 基本架构及原理
简介
Spark是一个用来实现快速而通用的集群计算的平台。扩展了广泛使用的MapReduce计算模型,而且高效地支持更多的计算模式,包括交互式查询和流处理。
特点
与Hadoop和Storm等其他大数据和MapReduce技术相比,Spark有如下优势:
-
支持多种数据源。Spark提供了一个全面、统一的框架用于管理各种有着不同性质(文本数据、图表数据等)的数据集和数据源(批量数据或实时的流数据)的大数据处理的需求。
-
速度。Spark可以将Hadoop集群中的应用在内存中的运行速度提升100倍,甚至能够将应用在磁盘上的运行速度提升10倍。Spark使用分区管理数据,这些分区有助于以最小的网络流量并行化处理分布式数据。
-
支持多语言。Spark让开发者可以快速的用Java、Scala或Python编写程序。它本身自带了一个超过80个高阶操作符集合。而且还可以用它在shell中以交互式地查询数据。
-
高级分析。除了Map和Reduce操作之外,它还支持SQL查询,流数据,机器学习和图表数据处理。开发者可以在一个数据管道用例中单独使用某一能力或者将这些能力结合在一起使用。
-
延迟计算和实时计算。Spark允许程序开发者使用有向无环图(DAG)开发复杂的多步数据管道。而且还支持跨有向无环图的内存数据共享,以便不同的作业可以共同处理同一个数据。
Spark生态圈

-
Spark Core
Spark Core是大规模并行和分布式数据处理的基础引擎。 核心是分布式执行引擎,Java,Scala和Python API为分布式ETL应用程序开发提供了一个平台。 此外,在核心上构建的其他库允许用于流式传输,SQL和机器学习的各种工作负载。 它负责:
-
内存管理和故障恢复
-
在群集上调度,分发和监视作业
-
与存储系统交互
-
-
Spark SQL
Spark SQL用于对结构化数据进行处理,它提供了DataFrame的抽象,作为分布式平台数据查询引擎,可以在此组件上构建大数据仓库。
DataFrame是一个分布式数据集,在概念上类似于传统数据库的表结构,数据被组织成命名的列,DataFrame的数据源可以是结构化的数据文件,也可以是Hive中的表或外部数据库,也还可以以是现有的RDD。
弹性分布式数据集(RDD)是Spark的基本数据结构。 它是一个不可变的分布式对象集合。 RDD中的每个数据集被划分为逻辑分区,其可以在集群的不同节点上计算。 RDD可以包含任何类型的Python,Java或Scala对象,包括用户定义的类。
Data Source API提供了一种可插拔的机制,用于通过Spark SQL访问结构化数据。 Data Source API用于将结构化和半结构化数据读取并存储到Spark SQL中。 数据源不仅仅是简单的管道,可以转换数据并将其拉入Spark。
-
Spark Streaming
Spark Streaming用于进行实时流数据的处理,它具有高扩展、高吞吐率及容错机制,数据来源可以是 Kafka, Flume, Twitter, ZeroMQ, Kinesis或TCP,其操作依赖于discretized stream(DStream),Dstream可以看作是多个有序的RDD组成,因此它也只通过map, reduce, join and window等操作便可完成实时数据处理,另外一个非常重要的点便是,Spark Streaming可以与Spark MLlib、Graphx等结合起来使用,功能十分强大,似乎无所不能。
-
Spark Machine Learning
Spark集成了MLLib库,其分布式数据结构也是基于RDD的,与其它组件能够互通,极大地降低了机器学习的门槛,特别是分布式环境下的机器学习。目前Spark MLlib支持下列几种机器学习算法:
(1) classification(分类)与 regression(回归)
目前实现的算法主要有:linear models (SVMs, logistic regression, linear regression)、naive Bayes(朴素贝叶斯)、decision trees(决策树)、ensembles of trees (Random Forests and Gradient-Boosted Trees)(组合模型树)、isotonic regression(保序回归)
(2) clustering(聚类)
目前实现的算法有:k-means、Gaussian mixture、power iteration clustering (PIC)、latent Dirichlet allocation (LDA)、streaming k-means
(3) collaborative filtering(协同过滤)
目前实现的算法只有:alternating least squares (ALS)
(4) dimensionality reduction(特征降维)
singular value decomposition (奇异值分解,SVD)
principal component analysis (主成分分析,PCA)除上述机器学习算法之外,还包括一些统计相关算法、特征提取及数值计算等算法。Spark 从1.2版本之后,机器学习库作了比较大的发动,Spark机器学习分为两个包,分别是mllib和ml,ML把整体机器学习过程抽象成Pipeline(流水线),避免机器学习工程师在训练模型之前花费大量时间在特征抽取、转换等准备工作上。
-
Spark GraphX
Graphx是Spark专门用来进行分布式图计算,Graph的抽象也是通过扩展Spark RDD实现,提供subgraph, joinVertices及aggregateMessages等基础的图操作。
-
SparkR
R语言在数据分析领域内应用十分广泛,但以前只能在单机环境上使用,Spark R的出现使得R摆脱单机运行的命运,将大量的数据工程师可以以非常小的成本进行分布式环境下的数据分析。 Spark R提供了RDD的API,R语言工程师可以通过R Shell进行任何的提交。

Spark重要概念
1、Spark体系结构

Spark体系架构包括如下三个主要组件:
-
数据存储
Spark用HDFS文件系统存储数据。它可用于存储任何兼容于Hadoop的数据源,包括HDFS,HBase,Cassandra等。
-
API
利用API,应用开发者可以用标准的API接口创建基于Spark的应用。Spark提供Scala,Java和Python三种程序设计语言的API。
-
管理框架
Spark既可以部署在一个单独的服务器也可以部署在像Mesos或YARN这样的分布式计算框架之上。
2、Spark运行模式
目前Spark的运行模式主要有以下几种:
local:主要用于开发调试Spark应用程序Standlone:利用Spark自带的资源管理与调度器运行Spark集群,采用Master/Slave结构,为解决单点故障,可以采用Xookeeper实现高可靠(High Availability, HA)Apache Mesos:运行在著名的Mesos资源管理框架基础之上,该集群运行模式将资源管理管理交给Mesos,Spark只负责运行任务调度和计算Hadoop YARN:集群运行在Yarn资源管理器上,资源管理交给YARN,Spark只负责进行任务调度和计算
Spark运行模式中Hadoop YARN的集群方式最为常用。
下图显示了Spark 如何使用Hadoop组件的三种方式来构建。

3、Spark组件(Components)
一个完整的Spark应用程序,在提交集群运行时,它涉及到如下图所示的组件:

每个Spark应用都由一个驱动器程序(drive program)来发起集群上的各种并行操作。驱动器程序包含应用的main函数,驱动器负责创建SparkContext,SparkContext可以与不同种类的集群资源管理器(Cluster Manager),例如Hadoop YARN,Mesos进行通信,获取到集群进行所需的资源后,SparkContext将
得到集群中工作节点(Worker Node)上对应的Executor(不同的Spark程序有不同的Executor,他们之间是相互独立的进程,Executor为应用程序提供分布式计算以及数据存储功能),之后SparkContext将应用程序代码发送到各Executor,最后将任务(Task)分配给executors执行
-
ClusterManager:在Standalone模式中即为Master节点(主节点),控制整个集群,监控Worker。在YARN中为ResourceManager
-
Worker:从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制。
-
Driver:运行Application的main()函数并创建SparkContect。
-
Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executor。
-
SparkContext:整个应用的上下文,控制应用的生命周期。
-
RDD:Spark的计算单元,一组RDD可形成执行的有向无环图RDD Graph。
-
DAG Scheduler:根据作业(Job)构建基于Stage的DAG,并提交Stage给TaskScheduler。
-
TaskScheduler:将任务(Task)分发给Executor。
-
SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。
SparkEnv内构建并包含如下一些重要组件的引用:
- MapOutPutTracker:负责Shuffle元信息的存储。
- BroadcastManager:负责广播变量的控制与元信息的存储。
- BlockManager:负责存储管理、创建和查找快。
- MetricsSystem:监控运行时性能指标信息。
- SparkConf:负责存储配置信息。

Job=多个stage,Stage=多个同种task, Task分为ShuffleMapTask和ResultTask,Dependency分为ShuffleDependency和NarrowDependency
4、Spark的整体运行流程
####(1)standalone运行流程
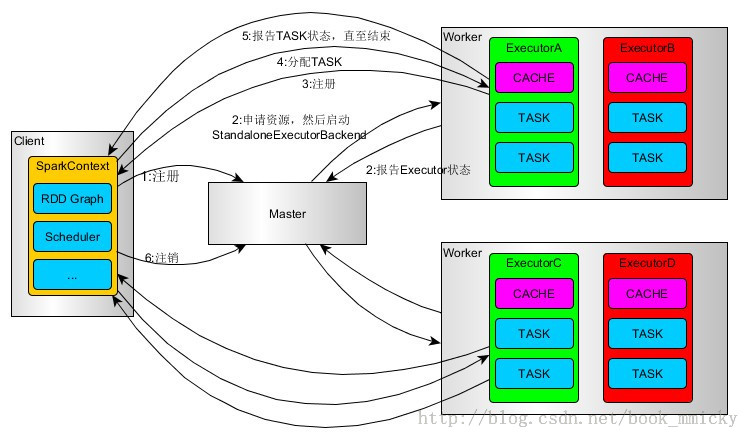
- Client提交应用。
- Master找到一个Worker启动Driver
- Driver向Master或者资源管理器申请资源,之后将应用转化为RDD Graph
- 再由DAGSchedule将RDD Graph转化为Stage的有向无环图提交给TaskSchedule。
- 再由TaskSchedule提交任务给Executor执行。
- 其它组件协同工作,确保整个应用顺利执行。
(2)Spark on Yarn流程

- 基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager。
- ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager。
- NodeManager启动SparkAppMaster。
- SparkAppMastere启动后初始化然后向ResourceManager申请资源。
- 申请到资源后,SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor。
- SparkExecutor向SparkAppMaster汇报并完成相应的任务。
- SparkClient会通过AppMaster获取作业运行状态。
5、弹性分布式数据集RDD
弹性分布式数据集(Resillient Distributed Dataset,RDD)是Spark的基本数据结构。它是对象的不可变的分布式集合,是可以并行进行操作元素的容错集合。在RDD中每个数据集被划分成逻辑分区,这可能是在群集中的不同节点上计算的。RDD可以包含任何类型,如:Python,Java,或者Scala的对象,包括用户定义的类。可以将RDD视作数据库中的一张表,其中可以保存任何类型的数据。
RDD适用于数据挖掘, 机器学习及图计算这些涉及到大量的迭代计算,基于内存能够极大地提升其在分布式环境下的执行效率的应用,不适用于诸如分布式爬虫等需要频繁更新共享状态的任务。
有两种方法来创建RDD:(1)从存储系统中创建;(2)从其它RDD中创建。从存储中创建有多种方式,可以是本地文件系统,也可以是分布式文件系统,还可以是内存中的数据。
RDD提供了容错性,可以自动从节点失败中恢复过来。即如果某个节点上的RDDpartition,因为节点故障,导致数据丢了,那么RDD会自动通过自己的数据来源重新计算该partition。这一切对使用者是透明的。
RDD的数据默认情况下存放在内存中的,但是在内存资源不足时,Spark会自动将RDD数据写入磁盘。(弹性)
RDD在内存中处理运算。这意味着,它存储存储器的状态作为两端作业的对象以及对象在那些作业之间是可共享的。在存储器数据共享比网络和磁盘快10到100倍。
RDD是不可变的。你可以用变换(Transformation)修改RDD,但是这个变换所返回的是一个全新的RDD,而原有的RDD仍然保持不变。
RDD支持两种类型的操作:
- 变换(Transformation)
- 行动(Action)
变换:变换的返回值是一个新的RDD集合,而不是单个值。调用一个变换方法,不会有任何求值计算,它只获取一个RDD作为参数,然后返回一个新的RDD。
变换函数包括:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,pipe和coalesce。
行动:行动操作计算并返回一个新的值。当在一个RDD对象上调用行动函数时,会在这一时刻计算全部的数据处理查询并返回结果值。
行动操作包括:reduce,collect,count,first,take,countByKey以及foreach。
安装部署
1、安装Java
安装Java是安装Spark强制性的事情之一。
2、安装Scala
Scala语言是来实现Spark。
mac下在终端输入brew install scala就可以安装Scala。
编辑/etc/profile来设置Scala的PATH。
export PATH=$PATH:/usr/local/Cellar/scala/2.12.8/bin
source /etc/profile使Scala环境变量生效。
验证Scala 安装:$scala -version
3、安装Spark
在官网下载并解压Spark压缩包。
编辑/etc/profile来设置Spark的PATH。
export PATH=$PATH:/usr/local/Cellar/spark/bin
source /etc/profile使Spark环境变量生效。
验证Spark安装:$spark-shell
编程
1、创建RDD
进行Spark核心编程的第一步就是创建一个初始的RDD。该RDD,通常就代表和包含了Spark应用程序的输入源数据。然后通过Spark Core提供的transformation,对该RDD进行转换,来获取其他的RDD。
Spark Core提供了三种创建RDD的方式:
-
使用程序中的集合创建RDD(主要用于测试)
List<Integer> numbers = Arrays.asList(1,2,3,4,5,6,7,8,9,10); JavaRDD<Integer> numbersRDD = sc.parallelize(numbers); -
使用本地文件创建RDD(主要用于临时性处理有大量数据的文件)
SparkSession spark = SparkSession.builder().master("local").appName("WordCountLocal").getOrCreate(); JavaRDD<String> lines = spark.read().textFile("D:\\Users\\Administrator\\Desktop\\spark.txt").javaRDD(); -
使用HDFS文件创建RDD(生产环境的常用方式)
SparkSession spark = SparkSession.builder().appName("WordCountCluster").getOrCreate(); JavaRDD<String> lines = spark.read().textFile("hdfs://h0:9000/spark.txt").javaRDD();使用HDFS文件创建RDD对比使用本地文件创建RDD,需要修改的,只有两个地方:
第一,将SparkSession对象的master(“local”)方法去掉
第二,我们针对的不是本地文件了,修改为hadoop hdfs上的真正的存储大数据的文件
2、操作RDD
Spark支持两种RDD操作:transformation和action。
transformation操作
transformation操作会针对已有的RDD创建一个新的RDD。transformation具有lazy特性,即transformation不会触发spark程序的执行,它们只是记录了对RDD所做的操作,不会自发的执行。只有执行了一个action,之前的所有transformation才会执行。
| 操作 | 含义 |
|---|---|
| map(func) | 将RDD中的每个元素传人自定义函数,获取一个新的元素,然后用新的元素组成新的RDD |
| filter(func) | 对RDD中每个元素进行判断,如果返回true则保留,返回false则剔除 |
| flatMap(func) | 类似映射,但每个输入项目可以被映射到0以上输出项目(所以func应返回seq而不是单一的项目) |
| mapPartitions(func) | 类似映射,只不过是单独的每个分区(块)上运行RDD,因此 func 的类型必须是Iterator<T> => Iterator<U> 对类型T在RDD上运行时 |
| mapPartitionsWithIndex(func) | 类似映射分区,而且还提供func 来表示分区的索引的整数值,因此 func 必须是类型 (Int, Iterator<T>) =>Iterator<U> 当类型T在RDD上运行时 |
| sample(withReplacement, fraction, seed) | 采样数据的一小部分,有或没有更换,利用给定的随机数发生器的种子 |
| union(otherDataset) | 返回一个新的数据集,其中包含源数据和参数元素的结合 |
| intersection(otherDataset) | 返回包含在源数据和参数元素的新RDD交集 |
| distinct([numTasks]) | 返回一个新的数据集包含源数据集的不同元素 |
| groupByKey([numTasks]) | 当调用(K,V)数据集,返回(K, Iterable) 对数据集。numTasks指定task数量,该参数是可选的 |
| reduceByKey(func, [numTasks]) | 对每个key对应的value进行reduce操作 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | 对PairRDD中相同Key的值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。 |
| sortByKey([ascending], [numTasks]) | 对每个key对应的value进行排序操作 |
| join(otherDataset, [numTasks]) | 对两个包含<key,value>对的RDD进行join操作,每个keyjoin上的pair,都会传入自定义函数进行处理 |
| cogroup(otherDataset, [numTasks]) | 同join,但是每个key对应的Iterable都会传入自定义函数进行处理 |
| cartesian(otherDataset) | 求两个RDD数据集间的笛卡尔积。当上调用类型T和U的数据集,返回(T,U)对数据集(所有元素对) |
| pipe(command, [envVars]) | RDD通过shell命令每个分区,例如:一个Perl或bash脚本。RDD元素被写入到进程的标准输入和线路输出,标准输出形式返回一个字符串RDD |
| coalesce(numPartitions) | 减少RDD到numPartitions分区的数量。过滤大型数据集后,更高效地运行的操作 |
| repartition(numPartitions) | 打乱RDD数据随机创造更多或更少的分区,并在它们之间平衡。功能与coalesce函数相同,实质上它调用的就是coalesce函数,只不是shuffle = true,意味着可能会导致大量的网络开销。 |
| repartitionAndSortWithinPartitions(partitioner) | repartition函数的变种,与repartition函数不同的是,repartitionAndSortWithinPartitions在给定的partitioner内部进行排序,性能比repartition要高。 |
import org.apache.spark.SparkContext._
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount{
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: SparkWordCount <inputfile> <outputfile>")
System.exit(1)
}
val conf = new SparkConf().setAppName("SparkWordCount").setMaster("local")
val sc = new SparkContext(conf)
val data = sc.parallelize(List((1,3),(1,2),(1, 4),(2,3),(2,4)))
def seqOp(a:Int, b:Int) : Int ={
println("seq: " + a + "\t " + b)
math.max(a,b)
}
def combineOp(a:Int, b:Int) : Int ={
println("comb: " + a + "\t " + b)
a + b
}
val localIterator=data.aggregateByKey(1)(seqOp, combineOp).toLocalIterator
for(i<-localIterator) println(i)
sc.stop()
}
}
action操作
action操作主要对RDD进行最后的操作,比如遍历,reduce,保存到文件等,并可以返回结果给Driver程序。action操作执行,会触发一个spark job的运行,从而触发这个action之前所有的transformation的执行,这是action的特性。
| 操作 | 含义 |
|---|---|
| reduce(func:(T,T)=>T) | 将RDD中的所有元素进行聚合操作。第一个和第二个元素聚合,值与第三个元素聚合,值与第四个元素聚合,以此类推。 reduce采样累加或关联操作减少RDD中元素的数量。 |
| collect() | 返回数据集的所有作为数组在驱动程序的元素。这是一个过滤器或其它操作之后返回数据的一个足够小的子集 |
| count() | 返回该数据集的元素数 |
| first() | 返回的数据集的第一个元素(类似于使用(1)) |
| take(n) | 返回与该数据集的前n个元素的阵列。 |
| takeSample (withReplacement,num, [seed]) | 返回数组的数据集num个元素,有或没有更换随机抽样,预指定的随机数发生器的种子可选 |
| takeOrdered(n, [ordering]) | 返回RDD使用或者按其自然顺序或自定义比较的前第n个元素 |
| saveAsTextFile(path) | 写入数据集是一个文本文件中的元素(或一组文本文件),在给定的目录的本地文件系统,HDFS或任何其他的Hadoop支持的文件系统。Spark调用每个元素的 toString,将其转换为文件中的文本行 |
| saveAsSequenceFile(path) (Java and Scala) | 写入数据集,为Hadoop SequenceFile元素在给定的路径写入在本地文件系统,HDFS或任何其他Hadoop支持的文件系统。 这是适用于实现Hadoop可写接口RDDS的键 - 值对。在Scala中,它也可以在属于隐式转换为可写(Spark包括转换为基本类型,如 Int, Double, String 等等)类型。 |
| saveAsObjectFile(path) (Java and Scala) | 写入数据集的内容使用Java序列化为一个简单的格式,然后可以使用SparkContext.objectFile()加载。 |
| countByKey() | 对每个key对应的值进行count计数。仅适用于RDDS的类型 (K, V)。 返回(K, Int)对与每个键的次数的一个HashMap。 |
| foreach(func) | 数据集的每个元素上运行函数func。 |
RDD持久化
要持久化一个RDD,只要调用其cache()或者persist()方法即可。在该RDD第一次被计算出来时,就会直接缓存在每个节点中。但是cache()或者persist()的使用是有规则的,必须在transformation或者textFile等创建了一个RDD之后,直接连续调用cache()或persist()才可以。
如果你先创建一个RDD,然后单独另起一行执行cache()或persist()方法,是没有用的,而且会报错,大量的文件会丢失。
val lines = spark.read.textFile("hdfs://h0:9000/spark.txt").persist()
Spark提供的多种持久化级别,主要是为了在CPU和内存消耗之间进行取舍。
通用的持久化级别的选择建议:
-
优先使用MEMORY_ONLY,如果可以缓存所有数据的话,那么就使用这种策略。因为纯内存速度最快,而且没有序列化,不需要消耗CPU进行反序列化操作。
-
如果MEMORY_ONLY策略,无法存储所有数据的话,那么使用MEMORY_ONLY_SER,将数据进行序列化进行存储,纯内存操作还是非常快,只是要消耗CPU进行反序列化。
-
如果需要进行快速的失败恢复,那么就选择带后缀为_2的策略,进行数据的备份,这样在失败时,就不需要重新计算了。
-
能不使用DISK相关的策略,就不用使用,有的时候,从磁盘读取数据,还不如重新计算一次。
共享变量
Spark提供了两种共享变量:Broadcast Variable(广播变量)和[Accumulator](累加变量)。用以提升集群环境中的Spark程序运行效率。
BroadcastVariable会将使用到的变量,仅仅为每个节点拷贝一份,更大的用处是优化性能,减少网络传输以及内存消耗。广播变量是只读的。
val factor = 3
val broadcastVars = sc.broadcast(factor);
val numberList = Array(1,2,3,4,5)
val number = sc.parallelize(numberList).map( num => num * broadcastVars.value) //广播变量读值broadcastVars.value
Accumulator则可以让多个task共同操作一份变量,主要可以进行累加操作。task只能对Accumulator进行累加操作,不能读取它的值。只有Driver程序可以读取Accumulator的值。
val numberList = Array(1,2,3,4,5)
val numberRDD = sc.parallelize(numberList,1)
val sum = sc.accumulator(0)
numberRDD.foreach{m => sum += m}
3、实战
小案例实战1
案例需求:
1、对文本文件内的每个单词都统计出其出现的次数。
2、按照每个单词出现次数的数量,降序排序。
步骤:
- 创建RDD
- 将文本进行拆分 (flatMap)
- 将拆分后的单词进行统计 (mapToPair,reduceByKey)
- 反转键值对 (mapToPair)
- 按键升序排序 (sortedByKey)
- 再次反转键值对 (mapToPair)
- 打印输出(foreach)
Java版本jdk1.8以下
public class SortWordCount {
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf().setAppName("SortWordCount").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 创建lines RDD
JavaRDD<String> lines = sc.textFile("D:\\Users\\Administrator\\Desktop\\spark.txt");
// 将文本分割成单词RDD
JavaRDD<String> words = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//将单词RDD转换为(单词,1)键值对RDD
JavaPairRDD<String,Integer> wordPair = words.mapToPair(new PairFunction<String, String,Integer>() {
@Override
public Tuple2<String,Integer> call(String s) throws Exception {
return new Tuple2<String,Integer>(s,1);
}
});
//对wordPair 进行按键计数
JavaPairRDD<String,Integer> wordCount = wordPair.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer integer, Integer integer2) throws Exception {
return integer +integer2;
}
});
// 到这里为止,就得到了每个单词出现的次数
// 我们的新需求,是要按照每个单词出现次数的顺序,降序排序
// wordCounts RDD内的元素是这种格式:(spark, 3) (hadoop, 2)
// 因此我们需要将RDD转换成(3, spark) (2, hadoop)的这种格式,才能根据单词出现次数进行排序
// 进行key-value的反转映射
JavaPairRDD<Integer,String> countWord = wordCount.mapToPair(new PairFunction<Tuple2<String, Integer>, Integer, String>() {
@Override
public Tuple2<Integer, String> call(Tuple2<String, Integer> s) throws Exception {
return new Tuple2<Integer, String>(s._2,s._1);
}
});
// 按照key进行排序
JavaPairRDD<Integer, String> sortedCountWords = countWord.sortByKey(false);
// 再次将value-key进行反转映射
JavaPairRDD<String,Integer> sortedWordCount = sortedCountWords.mapToPair(new PairFunction<Tuple2<Integer, String>, String, Integer>() {
@Override
public Tuple2<String, Integer> call(Tuple2<Integer, String> s) throws Exception {
return new Tuple2<String, Integer>(s._2,s._1);
}
});
// 到此为止,我们获得了按照单词出现次数排序后的单词计数
// 打印出来
sortedWordCount.foreach(new VoidFunction<Tuple2<String, Integer>>() {
@Override
public void call(Tuple2<String, Integer> s) throws Exception {
System.out.println("word \""+s._1+"\" appears "+ s._2+" times.");
}
});
sc.close();
}
}
Java版本jdk1.8
可以使用lambda表达式,简化代码:
public class SortWordCount {
public static void main(String[] args) throws Exception {
SparkConf conf = new SparkConf().setAppName("SortWordCount").setMaster("local");
JavaSparkContext sc = new JavaSparkContext(conf);
// 创建lines RDD
JavaRDD<String> lines = sc.textFile("D:\\Users\\Administrator\\Desktop\\spark.txt");
JavaRDD<String> words = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator());
JavaPairRDD<String,Integer> wordPair = words.mapToPair(word -> new Tuple2<>(word,1));
JavaPairRDD<String,Integer> wordCount = wordPair.reduceByKey((a,b) ->(a+b));
JavaPairRDD<Integer,String> countWord = wordCount.mapToPair(word -> new Tuple2<>(word._2,word._1));
JavaPairRDD<Integer,String> sortedCountWord = countWord.sortByKey(false);
JavaPairRDD<String,Integer> sortedWordCount = sortedCountWord.mapToPair(word -> new Tuple2<>(word._2,word._1));
sortedWordCount.foreach(s->System.out.println("word \""+s._1+"\" appears "+ s._2+" times."));
sc.close();
}
}
scala版本
由于spark2 有了统一切入口SparkSession,在这里就使用了SparkSession。
package cn.spark.study.core
import org.apache.spark.sql.SparkSession
object SortWordCount {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SortWordCount").master("local").getOrCreate()
val lines = spark.sparkContext.textFile("D:\\Users\\Administrator\\Desktop\\spark.txt")
val words = lines.flatMap{line => line.split(" ")}
val wordCounts = words.map{word => (word,1)}.reduceByKey(_ + _)
val countWord = wordCounts.map{word =>(word._2,word._1)}
val sortedCountWord = countWord.sortByKey(false)
val sortedWordCount = sortedCountWord.map{word => (word._2, word._1)}
sortedWordCount.foreach(s=>
{
println("word \""+s._1+ "\" appears "+s._2+" times.")
})
spark.stop()
}
}

小案例实战2
需求:
1、按照文件中的第一列排序。
2、如果第一列相同,则按照第二列排序。
实现步骤:
- 实现自定义的key,要实现Ordered接口和Serializable接口,在key中实现自己对多个列的排序算法
- 将包含文本的RDD,映射成key为自定义key,value为文本的JavaPairRDD(map)
- 使用sortByKey算子按照自定义的key进行排序(sortByKey)
- 再次映射,剔除自定义的key,只保留文本行(map)
- 打印输出(foreach)
这里主要用scala编写
class SecondSortKey(val first:Int,val second:Int) extends Ordered[SecondSortKey] with Serializable{
override def compare(that: SecondSortKey): Int = {
if(this.first - that.first !=0){
this.first-that.first
}else{
this.second-that.second
}
}
}
object SecondSort {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SecondSort").master("local").getOrCreate()
val lines = spark.sparkContext.textFile("D:\\sort.txt")
val pairs = lines.map{line => (
new SecondSortKey(line.split(" ")(0).toInt,line.split(" ")(1).toInt),line
)}
val sortedParis = pairs.sortByKey()
val sortedLines = sortedParis.map(pairs => pairs._2)
sortedLines.foreach(s => println(s))
spark.stop()
}
}

小案例实战3
需求:
对每个班级内的学生成绩,取出前3名。(分组取topn)
实现步骤:
-
创建初始RDD
-
对初始RDD的文本行按空格分割,映射为key-value键值对
-
对键值对按键分组
-
获取分组后每组前3的成绩:
- 遍历每组,获取每组的成绩
- 将一组成绩转换成一个数组缓冲
- 将数组缓冲按从大到小排序
- 对排序后的数组缓冲取其前三
-
打印输出
以下是使用scala实现:
object GroupTop3 {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("GroupTop3").master("local").getOrCreate()
//创建初始RDD
val lines = spark.sparkContext.textFile("D:\\score.txt")
//对初始RDD的文本行按空格分割,映射为key-value键值对
val pairs = lines.map(line => (line.split(" ")(0), line.split(" ")(1).toInt))
//对pairs键值对按键分组
val groupedPairs = pairs.groupByKey()
//获取分组后每组前3的成绩
val top3Score = groupedPairs.map(classScores => {
var className = classScores._1
//获取每组的成绩,将其转换成一个数组缓冲,并按从大到小排序,取其前三
var top3 = classScores._2.toBuffer.sortWith(_>_).take(3)
Tuple2(className,top3)
})
top3Score.foreach(m => {
println(m._1)
for(s <- m._2) println(s)
println("------------------")
})
}
}

任务提交
在运行Spar应用程序时,会将spark应用程序打包后使用spark-submit脚本提交到Spark中运行,执行提交命令如下:
root@sparkmaster:/hadoopLearning/spark-1.5.0-bin-hadoop2.4/bin#
./spark-submit --master spark://sparkmaster:7077
--class SparkWordCount --executor-memory 1g
/root/IdeaProjects/SparkWordCount/out/artifacts/SparkWord
Count_jar/SparkWordCount.jar hdfs://ns1/README.md
hdfs://ns1/SparkWordCountResult
Spark几种不同的任务提交相关脚本:spark-shell、spark-sql实现方式都是通过调用spark-submit脚本来实现的,而spark-submit又是通过spark-class脚本来实现的,spark-class脚本最终执行org.apache.spark.launcher.Main,作为整个Spark程序的主入口















 135
135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









