







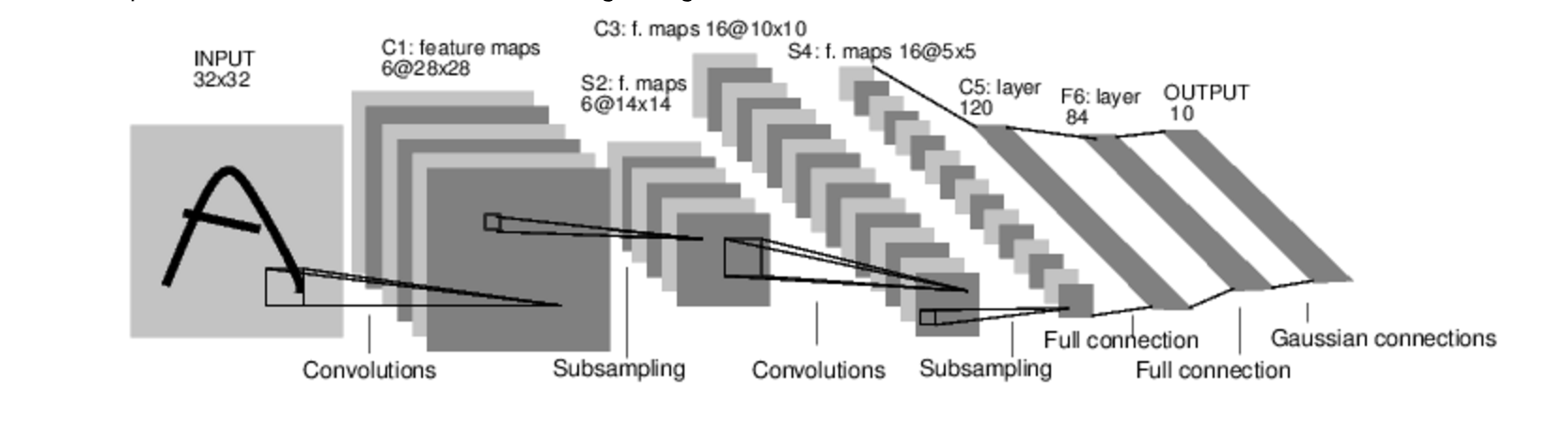
Here is the image stoled from guide of torch: https://github.com/soumith/cvpr2015/blob/master/Deep%20Learning%20with%20Torch.ipynb
First, we must know what is convolution.
Here is a good example I quoted from http://www.cnblogs.com/ronny/p/ann_03.html:

To summary this, the kernel of convolution define the weights of each pixels beside this pixel contributes to the convolution result of this pixel. Different kernel will extract different feature of the image.
Feature map means the convolution result of a particular kernel. In a conventional convolution neural network, it will have several kernels in each convolution layer to extract different features.
After we get a feature map, we need to sub-sample each feature map because this can help to decrease the amount of data we need to process. There are many kinds of sub-sampling: mean-pooling, max-pooling and stochastic-pooling. Mean-pooling has two tuneable parameters which are trainable parameter and trainable bia. For example, we take the data a window of 2x2 and add them together, then we multiply the result with the trainable parameter and add with the trainable bia. '结果通过sigmoid函数计算。可训练系数和偏置控制着sigmoid函数的非线性程度。如果系数比较小,那么运算近似于线性运算,亚采样相当于模糊图像。如果系数比较大,根据偏置的大小亚采样可以被看成是有噪声的“或”运算或者有噪声的“与”运算。'[1]
The second kind of sub-sampling is max-pooling. Max-pooling has no learnable parameter. Because what it is doing is to return the maximum pixel of each window. The last kind is stochastic-pooling. First, it will give each pixel a possibility according to their value and calculate the expectation. 在平均意义上,与mean-pooling近似,在局部意义上,则服从max-pooling的准则。[2]
In general, sub-sampling can perform as a process of extraction feature.
Look at the image I posted at the beginning, we can see that the deeper convolution layer will have more convolution kernel. This is because the data we need to process is less and less, we can extract more features as we want. 这里需要注意的一点是:C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合(这个做法也并不是唯一的)。(看到没有,这里是组合,就像之前聊到的人的视觉系统一样,底层的结构构成上层更抽象的结构,例如边缘构成形状或者目标的部分)。 刚才说C3中每个特征图由S2中所有6个或者几个特征map组合而成。为什么不把S2中的每个特征图连接到每个C3的特征图呢?原因有2点。第一,不完全的连接机制将连接的数量保持在合理的范围内。第二,也是最重要的,其破坏了网络的对称性。由于不同的特征图有不同的输入,所以迫使他们抽取不同的特征(希望是互补的)。[1]
There are information about C5 and F6 and the RBF output layer, please turn to [1].
Here is some information about soft-max:
Soft-max regression is kind of logistic regression. Typical logistic regression is for 0 or 1 two results. However, for some sceneries, we need more than two classes regression.
Here is some content I quoted from http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92

Reference:
[1] http://blog.csdn.net/nan355655600/article/details/17690029
[2] https://www.zhihu.com/question/23437871/answer/24696910 张腾 知乎
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









