






目录
问题 A: 4201 凯撒密码
题目描述
Julius Caesar 生活在充满危险和阴谋的年代。为了生存,他首次发明了密码,用于军队的消息传递。假设你是Caesar 军团中的一名军官,需要把Caesar 发送的消息破译出来、并提供给你的将军。消息加密的办法是:对消息原文中的每个字母,分别用该字母之后的第5个字母替换(例如:消息原文中的每个字母A都分别替换成字母F),其他字符不 变,并且消息原文的所有字母都是大写的。
密码字母:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
原文字母:V W X Y Z A B C D E F G H I J K L M N O P Q R S T U
输入
最多不超过100个数据集组成。每个数据集由3部分组成:
起始行:START
密码消息:由1到200个字符组成一行,表示Caesar发出的一条消息
结束行:END
输出
每个数据集对应一行,是Caesar 的原始消息。
样例输入
START
NS BFW, JAJSYX TK NRUTWYFSHJ FWJ YMJ WJXZQY TK YWNANFQ HFZXJX
END
START
N BTZQI WFYMJW GJ KNWXY NS F QNYYQJ NGJWNFS ANQQFLJ YMFS XJHTSI NS WTRJ
END
START
IFSLJW PSTBX KZQQ BJQQ YMFY HFJXFW NX RTWJ IFSLJWTZX YMFS MJ
END
ENDOFINPUT
样例输出
IN WAR, EVENTS OF IMPORTANCE ARE THE RESULT OF TRIVIAL CAUSES
I WOULD RATHER BE FIRST IN A LITTLE IBERIAN VILLAGE THAN SECOND IN ROME
DANGER KNOWS FULL WELL THAT CAESAR IS MORE DANGEROUS THAN HE
解析
思路梳理
加密方法是将消息原文的每个字母用该字母之后的第5个字母替换,且将A作为原文V之后的第5个字母,以此类推到Z->E。
考虑到ASCII码中大写字母是连续的,由此可以简单的将原文字符分为原文字符-密文字符='F'-'A'=5和原文字符-密文字符='A'-'V'=-21的这两种情况。再分别进行解译即可。
细节提示
注意到起始行(START)、结束行(END)、终止行(ENDOFINPUT)均独占一行,密文内容包含空格、标点符号等非大写字母内容且独占一行,考虑使用getline()函数读取整行来解译。
getline()函数的效果相当于c语言中的gets()和f_get()函数,getline()函数读取整行,以回车为判断读取结束标志,并丢弃回车符号。听说学校oj不支持gets()函数,本人也还没试过,假如读者发现出现错误可以试试f_gets(),注意f_gets()和gets()使用方法有些区别。
scanf()函数、cin函数读取到空格、回车等就结束,考虑到起始行START、结束行END、终止行ENDOFINPUT等单词也有可能在密文中,判断不便,建议还是使用整行读取。
.compare()相当于c语言中的strcmp()函数。
参考代码
#include<bits/stdc++.h>
using namespace std;
int main(){
string st;
while(1){
getline(cin, st);
if (st.compare("ENDOFINPUT") == 0)
break;
else if (st.compare("START") == 0)
continue;
else if (st.compare("END") == 0)
continue;
else{
for (int i = 0; i < st.length();i++){
if(st[i]>='F'&&st[i]<='Z')
cout << char(st[i] + 'A' - 'F');
else if(st[i]>='A'&&st[i]<='E')
cout << char(st[i] + 'V' - 'A');
else
cout << st[i];
}
cout << endl;
}
}
return 0;
}问题 B: 4202 子串
题目描述
现在有一些由英文字符组成的大小写敏感的字符串,你的任务是找到一个最长的字符串x,使得对于已经给出的字符串中的任意一个y,x或者是y的子串,或者x中的字符反序之后得到的新字符串是y的子串。
输入
输入的第一行是一个整数t (1 <= t <= 10),t表示测试数据的数目。对于每一组测试数据,第一行是一个整数n (1 <= n <= 100),表示已经给出n个字符串。接下来n行,每行给出一个长度在1和100之间的字符串。
输出
对于每一组测试数据,输出一行,给出题目中要求的字符串x的长度。
样例输入
2
3
ABCD
BCDFF
BRCD
2
rose
orchid
样例输出
2
2
解析
思路梳理
寻找符合要求的最长子串,并输出子串的长度。
每组的字符串可能有多个,为减少运行时间,我们可以先找到测试组里最短的字符串,再从最短的这个字符串中截取子串(记为s0)。
从最长的子串开始判断,假如此时的子串s0可以在测试组中的所有字符串中找到,代表这时的子串s0就是目标子串,跳出所有循环并输出结果;假如子串s0在某个字符串中不能找到,代表此时的子串s0不是目标子串,跳出循环,改变子串内容再进行新一轮的判断。
改变子串内容时,先保证长度不变的情况下改变从原串截取的内容,如果该长度下的所有子串都不是目标子串再改变子串长度,以保证最后判断出的子串是最长的。
细节提示
将子串反序可以构造个简单的函数便于我们后续使用,也就是参考代码的这一部分
string re(string s){
char xs;
for (int i = 0; i < s.length() / 2; i++){
xs = s[i];
s[i] = s[s.length() - i - 1];
s[s.length() - i - 1] = xs;
}
return s;
}string的查找:.find()
find函数可以用于查找单个字符或者一个字符串是否在被查找字符串中出现,假如没有出现,它的返回值是string::npos可以利用这个来快速判断我们的子串是否被找到。如果出现了,它的返回值是找到的字符或字符串的第一个字符在被查找字符串的下标位置(也就是相当于数组的[]里的值)
字符串查找-----找到后返回首字母在字符串中的下标
string str="ABCDEF ABCDEF";
1. 查找一个字符串
cout << str.find("D") << endl;
结果是:3
2. 从下标为3开始找字符'D',返回找到的第一个D的下标
cout << str.find('D', 3) << endl;
结果是:3
3. 从下标为4开始找字符'D',返回找到的第一个D的下标
cout << str.find('D', 4) << endl;
结果是:10string的截取:.substr()
substr函数可以根据我们的需求截取字符串,它可以利用下标位置截取,也可以利用迭代器(相当于地址/指针)截取,使用方法较多,感兴趣可以另外学习。这里只简单介绍下标法的使用方法。
string s1("123456789");
string s2 = s1.substr(2, 4);
cout << s2 << endl;
结果:3456
参数2表示开始截取的位置,对应字符'3',参数4表示截取的字符串的长度。
参考代码
#include<bits/stdc++.h>
using namespace std;
string st[105];
string re(string s){
char xs;
for (int i = 0; i < s.length() / 2; i++){
xs = s[i];
s[i] = s[s.length() - i - 1];
s[s.length() - i - 1] = xs;
}
return s;
}
int main(){
int t;
cin >> t;
while(t--){
int n;
cin >> n;
int ni = n;
while(ni--)
cin >> st[ni];
string s0 = st[0];
ni = n;
while(ni--)
if(s0.length()>st[ni].length())
s0 = st[ni];
int len = 0;
int p;
for (int i = 0; i < s0.length();i++){
for (int j = s0.length() - i; j >0 ;j--){
int flag = 1;
ni = n;
while(ni--){
if(st[ni].find(s0.substr(i,j))==string::npos&&st[ni].find(re(s0.substr(i,j)))==string::npos){ // s0.substr(i,j)不是符合要求的子串
flag = 0;
break;
}
}
if(flag){
if(len<j){
p = i;
len = j;
}
break;
}
}
}
cout << len << endl;
}
return 0;
}问题 C: 4203 IBM减一
题目描述
你可能听说过Arthur C. Clarke的书“2001-太空奥德赛”,或者由Stanley Kubrick写的同名电影。书中描述的是一艘从地球飞往土星的太空船上发生的事情。长途飞行,船员都很疲劳,只有两个人是清醒的。飞船由智能电脑HAL控制的。但在飞行中,HAL操作变得越来越奇怪,甚至开始要杀死船上的船员。我们不告诉你故事的结局,你可以试着亲自去阅读。
电影上映后,大受欢迎。人们开始讨论“HAL”的名字真正的含义是什么。有人认为它可能是“启发式算法”的缩写。有人发现,如果把HAL中的每个字母都替换成字母表中其后的字母,就会得到“IBM”。
用这个方法也许能够找出更多的缩写词。请你编程帮忙找出这些单词。
输入
第1行为一个整数n,表示n个字符串。接下来的n行中,每行为一个不超过50大写字母的字符串。
输出
对输入文件中的每个字符串,先输出字符串的序号,如输出样例所示。最后输出变换后对应的字符串,即用字母表中后面的字母替换,其中‘Z’用‘A’替换。
每个测试数据之后,输出一个空行。
样例输入
2
HAL
SWERC
样例输出
String #1
IBMString #2
TXFSD
解析
思路梳理
这题比较简单,思路和问题A差不多,比问题A还简单一些。
细节提示
注意String #1中序号的迭代,以及测试数据后的空行。
参考代码
#include<bits/stdc++.h>
using namespace std;
int main(){
int n;
cin >> n;
int index = 1;
while(n--){
printf("String #%d\n", index);
index++;
string str;
cin >> str;
for (int i = 0; i < str.length();i++){
if(str[i]>='A'&&str[i]<'Z')
cout << char(str[i] + 1);
else if(str[i]=='Z')
cout << "A";
}
cout << endl
<< endl;
}
return 0;
}问题 D: 4204 W密码
题目描述
加密一条信息需要三个整数码, k1, k2 和 k3。字符[a-i] 组成一组, [j-r] 是第二组, 其它所有字符 ([s-z] 和下划线)组成第三组。 在信息中属于每组的字符将被循环地向左移动ki个位置。 每组中的字符只在自己组中的字符构成的串中移动。解密的过程就是每组中的字符在自己所在的组中循环地向右移动ki个位置。
例如对于信息 the_quick_brown_fox 以ki 分别为 2, 3 和 1进行加密。加密后变成 _icuo_bfnwhoq_kxert。下图显示了右旋解密的过程。
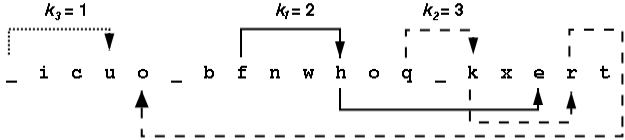
右旋解密示意图
观察在组[a-i]中的字符,我们发现{i,c,b,f,h,e}出现在信息中的位置为{2,3,7,8,11,17}。当k1=2右旋一次后, 上述位置中的字符变成{h,e,i,c,b,f}。下表显示了经过所有第一组字符旋转得到的中间字符串,然后是所有第二组,第三组旋转的中间字符串。在一组中变换字符将不影响其它组中字符的位置。 所有输入字符串中只包含小写字母和下划线( _ )。每个字符串的长度不超过80个字符。ki 是1-100之间的整数。
输入
输入包括一到多组数据。每个组前面一行包括三个整数 k1, k2 和 k3,后面是一行加密信息。输入的最后一行是由三个0组成的。
输出
对于每组加密数据,输出它加密前的字符串。
样例输入
2 3 1
_icuo_bfnwhoq_kxert
1 1 1
bcalmkyzx
3 7 4
wcb_mxfep_dorul_eov_qtkrhe_ozany_dgtoh_u_eji
2 4 3
cjvdksaltbmu
0 0 02
HAL
SWERC
样例输出
the_quick_brown_fox
abcklmxyz
the_quick_brown_fox_jumped_over_the_lazy_dog
ajsbktcludmv
解析
思路梳理
因为题目中将字符[a-i] 组成一组, [j-r] 是第二组, 其它所有字符 ([s-z] 和下划线)组成第三组且三组的转译是互不影响的,可以考虑按照分组规则取各组,然后遍历原字符串,按照原字符串的内容确定属于三组中的哪一组,再进行转译并直接输出转译结果。
细节提示
博主在代码中使用了vector<char> x1,x2,x3来储存三组,假如仍使用string来定义及输入、转译也是没问题的。
vector<char> x1, x2, x3;
for (int i = 0; i < str.length();i++){
if(str[i]>='a'&&str[i]<='i')
x1.push_back(str[i]);
if (str[i] >= 'j' && str[i] <= 'r')
x2.push_back(str[i]);
if ((str[i] >= 's' && str[i] <= 'z')||str[i]=='_')
x3.push_back(str[i]);
}这部分是读入字符串组,x1.push_back(str[i])是将字符st[i]加入到x1的最后。如果将x1定义为string型也可以使用.push_back(),用法相同,使用这个方法可以减少参数个数和代码长度。试想假如使用char x[100]定义了三个字符数组,一定还会使用到3个计数器,不过也可以尝试写成写成x1[i1++]=str[i]来简洁读入。
while(k1--){
x1.insert(x1.begin(), *(x1.end() - 1));
x1.pop_back();
}
while (k2--){
x2.insert(x2.begin(), *(x2.end() - 1));
x2.pop_back();
}
while (k3--){
x3.insert(x3.begin(), *(x3.end() - 1));
x3.pop_back();
}这部分就是根据k1,k2,k3的值来把原序的x1,x2,x3解译成想要的结果。
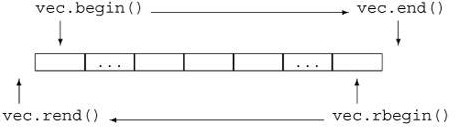
.insert()函数是插入函数, x1.insert(x1.begin(), *(x1.end() - 1));的意思是在x1的头部插入x1末尾的字符,x1.end()的返回值是最后一个字符的后一位的地址,所以要减一加*来得到最后一个字符。x1.begin()的返回值也是地址。
参考代码
#include<bits/stdc++.h>
using namespace std;
int main(){
int k1, k2, k3;
while(cin>>k1>>k2>>k3){
if(k1==0&&k2==0&&k3==0)
break;
string str;
cin >> str;
vector<char> x1, x2, x3;
for (int i = 0; i < str.length();i++){
if(str[i]>='a'&&str[i]<='i')
x1.push_back(str[i]);
if (str[i] >= 'j' && str[i] <= 'r')
x2.push_back(str[i]);
if ((str[i] >= 's' && str[i] <= 'z')||str[i]=='_')
x3.push_back(str[i]);
}
while(k1--){
x1.insert(x1.begin(), *(x1.end() - 1));
x1.pop_back();
}
while (k2--){
x2.insert(x2.begin(), *(x2.end() - 1));
x2.pop_back();
}
while (k3--){
x3.insert(x3.begin(), *(x3.end() - 1));
x3.pop_back();
}
int a = 0, b = 0, c = 0;
for (int i = 0; i < str.length();i++){
if(str[i]>='a'&&str[i]<='i'){
cout << x1[a];
a++;
}
else if (str[i] >= 'j' && str[i] <= 'r'){
cout << x2[b];
b++;
}
else if ((str[i] >= 's' && str[i] <= 'z')||str[i]=='_'){
cout << x3[c];
c++;
}
else
cout << str[i];
}
cout << endl;
}
return 0;
}
问题 E: 4205 字符长度编码
题目描述
你的任务是编程实现一个简单的字符长度编码方法。具体规则如下:
将任何由2~9个相同字符构成的序列用2个字符编码:第1个字符为数字2~9,表示序列长度,第2个字符为重复字符本身。超过9个字符的,先对前9个字符进行编码,然后再编码剩余的。
如果子序列中没有任何重复的字符,则用字符“1”开头,然后是子序列本身,最后再以字符“1”结束。若字符串中含有字符“1”,则用两个“1”替换。
输入
输入文件包含若干行,每行的字符都是大小写字母字符,数字字符,空格或标点符号,没有其他字符。
输出
对输入文件中的每行进行长度编码输出。
样例输入
AAAAAABCCCC
12344
样例输出
6A1B14C
11123124
解析
思路梳理
待补充
细节提示
待补充
参考代码
#include <bits/stdc++.h>
using namespace std;
string temp;
int rep(int idx){
int cnt = 0;
for (int j = idx; j < temp.length(); j++)
if (temp[j] == temp[idx])
cnt++;
else
break;
return cnt;
}
int main(){
string asw;
while (getline(cin, temp)){
asw = "";
for (int i = 0; i < temp.length();){
for (int j = i;; j++){
if (j >= temp.length()){
asw.push_back('1');
for (int k = i; k < temp.length(); k++)
if (temp[k] != '1')
asw.push_back(temp[k]);
else{
asw.push_back('1');
asw.push_back('1');
}
asw.push_back('1');
i = j;
break;
}
if (rep(j) != 1){
if (j - i >= 1){
asw.push_back('1');
for (int k = i; k <= j - 1; k++){
if (temp[k] != '1')
asw.push_back(temp[k]);
else{
asw.push_back('1');
asw.push_back('1');
}
}
asw.push_back('1');
i = j;
break;
}
else{
asw+=to_string(rep(j));
asw.push_back(temp[j]);
i = j + rep(j);
break;
}
}
}
}
cout << asw << '\n';
}
return 0;
}问题 F: 4207 英语到数字翻译
题目描述
给你一个或多个表示整数的英文单词,你的任务就是把这些英文单词表示的整数翻译成数字形式。数字的范围是从-999999999到+999999999。以下是可能出现的英文单词:
negative,zero,one,two,three,four,five,six,seven,eight,nine,ten,eleven,twelve,thirteen,fourteen,fifteen,sixteen,seventeen,eighteen,nineteen,twenty,thirty,forty,fifty, sixty,seventy,eighty,ninety,hundred,thousand,million
**原题题干有两个英文数字拼写错了(nini->nine,millon->million),实际测试仍然按照正确拼写方法
输入
输入包含多组测试数据。需要注意以下输入,负数前面用negative单词;当能用thousand表示时,就不用hundred来表示。例如,1500表示成one thousand five hundred,而不是fifteen hundred。
输出
输出翻译后的整数,占一行。
样例输入
six
negative seven hundred twenty nine
one million one hundred one
eight hundred fourteen thousand twenty two
样例输出
6
-729
1000101
814022
解析
思路梳理
笔者选择的方法是将所有英文数字转为数字并存成数组,再根据对应数组里的整数来计算出结果并输出。
细节提示
由于还是一行为一个数字,且每个数字是否有million位不确定,所以笔者采用的还是整行读取,再通过遍历输入的整行字符串来获得具体数字。注意提前定义一个string型一维数组(或者char型二维数组)来当做判断数字具体值的参考,同时要注意,我们需要在每个英文数字后增加一个空格' ' ,这里是考虑到后续代码是使用find函数来对比的,假如没有加空格,则在寻找如"six"时在"sixty"中的"six"也会当做查找成功,从而影响数字的读入。
string num[] = {"zero ", "one ", "two ", "three ", "four ", "five ", "six ", "seven ", "eight ", "nine ", "ten ", "eleven ", "twelve ", "thirteen ", "fourteen ", "fifteen ", "sixteen ", "seventeen ", "eighteen ", "nineteen ", "twenty ", "thirty ", "forty ", "fifty ", "sixty ", "seventy ", "eighty ", "ninety ", "hundred ", "thousand ", "million "};同时,因为每个英文数字后我们添加了空格,所以在整行读入英文数字后,我们要使用st.push_back(' ');在末尾加一个空格,以免无法读入最后一个数字。
可以对原字符串进行读入一个整数就删掉一个这个英文单词的方法来简化我们的读入,也就是让我们的每一次查找函数find都能是从开头处开始查找。
下方的.erase()函数是从起始下标0开始,删掉包含下标为0的一共st.find(' ')+1个长度的内容的意思。
st.erase(0, st.find(' ')+1);后面转成相应的整数的代码比较简单,就不赘述了。
参考代码
#include<bits/stdc++.h>
using namespace std;
string num[] = {"zero ", "one ", "two ", "three ", "four ", "five ", "six ", "seven ", "eight ", "nine ", "ten ", "eleven ", "twelve ", "thirteen ", "fourteen ", "fifteen ", "sixteen ", "seventeen ", "eighteen ", "nineteen ", "twenty ", "thirty ", "forty ", "fifty ", "sixty ", "seventy ", "eighty ", "ninety ", "hundred ", "thousand ", "million "};
int nx[20];
string word[20], wor;
int main(){
string st;
while(getline(cin,st)){
st.push_back(' ');
if(st.find("negative ")!=string::npos){
cout << "-";
st.erase(st.begin(), st.begin() + 9);
}
int i = 0;
while (st.find(' ')!=string::npos){
word[i++] = st.substr(0, st.find(' ')+1);
st.erase(0, st.find(' ')+1);
}
int index = i, k = 0;
i = 0;
for (; i < index;i++){
int j = 0;
while(word[i].find(num[j++])==string::npos){}
if(j>0&&j<22)
nx[k++] = j - 1;
else if(j>21&&j<30)
nx[k++] = (j - 19) * 10;
else if(j==30)
nx[k++] = 1000;
else if(j==31)
nx[k++] = 1000000;
}
int resx = 0, res = 0;
for (i = 0; i < k;i++){
if(nx[i]!=1000000&&nx[i]!=1000){
if(res!=0&&nx[i]==100)
res *= 100;
else
res += nx[i];
}
else if(nx[i]==1000000){
resx += res * 1000000;
res = 0;
}
else if(nx[i]==1000){
resx += res * 1000;
res = 0;
}
}
cout << resx + res << endl;
}
return 0;
}问题 G: 4209 字符串的幂
题目描述
给定两个字符串a和b,定义ab为两个字符串的联接。例如,a=“abc”,b=“def”,则ab=“abcdef”。若将字符串的联接看作乘法,则字符串的非负整数次幂可这样定义:a0=“”(空串),a(n+1)=a*(an)。
输入
每组测试数据占一行,为一个字符串s,s中的字符都是可显示的。s的长度至少为1,最多不超过1000000个字符。字符“.”,表示输入结束。
输出
对每个字符串s,输出最大整数n,满足:s=an,a为某个字符串。
样例输入
abcd
aaaa
ababab
样例输出
1
4
3
解析
思路梳理
这题比较简单,思路和问题B差不多,比问题B容易。
我们的思路依然是寻找符合条件的子串,也就是“底数”、重复节。
细节提示
寻找重复节的时候要注意重复节之间并不重叠,也就是说,假如输入是ababa,它的重复节应该是ababa而不是aba,也就是它的幂是1而不是2。为规避这个问题,可以通过对子串的长度进行选择,或是从原字符串中从和重复节长度相同的整倍数下标开始截取字符串进行判断。
此题容易判断,重复节一定可以从下标0开始,且重复节的长度一定是字符串长度的约数,所以我们可以加入该判断来减少运行时间,避免TLE的问题。
注意如果输入的是空行,我们的输出应该是0,本题以字符'.'表示结束。
注意循环到重复节为目标子串时跳出两个for循环的方式(flag)。
参考代码
#include<bits/stdc++.h>
using namespace std;
int main(){
string st;
while(cin>>st){
if(st[0]!='.'){
string sa;
int i = 1;
for (; i <= st.length();i++){
if(st.length()%i==0){
sa = st.substr(0, i);
int j = 1, flag = 1;
for (;i*j+i<=st.length();j++){
if(sa.compare(st.substr(i*j,i))!=0){
flag = 0;
break;
}
}
if(flag)
break;
}
}
cout << st.length() / i << endl;
}
else
break;
}
return 0;
}问题 H: 4210 回文
题目描述
一个规则的回文是一串由字符或数字组成的字符串,从前往后读与从后往前读完全一样。例如,字符串“ABCDEDCBA”就是个回文字符串,从左到右和从右到左都是一样的。
所谓镜像字符串,就是将字符串中的每个字符用对应的相反字符(如果存在相反字符)替换后,得到的新字符串从后往前读,跟原来的字符串一样。例如,3AIAE就是一个镜像字符串,因为A和I是它们本身的相反字符,并且3和E互为相反字符。字符串3AIAE中,各字符转换成其相反字符后,变成EAIA3,这个字符串从后往前读,就是原来的字符串。
镜像回文就是同时满足回文字符串和镜像字符串条件的字符串。例如,ATOYOTA就是一个镜像回文,因为这个字符从后往前读和原来的一样,替换成相反字符后,得到ATOYOTA,从后往前读也和原来的一样。
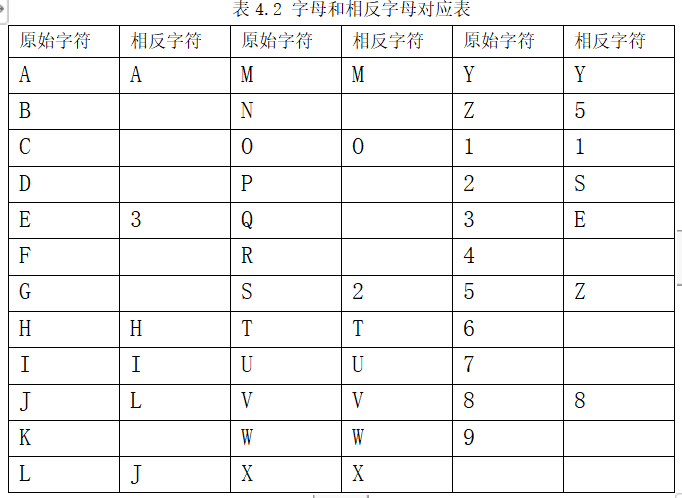
注意:数字0和字符O被认为是同一个字符,因此只有字符O才是有效的字符。
输入
输入文件包括多个字符串,每行一个,每个字符串包含1~20个有效字符,不会包含无效字符。输入数据一直到文件尾。
输出
对输入的每个字符串,在第1列开始输出字符串本身,接着输出以下字符串中的一个:
“ -- is not a palindrome.” 既不是回文,也不是镜像字符串
“ -- is a regular palindrome.”是回文,但不是镜像字符串
“ -- is a mirrored string.”不是回文,但是镜像字符串
“ -- is a mirrored palindrome.”既是回文也是镜像字符串
注意:请按照输出输出样例空格和字符“-”,每个输出后有一个空行。
样例输入
NOTAPALINDROME
ISAPALINILAPASI
2A3MEAS
ATOYOTA
样例输出
NOTAPALINDROME -- is not a palindrome.
ISAPALINILAPASI -- is a regular palindrome.
2A3MEAS -- is a mirrored string.
ATOYOTA -- is a mirrored palindrome.
解析
思路梳理
分别判断回文和镜像,注意可以利用一些函数简化判断。
细节提示
判断镜像的时候,可以利用如下方式快速得知该字符串是否可能镜像,即判断是否全由可镜像字符组成。
if(st.find_first_of("BCDFGKNPQR4679")!=string::npos)
flag2 = 0;//有不能镜像的字符,不可能是镜像str1.find_first_of(str2)函数返归的是首个字符串str1中含有的str2中的单个字符的下标,假如没有就返回string::npos。
参考代码
#include<bits/stdc++.h>
using namespace std;
int mirror(char a,char b){
if((a=='A'&&b=='A')||(a=='E'&&b=='3')||(a=='H'&&b=='H')||(a=='I'&&b=='I')||(a=='J'&&b=='L')||(a=='L'&&b=='J')||(a=='M'&&b=='M')||(a=='O'&&b=='O')||(a=='S'&&b=='2')||(a=='T'&&b=='T')||(a=='U'&&b=='U')||(a=='V'&&b=='V')||(a=='W'&&b=='W')||(a=='X'&&b=='X')||(a=='Y'&&b=='Y')||(a=='Z'&&b=='5')||(a=='1'&&b=='1')||(a=='2'&&b=='S')||(a=='3'&&b=='E')||(a=='5'&&b=='Z')||(a=='8'&&b=='8'))
return 1;
return 0;
}
int main(){
string st;
while (cin >> st){
int i = 0, j = st.length() - 1;
int flag1 = 1, flag2 = 1;
int k = 0;
while(i+k<=j-k){
if(st[i+k]==st[j-k])
k++;
else{
flag1 = 0;//有不同,不是回文
break;
}
}
if(st.find_first_of("BCDFGKNPQR4679")!=string::npos)
flag2 = 0;//有不能镜像的字符,不可能是镜像
if(flag2){
int k = 0;
while(i+k<=j-k){
if(mirror(st[i+k],st[j-k]))
k++;
else{
flag2 = 0;
break;
}
}
}
if(flag1&&flag2)
cout << st << " -- is a mirrored palindrome." << endl;
else if(flag1)
cout << st << " -- is a regular palindrome." << endl;
else if(flag2)
cout << st << " -- is a mirrored string." << endl;
else
cout << st << " -- is not a palindrome." << endl;
cout << endl;
}
return 0;
}














 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









