









*之前偶然看了某个腾讯公开课的视频,写的爬取赶集网的租房信息,这几天突然想起来,于是自己分析了一下赶集网的信息,然后自己写了一遍,写完又用用Python3重写了一遍.之中也遇见了少许的坑.记一下.算是一个总结.*
python2 爬取赶集网租房信息与网站分析
- 分析目标网站url
- 寻找目标标签
- 获取,并写入csv文件
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from urlparse import urljoin
import requests
import csv
URL = 'http://jn.ganji.com/fang1/o{page}p{price}/'
# 首先最基本的是 jn,ganji.com/fang1 其中jn为济南,也就是我的城市,默认登录后为此
# 而fang1 位租房信息 fang5 为二手房信息,zhaopin 为招聘模块等,我们这次只查找fang1
# 不过这个链接还可以更复杂
#比如http://jn.ganji.com/fang1/tianqiao/h1o1p1/ 或者
# http://jn.ganji.com/fang1/tianqiao/b1000e1577/
# 其中h:房型,o页面,p价格区间,其中h,p后的数字与网站相应菜单的排列顺序相对应
# 而s与e则为对应的自己输入的价格区间
# h: house o:page p:price
# jn jinan fang1 zufang tiaoqiao:tianqiaoqu b:begin 1000 e:end start 1755
ADDR = 'http://bj.ganji.com/'
start_page =1
end_page = 5
price =1
# 注意wb格式打开写入可能会导致csv文件每次写入前面多一个空格
# 对此你可以参考这篇文章:http://blog.csdn.net/pfm685757/article/details/47806469
with open('info.csv','wb') as f :
csv_writer = csv.writer(f,delimiter=',')
print 'starting'
while start_page<end_page:
start_page+=1
# 通过分析标签可知我们要获取的标签信息必须要通过多个class确认才能保证唯一性
# 之后是获取信息的具体设置
print 'get{0}'.format(URL.format(page = start_page,price=price))
response = requests.get(URL.format(page = start_page,price=price))
html=BeautifulSoup(response.text,'html.parser')
house_list = html.select('.f-list > .f-list-item > .f-list-item-wrap')
#check house_list
if not house_list:
print 'No house_list'
break
for house in house_list:
house_title = house.select('.title > a')[0].string.encode('utf-8')
house_addr = house.select('.address > .area > a')[-1].string.encode('utf-8')
house_price = house.select('.info > .price > .num')[0].string.encode('utf-8')
house_url = urljoin(ADDR,house.select('.title > a ')[0]['href'])
# 写入csv文件
csv_writer.writerow([house_title,house_addr,house_price,house_url])
print 'ending'Python3 爬取赶集网i租房信息
要注意的点
- urlparse.urljoin 改为urllib.urlparse.urljoin
# python2
from urlparse import urljoin
# Python3
from urllib.parse import urljoin- Python3中csv对bytes和str两种类型进行了严格区分,open的写入格式应该进行改变wb->w
- 设置utf8编码格式
with open('info.csv','w',encoding='utf8') as f :
csv_writer = csv.writer(f,delimiter=',')完整代码如下
#-*- coding: utf-8 -*-
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import requests
import csv
URL = 'http://jn.ganji.com/fang1/o{page}p{price}/'
# h: house o:page p:price
# http://jn.ganji.com/fang1/tianqiao/b1000e1577/
# jn jinan fang1 zufang tiaoqiao:tianqiaoqu b:begin 1000 e:end start 1755
# fang5 为二手房 zhipin 为 招聘 赶集网的url划分的都很简单,时间充足完全可以获取非常多的信息
ADDR = 'http://bj.ganji.com/'
start_page =1
end_page = 5
price =1
'''
URL = 'http://jn.ganji.com/fang1/h{huxing}o{page}b{beginPrice}e{endPrice}/'
# 选择户型为h1-h5
# 输入价位为 begin or end
price='b1000e2000'
# 户型为
'''
# 默认为utf8打开,否则会以默认编码GBK写入
with open('info.csv','w',encoding='utf8') as f :
csv_writer = csv.writer(f,delimiter=',')
print('starting')
while start_page<end_page:
start_page+=1
print('get{0}'.format(URL.format(page = start_page,price=price)))
response = requests.get(URL.format(page = start_page,price=price))
html=BeautifulSoup(response.text,'html.parser')
house_list = html.select('.f-list > .f-list-item > .f-list-item-wrap')
#check house_list
if not house_list:
print('No house_list')
break
for house in house_list:
house_title = house.select('.title > a')[0].string
house_addr = house.select('.address > .area > a')[-1].string
house_price = house.select('.info > .price > .num')[0].string
house_url = urljoin(ADDR, house.select('.title > a ')[0]['href'])
csv_writer.writerow([house_title,house_addr,house_price,house_url])
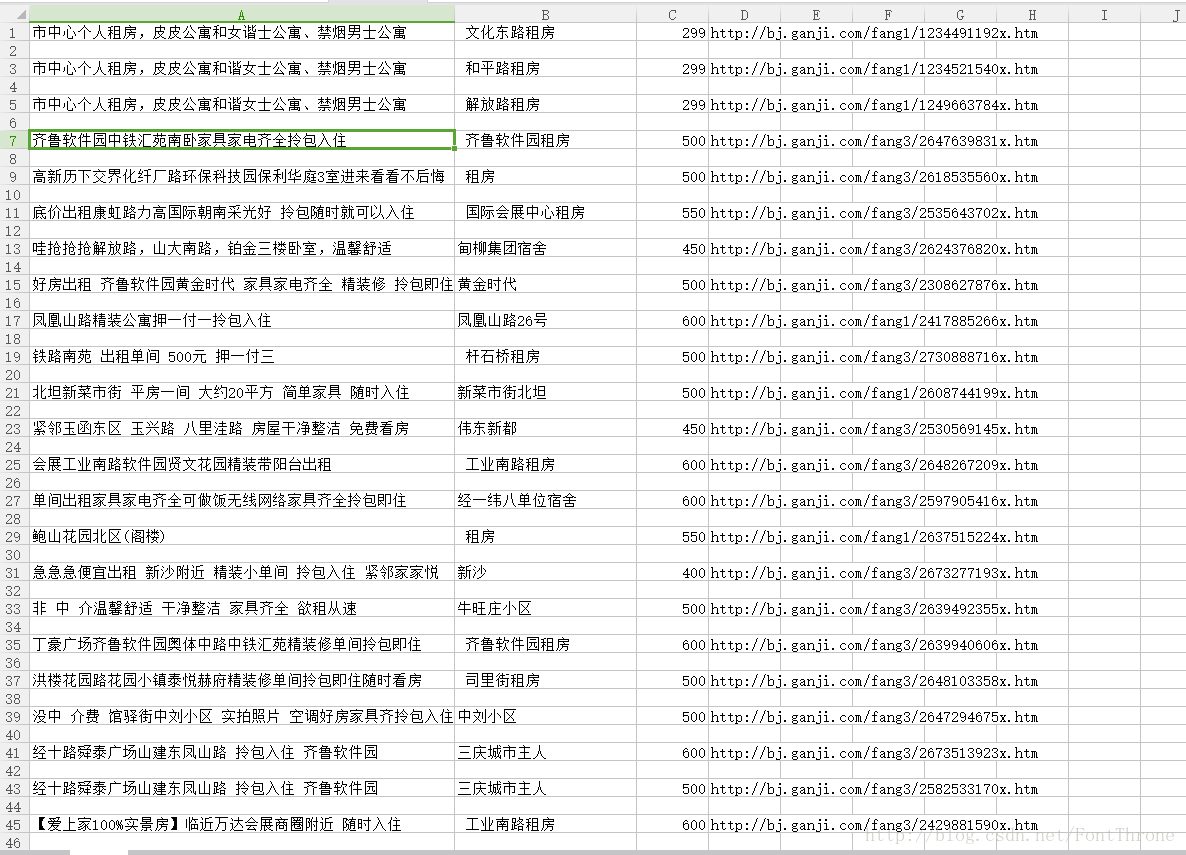
print('ending')最后的csv文件展示一下:















 1096
1096











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











