






public static final int NO_MATCH = -1;
/**
* Creates the root node of the URI tree.
*
* @param code the code to match for the root URI
*/
// 构造方法
public UriMatcher(int code)
{
mCode = code;
mWhich = -1;
mChildren = new ArrayList<UriMatcher>();
mText = null;
}
// 构造方法
private UriMatcher()
{
mCode = NO_MATCH;
mWhich = -1;
mChildren = new ArrayList<UriMatcher>();
mText = null;
}该UriMatcher对象的 成员变量如下:
mCode = NO_MATCH;
mWhich = -1;
mChildren = new ArrayList<UriMatcher>();
mText = null;此时的树形结构图如下:

其余成员变量的初始化:
private static final int EXACT = 0;
private static final int NUMBER = 1;
private static final int TEXT = 2;
private int mCode;
private int mWhich;
private String mText;
private ArrayList<UriMatcher> mChildren;public void addURI(String authority, String path, int code)
{
if (code < 0) { // code小于0就报异常
throw new IllegalArgumentException("code " + code + " is invalid: it must be positive");
}
String[] tokens = null;
// 以“/”作为分隔符分隔path,得到字符串数组tokens
if (path != null) {
String newPath = path;
// Strip leading slash if present.
// 如果第一个字符就是分隔符“/”,则去掉
if (path.length() > 0 && path.charAt(0) == '/') {
newPath = path.substring(1);
}
tokens = newPath.split("/");
}
int numTokens = tokens != null ? tokens.length : 0; // 字符串数组的元素个数
UriMatcher node = this; // 第一个node为其自身
// 断点1
for (int i = -1; i < numTokens; i++) { // 从-1开始
// 每一个循环都是要判断是否要构造一个UriMatcher添加到mChildren中
String token = i < 0 ? authority : tokens[i];
ArrayList<UriMatcher> children = node.mChildren;
int numChildren = children.size();
UriMatcher child;
int j;
// 断点2
// 遍历children中的元素,如果children中有一个UriMatcher的mText与token一致,则不必创建一个UriMatcher加入到mChildren这个成员变量中了,因为已经存在了,
// 此时(j==numChildren)不会成立,break之后直接进入到下一个i++的循环
for (j = 0; j < numChildren; j++) {
child = children.get(j);
if (token.equals(child.mText)) {
node = child;
// 断点3
break;
}
}
// 只有当children中没有一个UriMatcher的mText与token相同,才不会触发break,j会一直增加到numChildren从而退出j<numChildren的for循环,
// 因为没有与token匹配成功,那么就重新创建一个添加到mChildren中
if (j == numChildren) {
// Child not found, create it
child = new UriMatcher();
if (token.equals("#")) {
child.mWhich = NUMBER;
} else if (token.equals("*")) {
child.mWhich = TEXT;
} else {
child.mWhich = EXACT;
}
child.mText = token;
node.mChildren.add(child);
node = child; // 形成一个树形结构
}
// 断点4
}
node.mCode = code; // 最底层的UriMatcher的mCode才会被赋值为code,其余最顶层的和中间层的UriMatcher的mCode都会被赋值NO_MATCH
// 断点5
}
断点1:tokens = {"table", "1"},numTokens = 2
接下来进入到for循环,在i=-1的for循环中,
断点2:node即为对象A的numChildren = 0,token = "com.example.app.provider"
UriMatcher对象A的mChildren集合中不存在UriMatcher对象,所以numChildren = 0
在断点2下面的for循环中,尝试寻找对象A的mChildren集合中是否存在一个UriMatcher对象,使得它的mText与token相等;
由于 numChildren=0 且 j=0 ,不满足 j<numChildren 的条件,所以跳过断点2下面的for循环。
接着,由于j等于numChildren,所以进入到 if(j==numChildren) 的条件判断语句中,创建一个新的UriMatcher对象,记为B。
对token进行划分,与“#”相等,则B的mWhich记为NUMBER,与“*”相等,则B的mWhich记为TEXT,其他情况,则B的mWhich记为EXACT。
将对象B添加到对象A的mChildren集合中,并将对象B作为下一次循环的node。
到断点4位置,结构图如下:
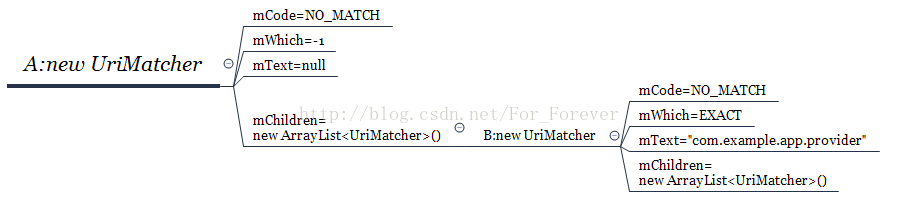
第二个循环,i=0,到断点2时,token = "table1",numChildren = 0;
此时会重复 i=-1 的那个循环的处理过程,重新创建一个UriMatcher对象C,进行成员变量赋值后加入到对象B的mChildren集合里面,并将对象C作为下一次循环的node。
到断点4位置,结构图如下:
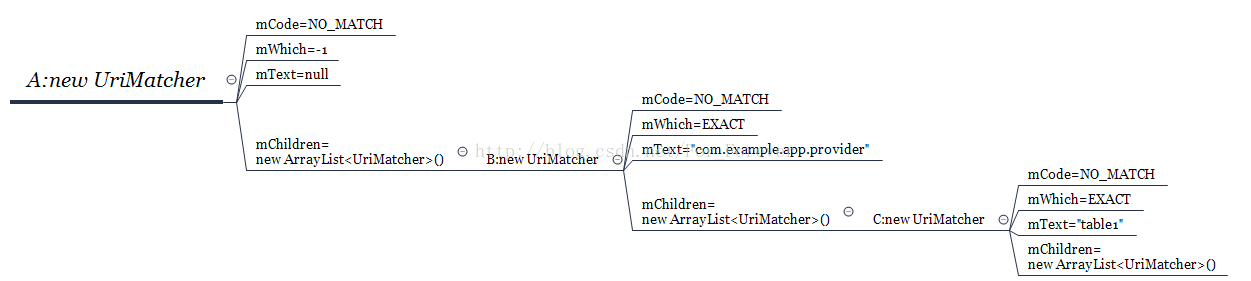
第三个循环,i=1,到断点2时,token = "1",numChildren = 0;
重复上面的循环,重新创建一个UriMatcher对象D,进行成员变量赋值后加入到对象C的mChildren集合里面,并将对象D作为下一次循环的node。
到断点4位置,结构图如下:

到断点5位置,将addURI方法中的参数code赋值给对象D的成员变量mCode。至此,第一个addURI已经分析完成。
断点1处:tokens = {“table1”, "*"},numTokens = 2,node为对象A。
接下来进入到 i = -1 的for循环。
到断点2处,token = “com.example.app.provider”,numChildren = 1。由于 j=0 且 j<numChildren ,进入到断点2下面的for循环中,对象A的mChildren集合中有一个对象B,由于token与对象B的mText相同,所以程序执行到断点3处的break,并且在break之前将对象B作为下一个node,然后就退出这个for循环。
同时由于 j 仍然为0,不等于numChildren,所以 i=-1 时的流程走结束了。
由于在对象A中已经存在了这样的一个符合要求的UriMatcher对象,所以就不会创建新的UriMatcher对象了。
可以理解成,一个人在文件夹A下面已经有了一个文件夹B了,这个时候,另一个人也需要在文件夹A下创建文件夹B做其他用,但是发现,文件夹A里面已经存在文件夹B了,那么直接拿来用就可以了。
接下来进入到 i=0 的for循环。
到断点2处,token = “table1”,numChildren = 1。与 i=-1 的流程一致,token与对象C的mText相同,则对象C作为新的node,并进入到 i=1 的循环中。
在 i=1 的for循环里,到断点2处,token = “*”,numChildren = 1。
在进入到断点2下面的for循环中时,遍历对象C的mChildren集合中的对象,没有一个对象的mText与token相同,所以需要重新创建一个UriMatcher对象添加到对象C的mChildren集合中。
此时,j=1,与numChildren相等,从而进入到 if (j == numChildren) 的判断语句中,创建一个UriMatcher对象E,并给对象E进行相应的赋值。由于 j<numTokens 已经不满足条件,所以退出for循环。
到断点5时,结构图如下:
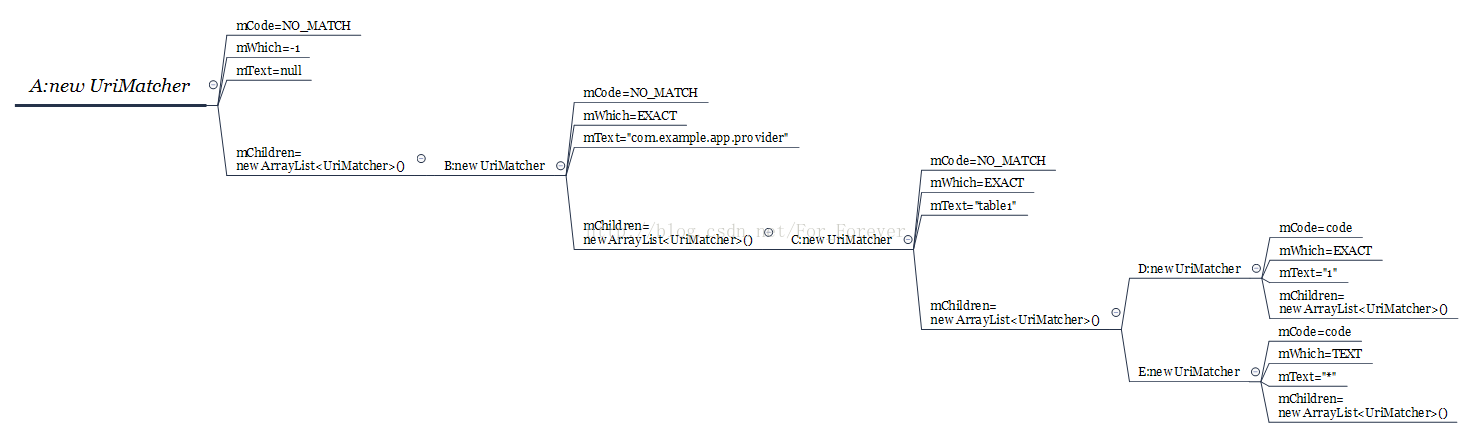
// 根据url来匹配获得addURI中的code
public int match(Uri uri)
{
// 获得权限后面的部分,以“/”进行分割,且分割后的每个字符串按照先后顺序在集合pathSegments中
final List<String> pathSegments = uri.getPathSegments();
final int li = pathSegments.size();
UriMatcher node = this;
// 如果pathSegments为空并且权限为空,则返回该对象的mCode
if (li == 0 && uri.getAuthority() == null) {
return this.mCode;
}
// 把权限和pathSegments中的元素,一一进行匹配
for (int i=-1; i<li; i++) {
String u = i < 0 ? uri.getAuthority() : pathSegments.get(i);
ArrayList<UriMatcher> list = node.mChildren;
if (list == null) {
// 如果在匹配的过程中,出现node的成员变量mChildren为空的情况,则直接退出
break;
}
node = null;
int lj = list.size();
// 遍历mChildren中的UriMatcher对象,看看是否有满足mWhich和mText符合要求的
for (int j=0; j<lj; j++) {
UriMatcher n = list.get(j);
which_switch:
switch (n.mWhich) {
case EXACT:
if (n.mText.equals(u)) {
node = n;
}
break;
case NUMBER:
int lk = u.length();
for (int k=0; k<lk; k++) {
char c = u.charAt(k);
if (c < '0' || c > '9') {
break which_switch;
}
}
node = n;
break;
case TEXT:
node = n;
break;
}
// 如果node不为null,说明找到了一个node,并break掉当前的遍历循环,但是还没有跳出外面的for循环
if (node != null) {
break;
}
}
// 如果说遍历mChildren中的UriMatcher对象,都没有找到符合要求的UriMatcher对象,说明匹配不成功,直接返回NO_MATCH
if (node == null) {
return NO_MATCH;
}
}
// 执行到此处,说明匹配成功了,返回该UriMatcher对象的mCode
return node.mCode;
}














 733
733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









