







 本文探讨了如何模拟实现cJSON库,专注于处理JSON类型的结构,用于存储不同类型的数据单元。通过分析提供的cJSON.h源码,深入理解JSON数据的解析和操作。
本文探讨了如何模拟实现cJSON库,专注于处理JSON类型的结构,用于存储不同类型的数据单元。通过分析提供的cJSON.h源码,深入理解JSON数据的解析和操作。
CJSON
CJSON是C语言的一个编解码工具,JSON是一种轻量级数据交换格式(基于JavaScript的一个子集)
CJSON主要功能:
构建和解析 json格式,发送的数据用json封装,收到数据再以json格式解析
优点:轻量级、速度快
缺点:功能上不够强大
1、CJSON的六种基本类型
NULL、布尔型、数值型、字符型、数组、对象.(object)
减少在解析是传递多个参数的问题
将字符串解析至json类型的结构体中
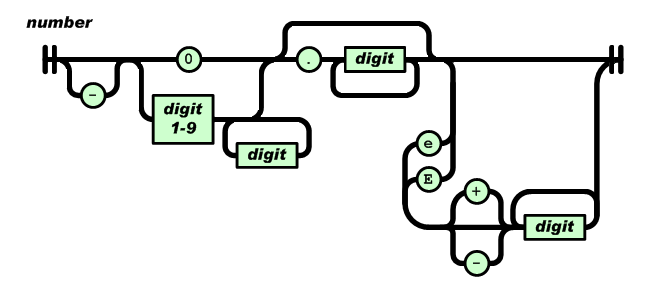
1、解析数值:
注意数字的语法,最开始不能有+, 可以时科学计数法等
通过对数值语法的判断和库函数strtod()将字符串转为double数值
通过状态机完成判断,用double类型存储数值:
2、解析字符串:
由于有转义字符、非转义字符和\uXXXX等特殊字符等,引入码点的概念。
注意:在json语法中允许有空字符的存在。所有我们加入记录字符串长度的变量,由于C语言的字符串都以\0结尾,所以我们在字符串结尾也加入\0。
解析字符串(以及之后的数组、对象)时,需要把解析的结果先储存在一个临时的缓冲区,最后再用lept_set_string() 把缓冲区的结果设进值之中,所以在lept_context结构中引入由字符串实现的栈结构。在解析前初始化栈结构,解析后释放栈空间。
Unicode编码:
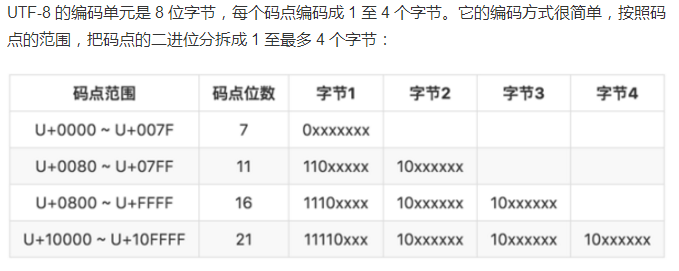
由于不止有Ascll字符,还有中文。韩文等许多字符,所以引入Unicode编码,Unicode使每个字符映射唯一码点,码点的范围是0~0x10FFFF。码点通常记做U+XXXX,后面的X表示四位16进制数字。Unicode制定了各种存储码点的方式,UTF会将一个码点存至一个或多个编码单元,比如UTF_8的编码单元为8位的字节(可变长编码 )。
对于编码的存储:
1、非转义字符直接存储
2、U+0000~U+FFFF:解析4位16进制,存至一至四个字节
3、大于0xFFFF的属于代理对,即通过公式将高代理项和低代理项得出码点,然后将码点转换为UTF-8编码。
3、数组的解析:
JSON 数组的语法很简单,实现的难点不在语法上,而是怎样管理内存
存储 JSON 数组类型的数据结构:数组。
我们将会通过之前在解析字符串时实现的堆栈,来解决解析 JSON 数组时未知数组大小的问题
4、对象的解析:
五步:
第 1 步是利用刚才重构出来的 lept_parse_string_raw() 去解析键的字符串
第 2 步是解析冒号,冒号前后可有空白字符:
第 3 步是解析任意的 JSON 值。这部分与解析数组一样,递归调用 lept_parse_value(),把结果写入临时 lept_member 的 v 字段,然后把整个 lept_member 压入栈:
第 4 步,解析逗号或右花括号。遇上右花括号的话,当前的 JSON 对象就解析完结了,我们把栈上的成员复制至结果,并直接返回:
最后,当 for (;;) 中遇到任何错误便会到达这第 5 步,要释放临时的 key 字符串及栈上的成员
生成器:
将json类型的结构体生成字符串
JSON 生成器(generator)负责相反的事情,就是把树形数据结构转换成 JSON 文本。这个过程又称为「字符串化(stringify)」。
在实现 JSON 解析时,我们加入了一个动态变长的堆栈,用于存储临时的解析结果。而现在,我们也需要存储生成的结果,所以最简单是再利用该数据结构,作为输出缓冲区。
单元测试:
测试驱动开发TDD(即先写测试用例,再写代码满足测试用例):
步骤:
1. 加入一个测试。
2. 运行所有测试,新的测试应该会失败。
3. 编写实现代码。
4. 运行所有测试,若有测试失败回到3。
5. 重构代码。
6. 回到 1。
项目难点:
1、数字的校验:
虽然#include<stdlib.h>库函数strtod()可以将字符串转化为数值,但是不符合json语法的字符串在strtod函数中可以有效转换,所以需要先对字符串格式进行校验,合法后再进行转换
2、字符串的解析:
在json语法中允许出现空字符,为了解决该问题,我们分配内存存储解析后的字符串,并且存储字符串的长度,考虑C语言字符串以空结尾,故在最后我们还需要再加一个空字符。
对字符串的解析是动态申请的堆内存,所以在最后我们要调用lept_free()函数释放内存。
3、引入Unicode编码:
引入了Unicode编码,对转移字符的解析,将码点转换为UTF-8存储,并且有代理项的特殊情况需要计算出码点后再转化为UTF-8存储。
4、释放内存时需要对数组和对象类型进行递给释放。
cJSON.c文件
CJSON是C语言的一个编解码工具,JSON是一种轻量级数据交换格式(基于JavaScript的一个子集)
CJSON主要功能:
构建和解析 json格式,发送的数据用json封装,收到数据再以json格式解析
优点:轻量级、速度快
缺点:功能上不够强大
1、CJSON的六种基本类型
NULL、布尔型、数值型、字符型、数组、对象.(object)
json类型的结构---存储各种类型的单元
struct lept_value //json树结点的类型
{
//因为一个值不能同为数字和字符串,联合体节省空间
union{
struct { lept_member* m; size_t size; }o;
struct { lept_value* e; size_t size; }a; //array
struct { char* s; size_t len; }s; //string
double n; //number
}u;
lept_type type;
};减少在解析是传递多个参数的问题
typedef struct{
const char* json;
char* stack; //该栈按字节存储---动态的栈结构
size_t size, top; //size为栈的大小,top为栈顶
}lept_context;struct lept_member
{
char* k; //对象的键值key
size_t klen; //键值的长度
lept_value v; //对象的value
};
将字符串解析至json类型的结构体中
1、解析数值:
注意数字的语法,最开始不能有+, 可以时科学计数法等
通过对数值语法的判断和库函数strtod()将字符串转为double数值
通过状态机完成判断,用double类型存储数值:
2、解析字符串:
由于有转义字符、非转义字符和\uXXXX等特殊字符等,引入码点的概念。
注意:在json语法中允许有空字符的存在。所有我们加入记录字符串长度的变量,由于C语言的字符串都以\0结尾,所以我们在字符串结尾也加入\0。
解析字符串(以及之后的数组、对象)时,需要把解析的结果先储存在一个临时的缓冲区,最后再用lept_set_string() 把缓冲区的结果设进值之中,所以在lept_context结构中引入由字符串实现的栈结构。在解析前初始化栈结构,解析后释放栈空间。
Unicode编码:
由于不止有Ascll字符,还有中文。韩文等许多字符,所以引入Unicode编码,Unicode使每个字符映射唯一码点,码点的范围是0~0x10FFFF。码点通常记做U+XXXX,后面的X表示四位16进制数字。Unicode制定了各种存储码点的方式,UTF会将一个码点存至一个或多个编码单元,比如UTF_8的编码单元为8位的字节(可变长编码 )。
对于编码的存储:
1、非转义字符直接存储
2、U+0000~U+FFFF:解析4位16进制,存至一至四个字节
3、大于0xFFFF的属于代理对,即通过公式将高代理项和低代理项得出码点,然后将码点转换为UTF-8编码。
3、数组的解析:
JSON 数组的语法很简单,实现的难点不在语法上,而是怎样管理内存
存储 JSON 数组类型的数据结构:数组。
我们将会通过之前在解析字符串时实现的堆栈,来解决解析 JSON 数组时未知数组大小的问题
4、对象的解析:
五步:
第 1 步是利用刚才重构出来的 lept_parse_string_raw() 去解析键的字符串
第 2 步是解析冒号,冒号前后可有空白字符:
第 3 步是解析任意的 JSON 值。这部分与解析数组一样,递归调用 lept_parse_value(),把结果写入临时 lept_member 的 v 字段,然后把整个 lept_member 压入栈:
第 4 步,解析逗号或右花括号。遇上右花括号的话,当前的 JSON 对象就解析完结了,我们把栈上的成员复制至结果,并直接返回:
最后,当 for (;;) 中遇到任何错误便会到达这第 5 步,要释放临时的 key 字符串及栈上的成员
生成器:
将json类型的结构体生成字符串
JSON 生成器(generator)负责相反的事情,就是把树形数据结构转换成 JSON 文本。这个过程又称为「字符串化(stringify)」。
在实现 JSON 解析时,我们加入了一个动态变长的堆栈,用于存储临时的解析结果。而现在,我们也需要存储生成的结果,所以最简单是再利用该数据结构,作为输出缓冲区。
单元测试:
测试驱动开发TDD(即先写测试用例,再写代码满足测试用例):
步骤:
1. 加入一个测试。
2. 运行所有测试,新的测试应该会失败。
3. 编写实现代码。
4. 运行所有测试,若有测试失败回到3。
5. 重构代码。
6. 回到 1。
项目难点:
1、数字的校验:
虽然#include<stdlib.h>库函数strtod()可以将字符串转化为数值,但是不符合json语法的字符串在strtod函数中可以有效转换,所以需要先对字符串格式进行校验,合法后再进行转换
2、字符串的解析:
在json语法中允许出现空字符,为了解决该问题,我们分配内存存储解析后的字符串,并且存储字符串的长度,考虑C语言字符串以空结尾,故在最后我们还需要再加一个空字符。
对字符串的解析是动态申请的堆内存,所以在最后我们要调用lept_free()函数释放内存。
3、引入Unicode编码:
引入了Unicode编码,对转移字符的解析,将码点转换为UTF-8存储,并且有代理项的特殊情况需要计算出码点后再转化为UTF-8存储。
4、释放内存时需要对数组和对象类型进行递给释放。
源码:
cJSON.h文件
#ifndef _LEPTJSON_H__
#define _LEPTJSON_H__
#include <stddef.h> /* size_t */
typedef enum //枚举json的6种数据类型
{
LEPT_NULL,
LEPT_FALSE,
LEPT_TRUE,
LEPT_NUMBER,
LEPT_STRING,
LEPT_ARRAY,
LEPT_OBJECT
}lept_type;
typedef struct lept_value lept_value;
typedef struct lept_member lept_member;
struct lept_value //json树结点的类型
{
//因为一个值不能同为数字和字符串,联合体节省空间
union{
struct { lept_member* m; size_t size; }o;
struct { lept_value* e; size_t size; }a; //array
struct { char* s; size_t len; }s; //string
double n; //number
}u;
lept_type type;
};
struct lept_member
{
char* k; //对象的键值key
size_t klen; //键值的长度
lept_value v; //对象的value
};
//状态码
enum{
LEPT_PARSE_OK = 0, //无错误
LEPT_PARSE_EXPECT_VALUE, //若一个JSON只有空白
LEPT_PARSE_INVALID_VALUE, //若不是json的6中数据类型
LEPT_PARSE_ROOT_NOT_SINGULAR, //若一个值之后,空白之后还有其他字符
LEPT_PARSE_NUMBER_TOO_BIG, //数值太大
LEPT_PARSE_MISS_QUOTATION_MARK, //遇到字符串结束标记
LEPT_PARSE_INVALID_STRING_ESCAPE,//非法转义字符
LEPT_PARSE_INVALID_STRING_CHAR, //非法字符
LEPT_PARSE_INVALID_UNICODE_HEX, //\u后不是4位16进制
LEPT_PARSE_INVALID_UNICODE_SURROGATE, //unicode不在合法范围
LEPT_PARSE_MISS_COMMA_OR_SQUARE_BRACKET, //数组漏掉逗号或中括号
LEPT_PARSE_MISS_KEY, //漏掉了键值
LEPT_PARSE_MISS_COLON, //漏掉了冒号
LEPT_PARSE_MISS_COMMA_OR_CURLY_BRACKET //漏掉了逗号或大括号
};
#define lept_init(v) do{ (v)->type = LEPT_NULL; }while(0)
int lept_parse(lept_value* v, const char* json); //解析JSON---传入一个字符串,返回枚举类型错误码
char* lept_stringify(const lept_value* v, size_t* length); //将六种类型生成字符串返回
void lept_free(lept_value* v); //清空v里面可能分配的内存
lept_type lept_get_type(const lept_value* v); //访问结果的接口---获取类型
#define lept_set_null(v) lept_free(v)
int lept_get_boolean(const lept_value* v);
void lept_set_boolean(lept_value* v, int b);
double lept_get_number(const lept_value* v); //获取数值的接口
void lept_set_number(lept_value* v, double n);
const char* lept_get_string(const lept_value* v);
size_t lept_get_string_length(const lept_value* v);
void lept_set_string(lept_value* v, const char* s, size_t len); //将s复制一份至v
size_t lept_get_array_size(const lept_value* v);
lept_value* lept_get_array_element(const lept_value* v, size_t index); //获取数组下标对应的地址
size_t lept_get_object_size(const lept_value* v);
const char* lept_get_object_key(const lept_value* v, size_t index);
size_t lept_get_object_key_length(const lept_value* v, size_t index);
lept_value* lept_get_object_value(const lept_value* v, size_t index);
#endif //_LEPTJSON_H__
cJSON.c文件
#ifdef _WINDOWS
#define _CRTDBG_MAP_ALLOC
#include <crtdbg.h>
#endif
#include "cJSON.h"
#include <stdlib.h> /* NULL, strtod() */
#include <assert.h> /* assert() */
#include <errno.h> /* errno, ERANGE */
#include <math.h> /* HUGE_VAL */
#include <string.h>
#ifndef LEPT_PARSE_STACK_INIT_SIZE
#define LEPT_PARSE_STACK_INIT_SIZE 256
#endif
#ifndef LEPT_PARSE_STRINGIFY_INIT_SIZE
#define LEPT_PARSE_STRINGIFY_INIT_SIZE 256
#endif
#define EXPECT(c, ch) do{ assert(*c->json == (ch)); c->json++; }while(0)
#define ISDIGIT(ch) ((ch) >= '0' && (ch) <= '9')
#define ISDIGIT1TO9(ch) ((ch) >= '1' && (ch) <= '9')
#define PUTC(c, ch) do{ *(char*)lept_context_push(c, sizeof(char)) = (ch); }while(0)
#define PUTS(c, s, len) memcpy(lept_context_push(c, len), s, len)
typedef struct{
const char* json;
char* stack; //该栈按字节存储
size_t size, top; //size为栈的大小,top为栈顶
}lept_context;
static void* lept_context_push(lept_context* c, size_t size) //扩容,返回栈顶指针
{
void* ret;
assert(size > 0);
if (c->top + size >= c->size)
{
if (c->size == 0)
c->size = LEPT_PARSE_STACK_INIT_SIZE;
while (c->top + size >= c->size)
c->size += c->size >> 1; /* c->size * 1.5 */
c->stack = (char*)realloc(c->stack, c->size);
}
ret = c->stack + c->top;
c->top += size; //返回将要入栈的位置,但top需要将即将入栈的字节加进去
return ret;
}
static void* lept_context_pop(lept_context* c, size_t size)
{
assert(c->top >= size);
return c->stack + (c->top -= size);
}
//ws = *(%x20 / %x09 / %x0A / %x0D)
static void lept_parse_whitespace(lept_context* c)
{
const char* p = c->json;
while (*p == 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









