







本系列博文主要介绍了在文本摘要领域神经网络模型的一些发展,主要基于如下几类模型:
- Basic Encoder-Decoder model
- Encoder-Decoder + Attention
- Deep Reinforced model
- Bert based model
- GAN based model
- Consideration
Sequence-to-Sequence Based Model
EMNLP 2015 《A Neural Attention Model for Abstractive Sentence Summarization》
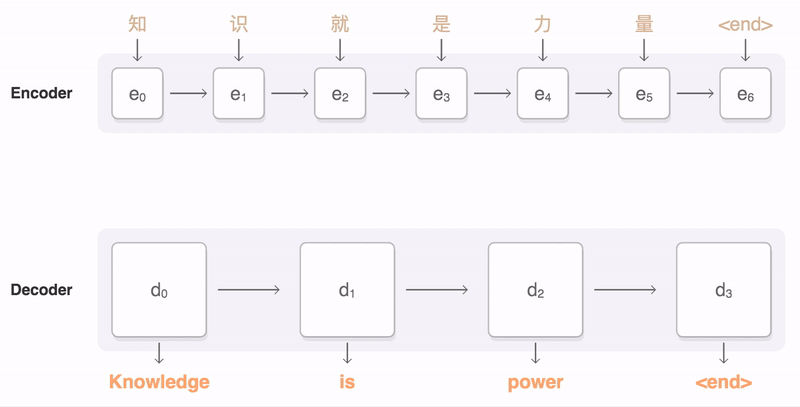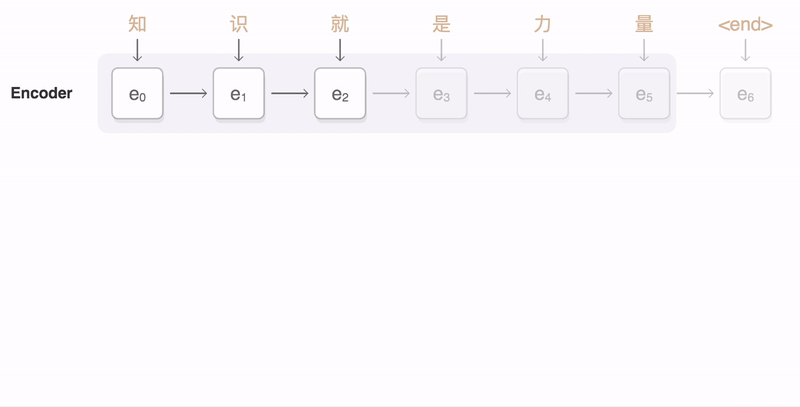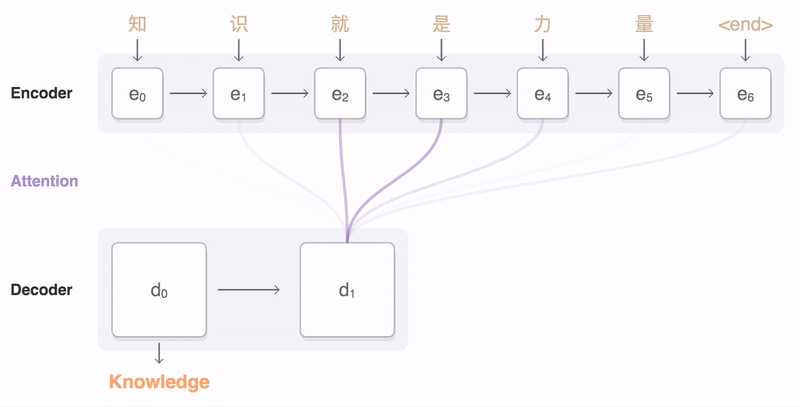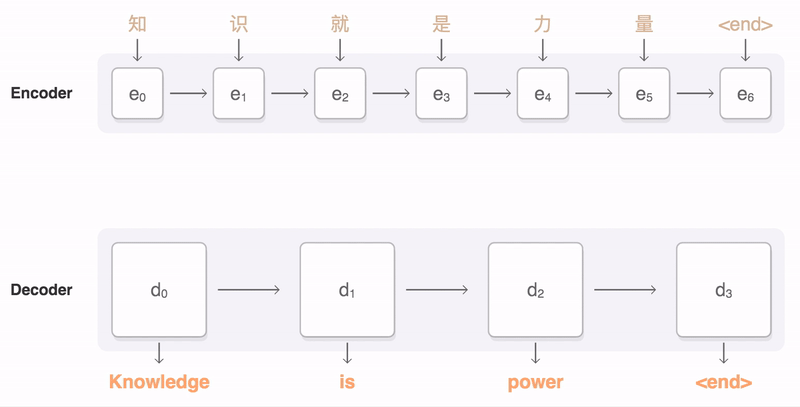
这篇文章是首次使用神经网络来做抽象式摘要生成工作,提出的模型也就是后续常见的基准模型TextSum。整个模型的架构如下所示,本质上可以看作是一个条件神经网络语言模型(conditional neural network language model),目标是最大化 p ( y i + 1 ∣ x , y c ; θ ) p(y_{i+1}|x,y_{c};\theta) p(yi+1∣x,yc;θ)。

其中的
W
,
V
,
U
,
E
W,V,U,E
W,V,U,E是enc网络的参数。整个流程可以表示为
p
(
y
i
+
1
∣
y
c
,
x
;
θ
)
∝
exp
(
V
h
+
W
enc
(
x
,
y
c
)
)
y
~
c
=
[
E
y
i
−
C
+
1
,
…
,
E
y
i
]
h
=
tanh
(
U
y
~
c
)
\begin{aligned} p\left(\mathbf{y}_{i+1} | \mathbf{y}_{\mathrm{c}}, \mathbf{x} ; \theta\right) & \propto \exp \left(\mathbf{V} \mathbf{h}+\mathbf{W} \operatorname{enc}\left(\mathbf{x}, \mathbf{y}_{\mathrm{c}}\right)\right) \\ \tilde{\mathbf{y}}_{\mathrm{c}} &=\left[\mathbf{E} \mathbf{y}_{i-C+1}, \ldots, \mathbf{E y}_{i}\right] \\ \mathbf{h} &=\tanh \left(\mathbf{U} \tilde{\mathbf{y}}_{\mathrm{c}}\right) \end{aligned}
p(yi+1∣yc,x;θ)y~ch∝exp(Vh+Wenc(x,yc))=[Eyi−C+1,…,Eyi]=tanh(Uy~c)
其中在Encoder部分作者尝试了三种架构方式,分别是:
-
Bag-of-Words encoder:直接将 x x x的词向量进行叠加,不考虑和已产生的上下文信息的融合和词序所带来的信息,它可以在一定程度上捕获到词之间的相对重要性,但效果有限
enc 1 ( x , y c ) = p ⊤ x ~ p = [ 1 / M , … , 1 / M ] x ~ = [ F x 1 , … , F x M ] \begin{aligned} \operatorname{enc}_{1}\left(\mathrm{x}, \mathrm{y}_{\mathrm{c}}\right) &=\mathrm{p}^{\top} \tilde{\mathrm{x}} \\ \mathrm{p} &=[1 / M, \ldots, 1 / M] \\ \tilde{\mathrm{x}} &=\left[\mathrm{F} \mathrm{x}_{1}, \ldots, \mathrm{F} \mathrm{x}_{M}\right] \end{aligned} enc1(x,yc)px~=p⊤x~=[1/M,…,1/M]=[Fx1,…,FxM]
其中 F F F表示输入端的词嵌入矩阵。 -
CNN encoder:采用了标准的卷积和池化操作,它允许词在局部进行信息交互,而且在编码输入时并不需要考虑上下文 y c y_{c} yc
∀ j , enc 2 ( x , y c ) j = max i x ~ i , j L ∀ i , l ∈ { 1 , … L } , x ~ j l = tanh ( max { x ‾ 2 i − 1 l , x ‾ 2 i l } ) ∀ i , l ∈ { 1 , … L } , x ‾ i l = Q l x ~ [ i − Q , … , i + Q ] l − 1 x ~ 0 = [ F x 1 , … , F x M ] \begin{aligned} \forall j, \operatorname{enc}_{2}\left(\mathbf{x}, \mathbf{y}_{c}\right)_{j} &=\max _{i} \tilde{\mathbf{x}}_{i, j}^{L} \\ \forall i, l \in\{1, \ldots L\}, \tilde{\mathbf{x}}_{j}^{l} &=\tanh \left(\max \left\{\overline{\mathbf{x}}_{2 i-1}^{l}, \overline{\mathbf{x}}_{2 i}^{l}\right\}\right) \end{aligned} \\ \begin{aligned} \forall i, l \in\{1, \ldots L\}, & \overline{\mathbf{x}}_{i}^{l}=\mathbf{Q}^{l} \tilde{\mathbf{x}}_{[i-Q, \ldots, i+Q]}^{l-1} \\ \tilde{\mathbf{x}}^{0} &=\left[\mathbf{F} \mathbf{x}_{1}, \ldots, \mathbf{F} \mathbf{x}_{M}\right] \end{aligned} ∀j,enc2(x,yc)j∀i,l∈{1,…L},x~jl=imaxx~i,jL=tanh(max{x2i−1l,x2il})∀i,l∈{1,…L},x~0xil=Qlx~[i−Q,…,i+Q]l−1=[Fx1,…,FxM]
其中 F F F表示输入端的词嵌入矩阵, Q l Q^l Ql表示第 l l l层的卷积核。 -
Attention-Based encoder:使用注意力机制根据上下文信息生成关于完整输入句子的表示
enc 3 ( x , y c ) = p ⊤ x ‾ p ∝ exp ( x ~ P y ~ c ′ ) x ~ = [ F x 1 , … , F x M ] y ~ c ′ = [ G y i − C + 1 , … , G y i ] y ~ c ′ = ∑ q = i − Q i + Q x ~ i / Q \begin{aligned} \operatorname{enc}_{3}\left(\mathrm{x}, \mathrm{y}_{\mathrm{c}}\right) &=\mathrm{p}^{\top} \overline{\mathrm{x}} \\ \mathrm{p} & \propto \exp \left(\tilde{\mathrm{x}} \mathrm{P} \tilde{\mathrm{y}}_{\mathrm{c}}^{\prime}\right) \\ \tilde{\mathrm{x}} &=\left[\mathrm{F} \mathrm{x}_{1}, \ldots, \mathrm{F} \mathrm{x}_{M}\right] \\ \tilde{\mathrm{y}}_{\mathrm{c}}^{\prime} &=\left[\mathrm{G} \mathrm{y}_{i-C+1}, \ldots, \mathrm{Gy}_{i}\right] \\ \tilde{\mathrm{y}}_{\mathrm{c}}^{\prime} &=\sum_{q=i-Q}^{i+Q} \tilde{\mathrm{x}}_{i} / Q \end{aligned} enc3(x,yc)px~y~c′y~c′=p⊤x∝exp(x~Py~c′)=[Fx1,…,FxM]=[Gyi−C+1,…,Gyi]=q=i−Q∑i+Qx~i/Q
它将Bag-of-Words中的的 uniform distribution 替换成一个输入和和生成的摘要之间的软对齐(soft alignment ),这借鉴了机器翻译的思路。然后用学习到的这个软对齐来给输入的平滑版本进行加权。比如说,如果当前的上下文和位置 i i i能很好的对齐,那么单词 x i − Q , … , x i + Q x_{i−Q},…,x_{i+Q} xi−Q,…,xi+Q就会被 encoder 赋予更高的权重。

在最后的摘要生成步骤采用了集束搜索(Beam Search),beam-search算法是一种不完全的图搜索算法,通常在图的解空间比较大的情况下使用,同时在深度遍历图的过程中会删除一些质量较差的节点,减少了空间消耗,提高了时间效率。

它的核心思想是在解码的每个时间步,选择K个最可能的词作为下一步的翻译,K这里称为beam size。
假设字典为[a,b,c],beam size = 2:
-
在生成第1个词的时候,选择概率最大的2个词,那么当前序列就是a或b
-
生成第2个词的时候,我们将当前序列a或b,分别与字典中的所有词进行组合,得到新的6个序列aa、 ab 、ac、 ba 、bb 、bc,然后从其中选择2个概率最高的作为当前序列,即ab或bb
-
不断重复这个过程,直到遇到结束符为止。最终输出2个概率最高的序列。
在
y
1
,
.
.
.
,
y
t
y_{1},...,y_{t}
y1,...,yt的产生过程中,每个
y
i
y_{i}
yi都有一个分数,整个序列的得分为
score
(
y
1
,
…
,
y
t
)
=
log
P
L
M
(
y
1
,
…
,
y
t
∣
x
)
=
∑
i
=
1
t
log
P
L
M
(
y
i
∣
y
1
,
…
,
y
i
−
1
,
x
)
\operatorname{score}\left(y_{1}, \ldots, y_{t}\right)=\log P_{\mathrm{LM}}\left(y_{1}, \ldots, y_{t} | x\right)=\sum_{i=1}^{t} \log P_{\mathrm{LM}}\left(y_{i} | y_{1}, \ldots, y_{i-1}, x\right)
score(y1,…,yt)=logPLM(y1,…,yt∣x)=i=1∑tlogPLM(yi∣y1,…,yi−1,x)
其中所有的得分都是非负的,得分越高表示越好。但是集束搜索同样不能保证找到最优的目标序列,但是比穷举搜索更加有效。

EMNLP 2017 《Deep Recurrent Generative Decoder for Abstractive Text Summarization》
基于Encoder-Decode的Seq2Seq模型在文本摘要领域借助注意力机制可以取得不错的效果,但是这种方式的表示能力仍是有限的,它无法捕获到复杂的隐式的结构信息(latent structure information),例如摘要的句法结构和隐含主题等。因此作者希望借助生成模型强大的能力来学习到那些复杂的信息,这里使用的VAE。通过减小真实摘要所满足的分布和生成摘要所满足分布间的KL散度,使模型可以自动的学习到这些信息。

VAE在视觉领域有着很广泛的应用,特别是在图像生成中。但是它无法直接处理序列数据,因此作者这里引入历史潜在变量依赖关系,使其能够对序列数据建模。通过VAE和Seq2Seq模型的结合,作者提出了深度循环生成式解码器(deep recurrent generative decoder ,DRGD)。整个模型可以分为两个阶段:
- 推断阶段:变分编码器(variational-encoder)
- 生成阶段:变分解码器(variational-decoder)
通过这样的方式可以捕获到先前时间的隐结构信息,然后用它指导下一时刻的生成过程,最后可以得到质量更高的摘要。

在推断阶段,变分编码器可以将已生成的 y < t y_{<t} y<t和先前的隐结构信息 z < t z_{<t} z<t映射到关于隐结构变量的后验概率分布 p θ ( z t ∣ y < t , z < t ) p_{\theta}(z_{t}|y_{<t},z_{<t}) pθ(zt∣y<t,z<t)上。相比于标准的VAE p θ ( z t ∣ y t ) p_{\theta}(z_{t}|y_{t}) pθ(zt∣yt)而言,它得到的 z t z_{t} zt包含了已捕获的复杂且有效的隐式结构信息。
在生成阶段,根据 z t z_{t} zt计算时间步 t t t输出的目标词 y t y_{t} yt,即计算条件概率分布 p θ ( y t ∣ z t ) p_{\theta}(y_{t}|z_{t}) pθ(yt∣zt),那么完整的生成序列 y = { y 1 , y 2 , . . . , y T } y=\{y_{1},y_{2},...,y_{T}\} y={y1,y2,...,yT}就是最后的摘要。整个生成过程相当于最大化 p θ ( y ) = ∏ t = 1 T ∫ p θ ( y t ∣ z t ) p θ ( z t ) d z t p_{\theta}(y)=\prod_{t=1}^{T} \int p_{\theta}\left(\mathbf{y}_{t} | \mathbf{z}_{t}\right) p_{\theta}\left(\mathbf{z}_{t}\right) d \mathbf{z}_{t} pθ(y)=∏t=1T∫pθ(yt∣zt)pθ(zt)dzt。
但是上式的
p
θ
(
y
)
p_{\theta}(y)
pθ(y)通常是难以直接计算的,因此这里引入了一个识别模型(recognition model)
q
ϕ
(
Z
t
∣
y
<
t
,
Z
<
t
)
q_{\phi}\left(\mathbf{Z}_{t} | \mathbf{y}<t, \mathbf{Z}<t\right)
qϕ(Zt∣y<t,Z<t),它作为
p
θ
(
z
t
∣
y
<
t
,
z
<
t
)
p_{\theta}(z_{t}|y_{<t},z_{<t})
pθ(zt∣y<t,z<t) 的一个逼近,其中的
ϕ
\phi
ϕ 和
θ
\theta
θ可同时学习。根据VAE的原理,目标就是减小两个分布间的KL散度,即最小化下式的值。
D
K
L
[
q
ϕ
(
z
t
∣
y
<
t
,
z
<
t
)
∥
p
θ
(
z
t
∣
y
<
t
,
z
<
t
)
]
=
∫
z
q
ϕ
(
z
t
∣
y
<
t
,
z
<
t
)
log
q
ϕ
(
z
t
∣
y
<
t
,
z
<
t
)
p
θ
(
z
t
∣
y
<
t
,
z
<
t
)
d
z
=
E
q
ϕ
(
z
t
∣
y
<
t
,
z
<
t
)
[
log
q
ϕ
(
z
t
∣
⋅
)
−
log
p
θ
(
z
t
∣
⋅
)
]
\begin{array}{l}{D_{K L}\left[q_{\phi}\left(\mathbf{z}_{t} | \mathbf{y}_{<t}, \mathbf{z}_{<t}\right) \| p_{\theta}\left(\mathbf{z}_{t} | \mathbf{y}_{<t}, \mathbf{z}_{<t}\right)\right]} \\ {=\int_{z} q_{\phi}\left(\mathbf{z}_{t} | \mathbf{y}_{<t}, \mathbf{z}_{<t}\right) \log \frac{q_{\phi}\left(\mathbf{z}_{t} | \mathbf{y}_{<t}, \mathbf{z}_{<t}\right)}{p_{\theta}\left(\mathbf{z}_{t} | \mathbf{y}_{<t}, \mathbf{z}_{<t}\right)} d z} \\ {=\mathbb{E}_{q_{\phi}\left(\mathbf{z}_{t} | \mathbf{y}<t, \mathbf{z}_{<t}\right)}\left[\log q_{\phi}\left(\mathbf{z}_{t} | \cdot\right)-\log p_{\theta}\left(\mathbf{z}_{t} | \cdot\right)\right]}\end{array}
DKL[qϕ(zt∣y<t,z<t)∥pθ(zt∣y<t,z<t)]=∫zqϕ(zt∣y<t,z<t)logpθ(zt∣y<t,z<t)qϕ(zt∣y<t,z<t)dz=Eqϕ(zt∣y<t,z<t)[logqϕ(zt∣⋅)−logpθ(zt∣⋅)]
经过变换有
log
p
θ
(
y
<
t
)
=
D
K
L
[
q
ϕ
(
z
t
∣
y
<
t
,
z
<
t
)
∥
p
θ
(
z
t
∣
y
<
t
,
z
<
t
)
]
+
E
q
ϕ
(
z
t
∣
y
<
t
,
z
<
t
)
[
log
p
θ
(
y
<
t
∣
z
t
)
]
−
D
K
L
[
q
ϕ
(
z
t
∣
y
<
t
,
z
<
t
)
∥
p
θ
(
z
t
)
]
\begin{array}{l}{\log p_{\theta}(\mathbf{y}<t)=} \\ {D_{K L}\left[q_{\phi}\left(\mathbf{z}_{t} | \mathbf{y}<t, \mathbf{z}_{<t}\right) \| p_{\theta}\left(\mathbf{z}_{t} | \mathbf{y}_{<t}, \mathbf{z}_{<t}\right)\right]} \\ {+\mathbb{E}_{q_{\phi}\left(\mathbf{z}_{t} | \mathbf{y}<t, \mathbf{z}_{<t}\right)}\left[\log p_{\theta}\left(\mathbf{y}<t | \mathbf{z}_{t}\right)\right]} \\ {-D_{K L}\left[q_{\phi}\left(\mathbf{z}_{t} | \mathbf{y}<t, \mathbf{z}_{<t}\right) \| p_{\theta}\left(\mathbf{z}_{t}\right)\right]}\end{array}
logpθ(y<t)=DKL[qϕ(zt∣y<t,z<t)∥pθ(zt∣y<t,z<t)]+Eqϕ(zt∣y<t,z<t)[logpθ(y<t∣zt)]−DKL[qϕ(zt∣y<t,z<t)∥pθ(zt)]
上式右边的两项可记为
L
(
θ
,
φ
;
y
)
=
E
q
ϕ
(
z
t
∣
y
<
t
,
z
<
t
)
{
∑
t
=
1
T
log
p
θ
(
y
t
∣
z
t
)
−
D
K
L
[
q
ϕ
(
z
t
∣
y
<
t
,
z
<
t
)
∥
p
θ
(
z
t
)
]
}
\begin{array}{l}{\mathcal{L}(\theta, \varphi ; y)=} \\ {\quad \mathbb{E}_{q_{\phi}\left(\mathbf{z}_{t} | \mathbf{y}<t, \mathbf{z}_{<t}\right)}\left\{\sum_{t=1}^{T} \log p_{\theta}\left(\mathbf{y}_{t} | \mathbf{z}_{t}\right)\right.} \\ {\quad-D_{K L}\left[q_{\phi}\left(\mathbf{z}_{t} | \mathbf{y}<t, \mathbf{z}_{<t}\right) \| p_{\theta}\left(\mathbf{z}_{t}\right)\right] \}}\end{array}
L(θ,φ;y)=Eqϕ(zt∣y<t,z<t){∑t=1Tlogpθ(yt∣zt)−DKL[qϕ(zt∣y<t,z<t)∥pθ(zt)]}
它在这里提供了了一个关于
log
p
θ
(
y
<
t
)
\log p_{\theta}(\mathbf{y}<t)
logpθ(y<t)的下界。
在摘要生成的过程中,encoder使用的是双向的GRU,它将时间步
t
t
t的输入
x
t
x_{t}
xt和前一时刻的隐状态
h
t
−
1
h_{t-1}
ht−1映射到
h
t
h_{t}
ht,因为这里采用的是双向的方式,
h
t
h_{t}
ht由两部分表示:
h
→
t
=
G
R
U
(
x
t
,
h
→
t
−
1
)
h
^
t
=
G
R
U
(
x
t
,
h
^
t
−
1
)
\begin{array}{l}{\overrightarrow{\mathbf{h}}_{t}=G R U\left(x_{t}, \overrightarrow{\mathbf{h}}_{t-1}\right)} \\ {\hat{\mathbf{h}}_{t}=G R U\left(x_{t}, \hat{\mathbf{h}}_{t-1}\right)}\end{array}
ht=GRU(xt,ht−1)h^t=GRU(xt,h^t−1)
最后使用的
h
t
e
h_{t}^e
hte是两个方向隐状态的拼接,enocder部分相比于先前的模型并没有不同。
在decoder部分,除了先前已有的确定性解码过程,这里还增加了关于隐结构的生成建模过程。确定性解码过程中使用了两层GRU,隐状态 h 1 d h_{1}^d h1d使用所有输入隐状态的平均值初始化 h 1 d = 1 T e ∑ t = 1 T e h t e \mathbf{h}_{1}^{d}=\frac{1}{T^{e}} \sum_{t=1}^{T^{e}} \mathbf{h}_{t}^{e} h1d=Te1∑t=1Tehte。
第一层解码得到的隐状态为
h
t
d
1
=
G
R
U
1
(
y
t
−
1
,
h
t
−
1
d
1
)
\mathbf{h}_{t}^{d_{1}}=G R U_{1}\left(\mathbf{y}_{t-1}, \mathbf{h}_{t-1}^{d_{1}}\right)
htd1=GRU1(yt−1,ht−1d1),然后使用
h
t
d
1
h_{t}^{d_{1}}
htd1和输入的隐状态序列
{
h
t
e
}
\{h_{t}^e\}
{hte}来计算时间步
t
t
t注意力权重,用
a
i
,
j
a_{i,j}
ai,j表示。
a
i
,
j
=
exp
(
e
i
,
j
)
∑
j
′
=
1
T
e
exp
(
e
i
,
j
′
)
e
i
,
j
=
v
T
tanh
(
W
h
h
d
h
i
d
1
+
W
h
h
e
h
j
e
+
b
a
)
\begin{aligned} a_{i, j} &=\frac{\exp \left(e_{i, j}\right)}{\sum_{j^{\prime}=1}^{T^{e}} \exp \left(e_{i, j^{\prime}}\right)} \\ e_{i, j} &=\mathbf{v}^{T} \tanh \left(\mathbf{W}_{h h}^{d} \mathbf{h}_{i}^{d_{1}}+\mathbf{W}_{h h}^{e} \mathbf{h}_{j}^{e}+\mathbf{b}_{a}\right) \end{aligned}
ai,jei,j=∑j′=1Teexp(ei,j′)exp(ei,j)=vTtanh(Whhdhid1+Whhehje+ba)
所有输入的隐状态的加权线性组合就是基于注意力的上下文向量
c
t
c_{t}
ct。
c
t
=
∑
j
′
=
1
T
e
a
t
,
j
′
h
j
′
e
\mathbf{c}_{t}=\sum_{j^{\prime}=1}^{T^{e}} a_{t, j^{\prime}} \mathbf{h}_{j^{\prime}}^{e}
ct=j′=1∑Teat,j′hj′e
然后根据
c
t
c_{t}
ct和已生成的序列
y
t
−
1
y_{t-1}
yt−1及前一时刻的隐状态
h
t
−
1
d
2
h_{t-1}^{d_{2}}
ht−1d2生成第二层GRU在时间步
t
t
t的隐状态
h
t
d
2
=
G
R
U
2
(
y
t
−
1
,
h
t
−
1
d
2
,
c
t
)
\mathbf{h}_{t}^{d_{2}}=G R U_{2}\left(\mathbf{y}_{t-1}, \mathbf{h}_{t-1}^{d_{2}}, \mathbf{c}_{t}\right)
htd2=GRU2(yt−1,ht−1d2,ct)。当目前为止,所有部分的计算都和先前的Encoder-decoder模型一样。
在隐结构的生成建模过程中,假设关于隐变量的先验分布和后验分布都满足高斯分布,当有了
y
t
−
1
、
z
t
−
1
、
h
d
t
−
1
y_{t-1}、z_{t-1}、h_{d}^{t-1}
yt−1、zt−1、hdt−1后,首先计算
h
t
e
z
=
g
(
W
y
h
e
z
y
t
−
1
+
W
z
h
e
z
z
t
−
1
+
W
h
h
e
z
h
t
−
1
d
+
b
h
e
z
)
\mathbf{h}_{t}^{e_{z}}=g\left(\mathbf{W}_{y h}^{e z} \mathbf{y}_{t-1}+\mathbf{W}_{z h}^{e_{z}} \mathbf{z}_{t-1}+\mathbf{W}_{h h}^{e_{z}} \mathbf{h}_{t-1}^{d}+\mathbf{b}_{h}^{e_{z}}\right)
htez=g(Wyhezyt−1+Wzhezzt−1+Whhezht−1d+bhez)
再将其映射到一个新的隐式空间中,然后计算高斯分布的参数
μ
t
=
W
h
μ
e
z
h
t
e
z
+
b
μ
e
z
log
(
σ
t
2
)
=
W
h
σ
h
t
e
z
+
b
σ
e
z
\begin{aligned} \boldsymbol{\mu}_{t} &=\mathbf{W}_{h \mu}^{e_{z}} \mathbf{h}_{t}^{e_{z}}+\mathbf{b}_{\mu}^{e_{z}} \\ \log \left(\boldsymbol{\sigma}_{t}^{2}\right) &=\mathbf{W}_{h \sigma} \mathbf{h}_{t}^{e_{z}}+\mathbf{b}_{\sigma}^{e_{z}} \end{aligned}
μtlog(σt2)=Whμezhtez+bμez=Whσhtez+bσez
那么
z
t
z_{t}
zt就可以表示为
z
t
=
μ
t
+
σ
t
⊗
ε
\mathbf{z}_{t}=\boldsymbol{\mu}_{t}+\boldsymbol{\sigma}_{t} \otimes \varepsilon
zt=μt+σt⊗ε,其中
ϵ
\epsilon
ϵ满足标准高斯分布。最后根据
z
t
z_{t}
zt和
h
t
d
2
h_{t}^{d_{2}}
htd2计算
h
t
d
y
=
tanh
(
W
z
h
d
y
z
t
+
W
h
h
d
z
h
t
d
2
+
b
h
d
y
)
\mathbf{h}_{t}^{d_{y}}=\tanh \left(\mathbf{W}_{z h}^{d_{y}} \mathbf{z}_{t}+\mathbf{W}_{h h}^{d_{z}} \mathbf{h}_{t}^{d_{2}}+\mathbf{b}_{h}^{d_{y}}\right)
htdy=tanh(Wzhdyzt+Whhdzhtd2+bhdy),那么输入
y
t
y_{t}
yt可由
y
t
=
ζ
(
W
h
y
d
h
t
d
y
+
b
h
y
d
)
\mathbf{y}_{t}=\zeta\left(\mathbf{W}_{h y}^{d} \mathbf{h}_{t}^{d_{y}}+\mathbf{b}_{h y}^{d}\right)
yt=ζ(Whydhtdy+bhyd)计算而得。为了得到最优的摘要结果,这里同样使用了beam search。那么两阶段的训练目标可以表示为:
J
=
1
N
∑
n
=
1
N
∑
t
=
1
T
{
−
log
[
p
(
y
t
(
n
)
∣
y
<
t
(
n
)
,
X
(
n
)
)
]
+
D
K
L
[
q
ϕ
(
z
t
(
n
)
∣
y
<
t
(
n
)
,
z
<
t
(
n
)
)
∥
p
θ
(
z
t
(
n
)
)
]
}
\begin{aligned} \mathcal{J}=& \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T}\left\{-\log \left[p\left(y_{t}^{(n)} | y_{<t}^{(n)}, X^{(n)}\right)\right]\right.\\ &+D_{K L}\left[q_{\phi}\left(\mathbf{z}_{t}^{(n)} | \mathbf{y}_{<t}^{(n)}, \mathbf{z}_{<t}^{(n)}\right) \| p_{\theta}\left(\mathbf{z}_{t}^{(n)}\right)\right] \} \end{aligned}
J=N1n=1∑Nt=1∑T{−log[p(yt(n)∣y<t(n),X(n))]+DKL[qϕ(zt(n)∣y<t(n),z<t(n))∥pθ(zt(n))]}
等式右边的第一项就是似然函数的计算,第二项为引入VAE的计算部分。
ACL 2017 《Get To The Point: Summarization with Pointer-Generator Networks》
基于Seq2Seq的模型虽然在文本摘要领域取得了不错的效果,但是它仍有如下的不足:
- 无法准确表述原文的细节信息
- 易生成重复的部分
- 无法解决out-of-vocabulary(OOV)问题
为了解决上述的问题,作者提出了一种增强的Seq2Seq框架。首先使用混合的pointer-generator 网络通过pointing机制准确的从原文中复制信息,同时又不损坏generator生成新词的能力;另外使用coverage机制降低生成部分的重复率。
模型的整体架构如下所示

Pointer-generator 网络是一种指针网络(pointer network)和基于注意力机制的Seq2Seq网络的混合模型,它既保证了既从原文中直接复制词又可以从词汇表中生成新词,从而在一定程度上解决了上述的问题。
它除了需要计算注意力分布
a
t
a^t
at和上下文向量
h
t
∗
h_{t}^*
ht∗外,还需根据
t
t
t时刻的
h
t
∗
h_{t}^*
ht∗、decoder的隐状态
s
t
s_{t}
st和decoder的输入
x
t
x_{t}
xt计算生成概率
p
g
e
n
=
σ
(
w
h
∗
T
h
t
∗
+
w
s
T
s
t
+
w
x
T
x
t
+
b
p
t
r
)
p_{\mathrm{gen}}=\sigma\left(w_{h^{*}}^{T} h_{t}^{*}+w_{s}^{T} s_{t}+w_{x}^{T} x_{t}+b_{\mathrm{ptr}}\right)
pgen=σ(wh∗Tht∗+wsTst+wxTxt+bptr)
且
p
g
e
n
∈
[
0
,
1
]
p_{gen} \in [0,1]
pgen∈[0,1]。
p
g
e
n
p_{gen}
pgen这里作为一种软开关机制,用于控制是从注意力分布中进行采样还是从词汇表中生成新词。
另外对于每一个处理的文档都会生成一个扩展的词汇表(extended vocabulary),它表示了词汇表和源文档中出现的所有单词的组合,然后就可以得到关于扩展词汇表的概率分布
P
(
w
)
=
p
g
e
n
P
v
o
c
a
b
(
w
)
+
(
1
−
p
g
e
n
)
∑
i
:
w
i
=
w
a
i
t
P(w)=p_{\mathrm{gen}} P_{\mathrm{vocab}}(w)+\left(1-p_{\mathrm{gen}}\right) \sum_{i : w_{i}=w} a_{i}^{t}
P(w)=pgenPvocab(w)+(1−pgen)i:wi=w∑ait
其中如果
w
w
w是OOV词,那么
p
v
o
c
a
b
(
w
)
p_{vocab}(w)
pvocab(w)值为零;同理如果
w
w
w并没有出现在源文档中,那么
∑
i
:
w
i
=
w
a
i
t
\sum_{i:w_{i}=w}a_{i}^t
∑i:wi=wait也为零。
除了模型的混合外,Pointer-generator网络的另一个强大的机制就是覆盖(coverage),它的提出只要是为了解决Seq2Seq模型中存在的重复率高的问题。通过所有时间步上注意力分布的和计算覆盖向量
c
t
=
∑
t
′
=
0
t
−
1
a
t
′
c^t = \sum_{t'=0}^{t-1}a^{t'}
ct=∑t′=0t−1at′,它表示了当前时刻这些词从注意力机制获得的覆盖程度。然后将其做为注意力机制计算的一个输入项,计算
P
v
o
c
a
b
=
softmax
(
V
′
(
V
[
s
t
,
h
t
∗
]
+
b
)
+
b
′
)
P_{\mathrm{vocab}}=\operatorname{softmax}\left(V^{\prime}\left(V\left[s_{t}, h_{t}^{*}\right]+b\right)+b^{\prime}\right)
Pvocab=softmax(V′(V[st,ht∗]+b)+b′)
这样将使注意力机制更注意避免重复注意相同位置的信息,从而避免生成重复的文本。
coverage loss表示为
c
o
v
l
o
s
s
t
=
∑
i
min
(
a
i
t
,
c
i
t
)
covloss_{t}=\sum_{i} \min(a_{i}^t,c_{i}^t)
covlosst=i∑min(ait,cit)
它提供了一个下界,满足
covloss
t
≤
∑
i
a
i
t
=
1
\text{covloss}_{t} \leq \sum_{i} a_{i}^t = 1
covlosst≤∑iait=1。模型完整的损失函数为
l
o
s
s
t
=
−
log
P
(
w
t
∗
)
+
λ
∑
i
min
(
a
i
t
,
c
i
t
)
loss_{t}=-\log P(w_{t}^*)+\lambda \sum_{i} \min(a_{i}^t,c_{i}^t)
losst=−logP(wt∗)+λi∑min(ait,cit)
示例
abstractive summarization仍存在的问题:
- 生成摘要仍很接近源文档,难以生成高级别压缩释义的摘要
- 模型有时并不会关注于文档中的关键信息
- 网络有时会错误的组合源文档中的片段
- 难以很好的将多句话用一个有意义的句子表述
- …
实验结果实例

补充
pointer network
指针网络(Pointer Network)是Seq2seq模型的一个变种。它不是把一个序列转换成另一个序列, 而是产生一系列指向输入序列元素的指针,常用的应用包括凸包问题、旅行商问题等。
Seq2Seq模型很大的一个问题是输出严重依赖输入,如何理解这个问题呢?下面通过论文中的例子说明,假设在二维空间 [ 0 , 1 ] × [ 0 , 1 ] [0,1] \times [0,1] [0,1]×[0,1]中存在一些点,如何求这些点的凸包?简单来说就是如何找到几个点能把所有的这些点包起来。例如模型的输入为 { P 1 , P 2 , . . . , P 10 } \{P_{1},P_{2},...,P_{10}\} {P1,P2,...,P10},输出是凸包 { P 2 , P 4 , P 3 , P 5 P 6 , P 7 , P 2 } \{P_{2},P_{4},P_{3},P_{5}P_{6},P_{7},P_{2}\} {P2,P4,P3,P5P6,P7,P2}。从中可以看出输出中的元素是从输入序列中提取出来的。

凸包的求解可看作是从输入序列中提取点的过程,而选点的方法就称为pointer,它并不像注意力机制那样将输入通过encoder得到上下文向量,而是将注意力转化为一个pointer来选择输入序列中的元素,即在计算完注意力权重后选择概率最大的encoder状态作为输出。指针网络和Seq2Seq网络的模型对比如下

NACCL 2016 《Abstractive Sentence Summarization with Attentive Recurrent Neural Networks》
它是《A Neural Attention Model for Abstractive Sentence Summarization》的进阶版,作者提出了一种条件循环神经网络。模型同样是基于Encoder-Decoder的结构,但不同的是在Encoder部分采用的是基于注意力机制的卷积网络。这样的架构使得Decoder可以在每一时刻的生成过程只关注在适当的输入词上,模型只依赖学到的特征,并且可以在大规模数据集上进行端到端的训练。
ICML 2017 《Convolutional Sequence to Sequence Learning》
ConvS2S模型由FAIR在2017年提出,它主要应用于机器翻译任务,并在当时的英-德、英-法两个任务上都达到了state-of-the-art。在本文中,作者将其应用了文本摘要中也取得了不错的效果。
采用CNN做Seq2Seq任务的优势在于:
- 通过卷积运算可以精确的控制上下文的长度
- 卷积可以并行运算
- 对于每一个输入的词而言,在CNN中经过的卷积核和非线性计算数量都是固定的
模型的架构如下

在Embedding部分除了常规的词嵌入或语义嵌入
w
=
{
w
1
,
.
.
.
,
w
m
}
w=\{w_{1},...,w_{m}\}
w={w1,...,wm}外,这个还增加了position embedding,将词序表示为分布式向量
p
=
{
p
1
,
.
.
,
p
m
}
p=\{p_{1},..,p_{m}\}
p={p1,..,pm},使模型获得词序和位置信息,最后的embedding是语义嵌入和词序嵌入的求和。
e
=
(
w
1
+
p
1
,
.
.
.
,
w
m
+
p
m
)
e=(w_{1}+p_{1},...,w_{m}+p_{m})
e=(w1+p1,...,wm+pm)
然后将词嵌入输入到卷积模块中,文中所采用的卷积模块可看作经典的卷积加上非线性转换。其中非线性转换被称为Gated Linear Unit(GLU),它将卷积后的结果分为两部分,其中一部分做Sigmoid转换,另一部分向量进行element-wise乘积。
v
(
[
A
,
B
]
=
(
X
∗
W
+
b
)
⨂
σ
(
X
∗
V
+
b
)
)
v([A,B] = (X * W+b) \bigotimes \sigma(X * V+b))
v([A,B]=(X∗W+b)⨂σ(X∗V+b))
作者还使用了残差连接(residual connection),用于缓解深层网络中的梯度消失问题。
除了加强的卷积网络外,模型欢迎入了带多跳结构的注意力机制(multi-step attention),它不仅要求decoder的最后一层卷积块关注输入和输出信息,而且要求每一层的卷积块都执行同样的注意力机制,这样可以使模型获得更多的历史信息。

经过实验证明CNN同样可用于文本领域,通过层级表征长程依赖。同时由于CNN并行化的优点,它的训练要比RNN快;不足之处在于CNN有更多的参数要调。
在整个过程中参考了很多网上的资料,由于忘记保存链接,这里就给出参考资料地址了,衷心感谢他人的付出~














 806
806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









