






文章目录
第六章 建模与性能评价
6.1 统计建模
统计建模的实质:描述统计+推断统计(参数估计、假设检验)
(1)基本概念回顾
概率分布函数F(x):给出取值小于某个值的概率,是概率的累加形式
概率密度函数f(x):给出了变量落在某值邻域内(或者某个区间内)的概率变化快慢,概率密度函数的值不是概率,而是概率的变化率,概率密度函数下面的面积才是概率
(2)常见的概率密度函数
概率密度函数PDF:f(x)f(x)用来表示连续随机变量落在各值附近的可能性,给定f(x)f(x)后,X的一次抽样落入某区间的概率就等于概率密度函数f(x)f(x)在该区间上的积分,即
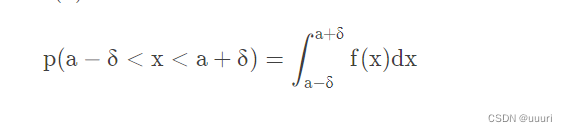
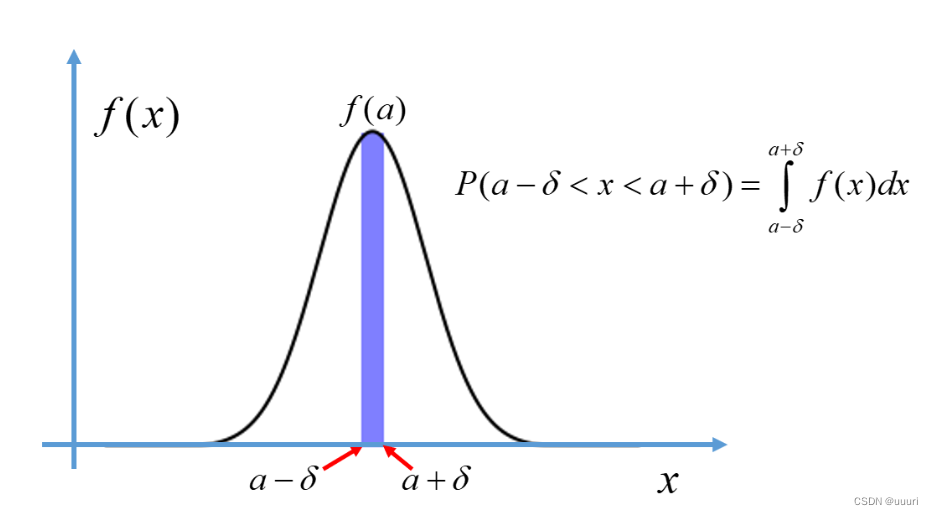

2.正态分布(高斯分布):概率密度函数为
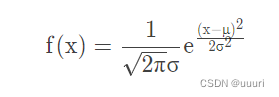
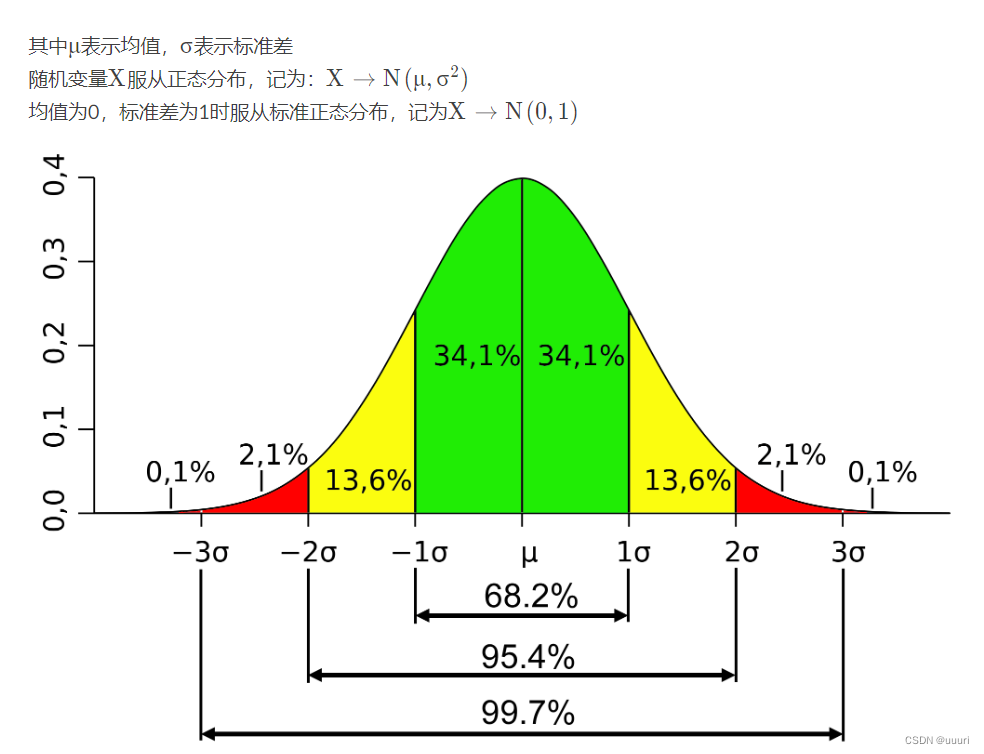

3.t分布(学生t分布):
根据小样本来估计呈正态分布且方差未知的总体均值。样本容量小于30时,样本均值不符合正态分布,则可以将均值标准化后构造一个统计量t,统计量t是符合t分布的,在t分布中做均值估计和区间估计。
构造统计量t:
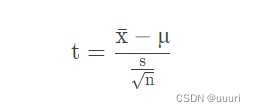
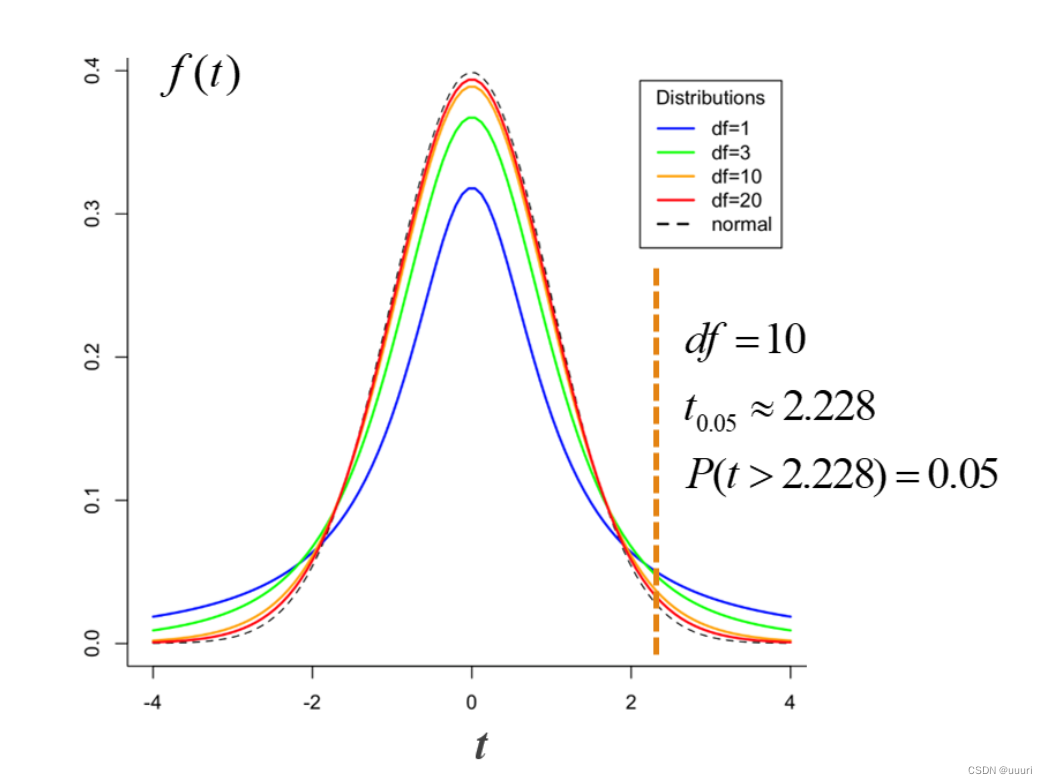
t分布的概率密度函数是由自由度df控制的一簇曲线,t分布的自由度是样本容量n-1,曲线关于t=0对称,样本容量越小,曲线越平坦;样本容量越大,曲线越接近正态分布。(小样本估计依据)
4.卡方分布
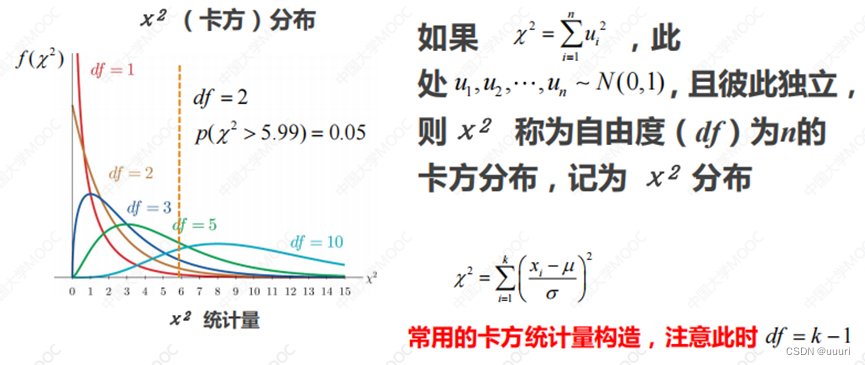
3.参数估计
基于样本统计量X/E(X)或s而对总体分布参数μ或σ进行估计
①均值点估计:
依据中心极限定律,来源于同一总体的独立随机抽样的算术平均服从均值μ的正态分布,所以样本的统计均值就是总体均值的无偏估计,记为:
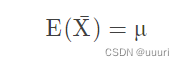
from random import sample
import numpy as np
import pandas as pd
from scipy import stats # python的stats模块提供了大量统计学常用函数
np.random.seed(1234) # 设置随机数种子方便实验结果的复现
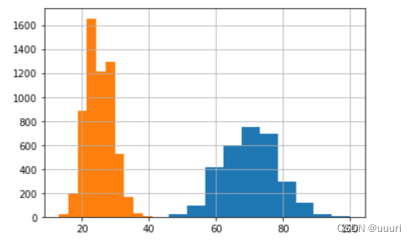
my_data1 = stats.poisson.rvs(loc = 10, mu = 60, size = 3000) # 生成一个规定均值的泊松分布
pd.Series(my_data1).hist().get_figure().show # 作直方图展示
print("第一个均值分布是:70,\t统计平均是:", my_data1.mean()) # 均值人为规定,统计平均直接计算,看是否和指定的均值一致
my_data2 = stats.poisson.rvs(loc = 10, mu = 15, size = 6000)
pd.Series(my_data1).hist().get_figure().show
print("第一个均值分布是:25,\t统计平均是:", my_data2.mean())
my_data = np.concatenate((my_data1, my_data2)) # numpy.ndarray对象的连接
print("总体的均值为:", my_data.mean())
sample_data = np.random.choice(a = my_data, size = 100) # 从总体中取100个样本计算样本均值
print("样本的均值为:", sample_data.mean())
'''
输出结果
第一个均值分布是:70, 统计平均是: 69.97966666666666
第一个均值分布是:25, 统计平均是: 25.009333333333334
总体的均值为: 39.99944444444444
样本的均值为: 39.3
'''
以上代码用到的具体方法:
np.random.seed()方法:用于指定随机数生成时所用算法开始的整数值,如果使用相同的值,则每次生成的随机数都相同
np.concatenate()方法:用于连接 np.ndarray 对象 pd.Series( )方法:将一个列表、np.ndarray 对象转化为 pandas.Series 对象
np.random.choice( a, size = )方法:从a随机抽取数字,并组成指定 size的数组 具体参数:
a np.ndarray 对象
size 整数 指定抽取样本的个数
stats.poisson.rvs( loc = , mu = , size = )方法:从泊松分布中生成指定个数的随机数,rvs 表示产生服从指定分布的随机数
具体参数:
loc 与 mu 两者共同决定这个分布的均值(两者之和) size 整数 生成随机数的个数
验证中心极限定律
point_estimates = [] # 一个列表,用于存放每次抽样的样本均值
for x in range(500):
sample = np.random.choice(a = my_data, size = 100) # 抽取100个样本
point_estimates.append(sample.mean()) # 计算样本的均值并存入列表
pd.DataFrame(point_estimates).hist(bins = 40) # 将列表转换为pandas.DataFrame对象后画直方图展示
print("样本均值的均值为:", np.array(point_estimates).mean()) # 将列表转化为np.ndarray对象后可以利用mean()方法计算平均值
'''
输出结果
样本均值的均值为: 39.95712
'''
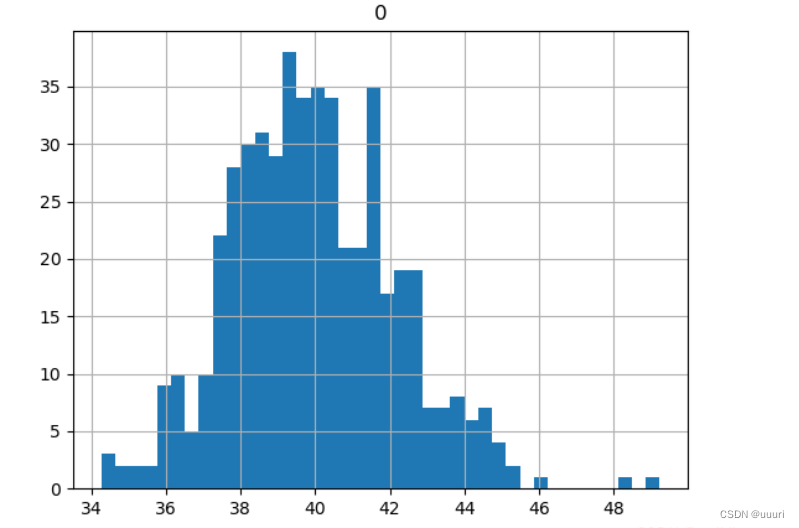 样本均值趋于正态分布
样本均值趋于正态分布
②均值区间估计:
对于总体进行的独立随机抽样,样本均值会分布在一个范围里,对于一个给定的置信水平,就可以求得一个置信区间
sample = np.random.choice(a = my_data, size = 100)
sigma = sample.std()/(sample_size) ** 0.5 # 构造t统计量的分母
print(stats.t.interval(alpha = 0.95, df = sample_size - 1, loc = sample.mean(), scale = sigma)) # 求置信区间
'''
输出结果
(36.29263468910625, 45.26736531089375)
'''
以上代码用到的方法:
stats.t.interval( alpha = , df = , loc = , scale = )方法:用于针对t分布求置信区间
具体参数如下
alpha 浮点数 代表置信水平
df 整数 代表t分布的自由度,一般取样本容量-1
loc 浮点数 代表构造t统计量需要的样本均值
scale 浮点数 代表构造t统计量需要的分母sigma

4.假设检验
通常做法是:提出一个假设,验证是否可以接受该假设
假设检验的基本思想:反证法
在假定某个假设是正确的情况下构造一个小概率事件,如果在一次试验里小概率事件发生了,则拒绝这个假设
假设检验的相关概念:
Ⅰ空假设\零假设:待检验的假设,用H0
表示(一般事物的惯常态,概率大)
TIP:常见的零假设:总体的均值等于μ;测试组和对照组来源于均值相等的总体;控制因素对观察变量没有影响,A组和B组数据同分布
Ⅱ替代假设\备择假设:空假设的对立,用H1
表示(概率小)
TIP:常见的备择假设:总体的均值不等于μ;测试组和对照组来源于均值不等的总体;控制因素对观察变量有影响,A组和B组数据不同分布
Ⅲ显著性水平:统计检验时需要将从样本获取的统计量与显著性水平比较(p值与alpha值的比较),一般人为定义(取0.05)
假设检验的一般步骤:
①确定总体和sample size(适中)
②收集数据
③确定H0 和H1
④设置显著性水平alpha
⑤选择并计算相应的统计量,进行假设检验
⑥根据统计量或假设检验的p值与显著性水平的比较决定拒绝或接受H0

假设检验类型:
①t检验—均值的单样本检验:对单组样本的均值进行假设检验
t检验:借助t统计量服从t分布
Ⅰ.单样本双边均值检验:
假设H0:总体均值等于μ
对应H1:总体均值不等于\muμ
Ⅱ.单样本单边均值检验:将不等于换成大于或小于
单样本双边均值检验代码举例:
import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
from scipy.stats import t # t检验
# 生成一个含有9000样本的总体
np.random.seed(1234)
my_data1 = stats.poisson.rvs(loc = 10, mu = 60, size = 3000)
my_data2 = stats.poisson.rvs(loc = 10, mu = 15, size = 6000)
my_data = np.concatenate((my_data1, my_data2))
# 假设
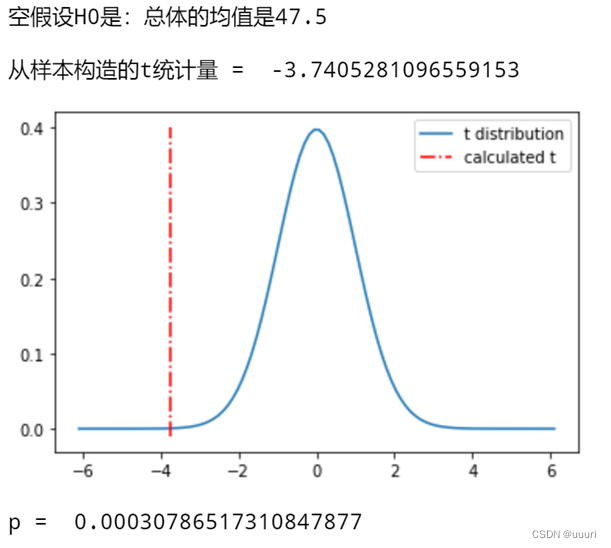
print("空假设H0是:总体的均值是47.5\n") # 假设的总体均值可由(70+25)/2得来
# 检验
sample_data = np.random.choice(a = my_data, size = 100) # 抽样
t_statistic, p_value = stats.ttest_1samp(a = sample_data, popmean = 47.5) # 计算得到t统计量和p值
print("从样本构造的t统计量 = ", t_statistic)
print("p = ", p_value)
# 画出t分布图像
df = 100 - 1 # 设置自由度
x = np.linspace(stats.t.ppf(0.00000001, df), stats.t.ppf(0.99999999, df), 100)
plt.plot(x, t.pdf(x, df))
str_legend = ("t distribution", "calculated t")
plt.legend(str_legend)
plt.show()
'''
输出结果
空假设H0是:总体的均值是47.5
从样本构造的t统计量 = -3.7405281096559153
p = 0.00030786517310847877
'''
以上代码用到的具体方法:
stats.ttest_1samp( a = , popmean = )方法:返回a样本集的t统计量与p值,一般用两个变量t_statistic和p_value去接收
具体参数:
a np.ndarray 对象 代表样本集
popmean 浮点数 代表零检验中的期望值
np.linspace(start, end, num = )方法:用于在线性空间中以均匀步长生成数字序列
具体参数:
start 范围起始
end 范围结束
num 序列中的总点数
stats.t.ppf( )方法:用来求分位点(在图像中确定了曲线边界)
stats.t.pdf( )方法:用来生成概率密度函数表(在图像中对应了纵坐标)
plt.legend( legend = )方法:用于定义图例
具体参数:
legend 元组 内含图例的名字
alpha = 0.05 # 人为定义alpha值
if p_value > 0.05:
print("接受 H0")
else:
print("拒绝 H0, 即总体的均值不等于47.5, 此时错误拒绝H0的概率为", p_value, "小于显著性水平")
'''
输出结果
拒绝 H0,即总体的均值不等于47.5, 此时错误拒绝H0的概率为0.00030786517310847877 小于显著性水平
'''
②t检验—均值的双样本检验:两组数据间的均值比较

import numpy as np
import pandas as pd
from scipy import stats
import matplotlib.pyplot as plt
from scipy.stats import t
# 构造一个总体
np.random.seed(1234)
my_data1 = stats.poisson.rvs(loc = 10, mu = 60, size = 3000)
my_data2 = stats.poisson.rvs(loc = 10, mu = 15, size = 6000)
my_data = np.concatenate((my_data1, my_data2))
# 构造两组样本,存放于字典
my_sample = {}
for n in range(2):
my_sample[n] = np.random.choice(a = my_data, size = 100)
print("第", n, "组样本的均值为",my_sample[n].mean())
# 双样本均值检验
alpha = 0.01 # 人为规定置信水平
t_statistic, p_value = stats.ttest_rel(a = my_sample[0], b = my_sample[1]) # 计算得到t统计量和p值(这里假设不知道总体的方差是否相等,所以优先取用ttest_rel方法)
print("t = ", t_statistic)
print("p = ", p_value)
if p_value <= alpha:
print("拒绝 H0:两样本来源的总体均值相等")
else:
print("接受 H0:两样本来源的总体均值相等")
'''
输出结果
第 0 组样本的均值为 39.3
第 1 组样本的均值为 41.14
t = -0.5797156447793128
p = 0.5634233550606107
接受 H0:两样本来源的总体均值相等
'''
③z检验:当样本容量大于30或样本容量小于30但已知潜在总体服从正态分布时,t分布由正态分布取代,t检验也由z检验取代
④卡方检验:研究两组类别型数据在某一特征上的概率分布是否一致时,通常利用卡方检验
假设H0:组A的分布与组B一致
对应H1:组A与分布与组B不一致
举例:检验titanic数据中幸存者是否是女多男少时,则只需要比较幸存者在性别特征的两个分类别(男、女)的分布情况,则可以做出如下假设:
假设H0 :幸存者中的性别分布与船上所有人的性别分布一致
对应H1:幸存者中的性别分布与船上所有人的性别分布不一致
import numpy as np
import pandas as pd
from scipy import stats
from scipy.stats import chi2 # 卡方检验
titanic = pd.read_csv("titanic.csv")
# 计算船上所有人的男女比例
mask1 = titanic["Sex"] == "male" # 返回的是pandas.Series对象
mask2 = titanic["Sex"] == "female"
p = np.array([sum(mask1) / (sum(mask1) + sum(mask2)), sum(mask2) / (sum(mask1) + sum(mask2))])
print("船上的男女比例为:", p)
mask_survived = titanic["Survived"] == 1 # 返回的是pandas.Series对象,内含索引号与一个布尔类型,代表是否存活
my_survived = titanic.loc[mask_survived, 'Sex'] # 获取指定行,loc里面的mask_survived代表指定的行索引,'Sex'是需要获取的内容,得到的是pandas.Series对象,只含有行序号和性别
pop_size = my_survived.count()
print("存活的人共有:", pop_size)
E = pop_size * p
print("预期的男、女个数为:", E)
mask1 = my_survived == "male" # 得到一个pandas.Series对象,内含索引号与一个布尔类型,代表是否是男性
mask2 = my_survived == "female"
my_set1 = my_survived[mask1]
my_set2 = my_survived[mask2]
O = np.array([len(my_set1), len(my_set2)])
print("实际的男、女个数为:", O)
chi_squard, p_value = stats.chisquare(f_obs = O, f_exp = E) # 卡方检验,得到卡方统计量与p值
print("卡方检验的p = ", p_value)
a = 0.05 # 人为规定的置信水平
if p_value <= a:
print("拒绝 男性、女性具有相同生存率的假设")
else:
print("接受 男性、女性具有相同生存率的假设")
'''
输出结果
船上的男女比例为: [0.64758698 0.35241302]
存活的人共有: 342
预期的男、女个数为: [221.47474747 120.52525253]
实际的男、女个数为: [109 233]
卡方检验的p = 3.970516389658729e-37
拒绝 男性、女性具有相同生存率的假设(逃生时确实做到女士优先)
'''
以上代码用到的具体方法:
stats.chisquare( f_obs = , f_exp = )方法:返回卡方统计量与p值,一般用两个变量chi_squard和p_value去接收
具体参数:
f_obs 数组 在每个类别中观察的频率
f_exp 数组 在每个类别中预期的频率
5.p-hacking
即便p<alpha,拒绝空假设还是存在错误拒绝的风险,错误拒绝的概率为p
即便空假设成立,当随机尝试100种不同的特征时,出现5个落入拒绝域的特征也是完全合理的
避免过度挖掘数据——p-hacking(操作p值)
6.2 回归模型
回归指建立因变量y与自变量x之间的函数关系:

代表用f获得的对y的估计(或预测)
回归分类:
一元回归:x只包含一个特征
多元回归:x包含多个特征
线性回归:函数关系f是线性的
非线性回归:函数关系f是非线性的
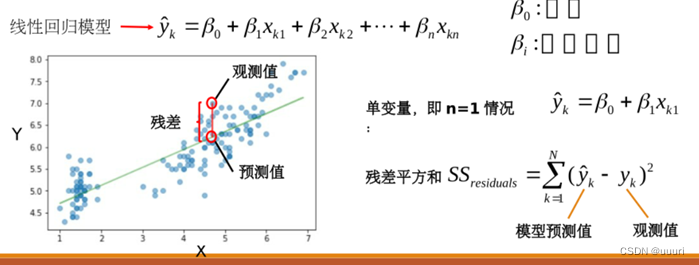
(1)线性回归模型:一元线性回归为例
建立因变量y与一维特征xx的线性函数关系:


import numpy as np
import pandas as pd
from scipy import stats
from matplotlib import pyplot as plt
from sklearn import metrics
from sklearn.linear_model import LinearRegression # 线性回归需要导入的库
from torch import alpha_dropout
# 读取数据
my_iris = pd.read_csv("iris.csv", sep = ',', decimal = '.', header = None, names = ["sepal_length", "sepal_width", "petal_length", "petal_width", "target"])
x = my_iris[["petal_length"]] # 提取需要的特征列,返回pandas.DataFrame对象
y = np.array(my_iris["sepal_length"]) # 提取目标列,返回np.ndarray对象
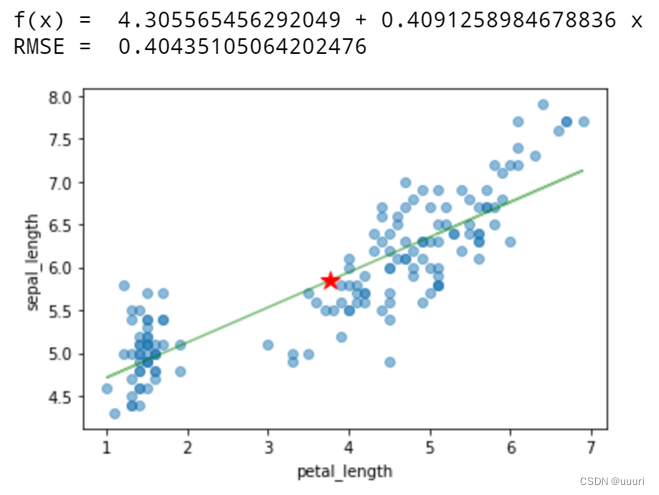
plt.plot(x, y, alpha = 0.5) # 绘制这些数据点
linreg = LinearRegression() # 创建一个线性回归模型实例
linreg.fit(x, y) # 模型训练
print("f(x) = ", linreg.intercept_, "+", linreg.coef_[0], "x") # 把回归系数和截距以公式的形式显示
pred_y = linreg.predict(x) # 模型预测
plt.plot(x, pred_y, 'g', alpha = 0.5) # 将预测曲线也画在图上
plt.plot(np.array(x).mean(), y.mean(), "r*", ms = 12) # 把回归直线必过的点用五角星强调
plt.gca().set_xlabel(feature_cols)
plt.gca().set_ylabel("sepal_length")
print("RMSE = ", np.sqrt(metrics.mean_squared_error(y, pred_y))) # 计算RMSE并输出
'''
输出结果
f(x) = 4.305565456292049 + 0.4091258984678836 x
RMSE = 0.40435105064202476
'''
以上代码用到的方法
LinearRegression( )方法:创建一个线性回归模型的实例
模型实例.fit(x, y)方法:用于模型训练,x代表特征,y代表目标
模型实例.predict(x)方法:用于预测,x代表预测对象的特征
线性回归模型的intercept_属性:代表截距
线性回归模型的linreg.coef_[0]属性:代表回归系数
metrics.mean_squared_error( y_true, y_pred )方法:计算均方误差,y_true代表真实值,y_pred代表预测值,返回np.float64类型
np.sqrt( )方法:计算给定数组中每个元素的平方根
(2)线性回归模型性能评价标准
print("r_square = ", linreg.score(x, y))
'''
输出结果
r_square = 0.7599553107783261
'''
以上代码用到的方法:
模型实例.score( )方法:返回模型的评价分数
在线性回归模型中评价分数就是决定系数
(3)线性回归与线性相关
线性回归中的决定系数就是线性相关系数的平方
print(my_iris[[feature_cols, "sepal_length"]].corr()) # 求两两特征的线性相关系数
r = np.array(my_iris[[feature_cols, "sepal_length"]].corr()[["sepal_length"]].iloc(0)[0]) # 完成提取后仍是np.ndarray对象
print("r = ", r)
print("square of r = ", r ** 2)
'''
输出结果
petal_length sepal_length
petal_length 1.000000 0.871754
sepal_length 0.871754 1.000000
r = [0.87175416]
square of r = [0.75995531]
'''
(4)逻辑回归模型
基于一个或多个量化特征/自变量直接预测某件事发生的概率,由于概率取值0~1,故采用Logistic函数(Logistic函数输出预测变量——某事发生概率)

import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
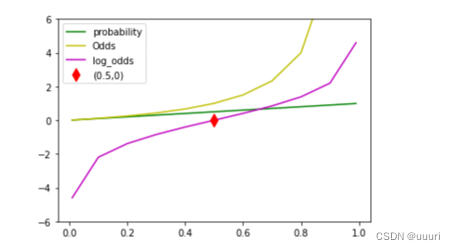
table = pd.DataFrame({'prob':[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.99]})
table['odds'] = table['prob'] / (1 - table['prob'])
table['log-odds'] = np.log(table['odds'])
print(table)
plt.plot(table['prob'], table['prob'], 'g')
plt.plot(table['prob'], table['odds'], 'y')
plt.plot(table['prob'], table['log-odds'], 'm')
plt.plot(0.5, 0, 'dr', ms = 10)
plt.ylim([-6, 6])
plt.legend(['probability', 'Odds', 'log_odds', '(0.5, 0)'])
plt.show()
'''
输出结果
prob odds log-odds
0 0.10 0.111111 -2.197225
1 0.20 0.250000 -1.386294
2 0.30 0.428571 -0.847298
3 0.40 0.666667 -0.405465
4 0.50 1.000000 0.000000
5 0.60 1.500000 0.405465
6 0.70 2.333333 0.847298
7 0.80 4.000000 1.386294
8 0.90 9.000000 2.197225
9 0.99 99.000000 4.595120
'''

import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression # 逻辑回归需要导入的库
from sklearn.model_selection import train_test_split # 用于划分训练集、测试集
from matplotlib import pyplot as plt
bikes = pd.read_csv("bikeshare.csv") # 读取数据集
print(bikes.shape) # 输出数据集的基本信息
x = bikes[['temp']] # 将temp列作为特征(注意返回pandas.DataFrame对象)
y = bikes['count'] >= bikes['count'].mean() # 返回的是pandas.Series对象,内含索引号与一个布尔类型,代表是否数量大于平均值
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y)
logreg = LogisticRegression() # 实例化一个模型对象
logreg.fit(x_train, y_train) # 拿训练集训练模型
print("分类的准确率为:", logreg.score(x_test, y_test)) # 利用测试集得到模型准确率
print(pd.DataFrame(np.transpose([y_test.values, logreg.predict(x_test)]), columns = {'真实值', '预测值'}).head()) # 将预测的测试集结果和实际的测试集结果组合拼接成一个二维数组,经过转置后再经过类型转换,生成pandas.DataFrame对象并返回前几行
'''
输出结果
分类的准确率为: 0.6697281410727406
预测值 真实值
0 False False
1 True False
2 False False
3 False True
4 False True
(原数组真实值在上,预测值在下;故而转置后预测值在前,真实值在后)
'''
以上代码用到的方法:
train_test_split(x, y, test_size = , random_state = )方法:用于随机划分训练集和测试集,通常用四个变量接收,分别代表:训练集特征、训练集目标、测试集特征、测试集目标
具体参数:
x 数据框 所有特征的集合
y 数组/序列 所有目标取值
test_size 浮点数/整数 训练集样本占比/训练集样本数量
random_state 随机数的种子
np.transpose( a )方法:调换数组的行列值的索引值(求转置)返回一个 np.ndarray 对象
具体参数:
a 数组 想要进行转置的数组
(5)训练集—测试集划分
模型使用的两个阶段:
阶段:模型建立fit(X, Y)→模型应用predict(X)
任务:确定模型参数(在已有数据上最优)→基于已有模型对新数据预测
数据:X已知,Y已知→X已知,期待模型输出Y
数据足够多时,把文件分成两个集合:训练集与测试集,基于训练集进行建模,再对模型在测试集数据上的表现评分,最后用于预测
(6)非数值型特征作为输入时的 one-hot 编码
非数值型特征中的数字没有真实的数量意义
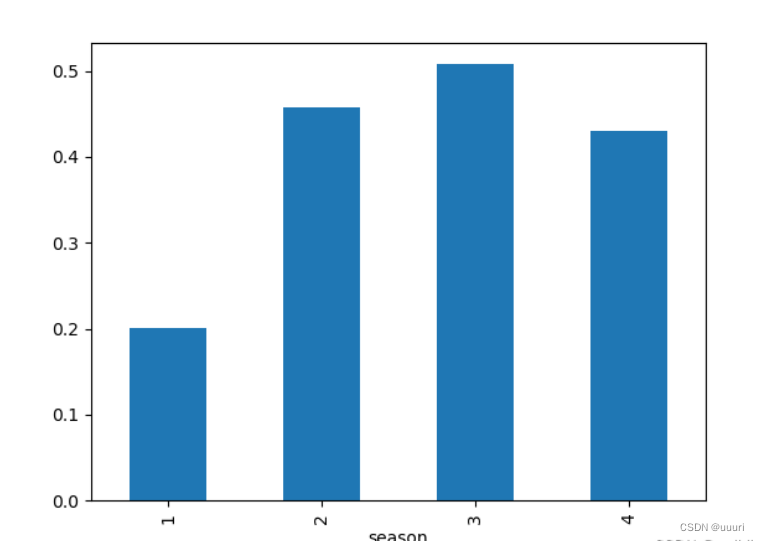
举例:"季节"特征的1~4代表四个季节,但数字本身不含有数量意义
one-hot 编码:避免数字引入非真实数量意义,将类别型数据映射到一个始终只有一位置为"1",其他位都是"0"的二进制编码,编码长度就是类别个数
bikes['above_average'] = bikes['count'] >= bikes['count'].mean() # 返回的是pandas.Series对象,内含索引号与一个布尔类型,代表是否数量大于平均值,这里用数据集的新列去接受
bikes.groupby('season').above_average.mean().plot(kind = 'bar') # 统计各季节有多少大于平均数量(作出柱状图简单比较哪个季节数量较多)
plt.show()
when_dummies = pd.get_dummies(bikes['season'], prefix = 'season_') # 对季节采用one-hot编码
print(when_dummies.head()) # 展示出one-hot编码后的季节特征前几行
x = pd.concat([bikes[['temp']], when_dummies], axis = 1) # 将自行车数据的气温特征和one-hot编码列连接作为训练集
x_train, x_test, y_train, y_test = train_test_split(x, y)
logreg = LogisticRegression() # 实例化一个模型的对象
logreg.fit(x_train, y_train)
print("用气温、季节同时作为预测自变量,预测的准确率为:", logreg.score(x_test, y_test))
x = bikes[['temp', 'season']] #将自行车数据的气温特征和季节特征列连接作为训练集
x_train, x_test, y_train, y_test = train_test_split(x, y)
logreg = LogisticRegression() #实例化一个模型对象
logreg.fit(x_train, y_train)
print("用气温、季节同时作为预测自变量,但是不做季节特征的one-hot编码时,预测的准确率为:", logreg.score(x_test, y_test))
'''
输出结果
season__1 season__2 season__3 season__4
0 1 0 0 0
1 1 0 0 0
2 1 0 0 0
3 1 0 0 0
4 1 0 0 0
用气温、季节同时作为预测自变量,预测的准确率为: 0.6914033798677444
用气温、季节同时作为预测自变量,但是不做季节特征的one-hot编码时,预测的准确率为: 0.6337252020573108
'''
6.3 朴素贝叶斯模型
1.贝叶斯定理


(2)高斯模型
当特征xx在每一类中都是服从高斯分布的连续值时构建的模型
sklearn库中的native_bayes模块有GaussianNB对象可以构建朴素贝叶斯的高斯模型
(3)多项式模型
当特征本身是离散值时构建的模型
sklearn库中的native_bayes模块有MultinomialNB对象可以构建朴素贝叶斯的多项式模型
(4)伯努利模型
当特征xx是m个布尔值序列时构建的模型
sklearn库中的native_bayes模块有BernoulliNB对象可以构建朴素贝叶斯的伯努利模型
import numpy as np
import pandas as pd
from sklean.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
from sklean.naive_bayes import BernoulliNB
import warnings
warnings.filterwarnings('ignore')
GaussianNB().fit()
GaussianNB().predict()
MultinomialNB().fit()
MultinomialNB().predict()
BernoulliNB().fit()
BernoulliNB().predict()
总结
未完待续…














 378
378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









