






 本文详细介绍了Java中的正则表达式匹配模式,包括贪婪型、勉强型(非贪婪型)和占有型,并给出了匹配示例。此外,还探讨了环视的概念、基础表达式及各种环视类型的示例。通过实例解析,帮助理解正则表达式的高级用法,如反向引用和固化分组。
本文详细介绍了Java中的正则表达式匹配模式,包括贪婪型、勉强型(非贪婪型)和占有型,并给出了匹配示例。此外,还探讨了环视的概念、基础表达式及各种环视类型的示例。通过实例解析,帮助理解正则表达式的高级用法,如反向引用和固化分组。
匹配模式:贪婪、勉强、占有
Greediness(贪婪型):最大匹配
X?、X*、X+、X{n,} 是最大匹配,即默认是贪婪匹配。
例如用 <.+> 去匹配 a<tr>aava</tr>abb ,也许你所期待的结果是想匹配 <tr> ,但是实际结果却会匹配到 <tr>aava</tr> 。
在贪婪模式下,会尽量大范围的匹配,直到匹配了整个内容,这时发现匹配不能成功时,开始回退缩小匹配范围(回溯),直到匹配成功。
Reluctant(Laziness)(勉强型,又叫非贪婪型,忽略优先量词):最小匹配
X??、X*?、X+?、X{n,}? 是最小匹配,其实X{n,m}?和X{n}?有些多余。在 Greediness 模式之后添加 ? 就成最小匹配。
在 Reluctant 的模式下,只要匹配成功,就不再继续尝试匹配更大范围的内容。
例如:
字符串:a<tr>aava</tr>abb
正则表达式:<.+?>
匹配结果:<tr> </tr>
可以看到,与 Greediness 不同,Reluctant 模式下匹配了两次内容。
Possessive(占有型,占有优先量词):完全匹配
X?+、X*+、X++、X{n,}+ 是完全匹配,在 Greediness 模式之后添加 + 就成完全匹配。
Possessive 模式与 Greediness 有一定的相似性,那就是都尽量匹配最大范围的内容,直到内容结束,但与 Greediness 不同的是,完全匹配不再回退尝试匹配更小的范围(即不会回溯)。
例如:
字符串:a<tr>aava</tr>abb
正则表达式:<.++>
匹配结果:无匹配内容
字符串:<12323432434>
正则表达式:<\d++>
匹配结果:<12323432434>
环视
概念
环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终的匹配结果,是零宽度的。环视匹配的最终结果就是一个位置。
环视的作用相当于对所在位置加了一个附加条件,只有满足这个条件,环视子表达式才能匹配成功。
环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视。顺序环视相当于在当前位置右侧附加一个条件,而逆序环视相当于在当前位置左侧附加一个条件。
基础表达式
- (?=Expression) 顺序肯定环视,表示所在位置右侧能够匹配Expression
- (?!Expression) 顺序否定环视,表示所在位置右侧不能匹配Expression
- (?<=Expression) 逆序肯定环视,表示所在位置左侧能够匹配Expression
- (?<!Expression) 逆序否定环视,表示所在位置左侧不能匹配Expression
注意:
JavaScript中只支持顺序环视,不支持逆序环视;
Java中虽然顺序环视和逆序环视都支持,但是逆序环视只支持长度确定的表达式,逆序环视中量词只支持?,不支持其它长度不定的量词。长度确定时,引擎可以向左查找固定长度的位置作为起点开始尝试匹配,而如果长度不确定时,就要从当前位置向左逐个位置开始尝试匹配,不成功则回溯,再向左侧位置进行尝试匹配,然后重复以上过程,直到匹配成功,或是尝试到位置0处以后,报告匹配失败,处理的复杂度是显而易见的。
示例
顺序肯定环视
匹配后缀结尾是“.txt”的不含后缀的文件名
| 表达式 | .+(?=\.txt) |
| 测试文本 | txtfile.txt exefile.exe inifile.ini |
| 匹配结果 | txtfile |
匹配步骤
先来分析下正则表达式:.+(?=.txt)
.+ 是匹配至少一个字符,在贪婪模式下会尽可能多的匹配;(?=.txt) 指所在位置的右边匹配.txt,则匹配。
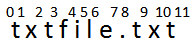
- 因为贪婪模式,.+ 会匹配 txtfile.txt,此时所在位置为 11,右边为空不匹配 .txt,回溯,吐出 t;
- 此时所在位置 10,右边为 t 不匹配 .txt,回溯,吐出 x;
- 此时所在位置 9,右边为 xt 不匹配 .txt,回溯,吐出 t;
- 此时所在位置 8,右边为 txt 不匹配 .txt,回溯,吐出 .;
- 此时所在位置 7,右边为 .txt 匹配 .txt,匹配结束,返回匹配 txtfile。
可以看到,匹配成功是因为有回溯,所以可以想到用占有型正则表达式 .++(?=.txt) 是匹配不到的,当然用勉强型正则表达式 .+?(?=.txt) 也可以匹配。
顺序否定环视
匹配后缀结尾不是“.txt”且文件名为txtfile的不含后缀的文件名
| 表达式 | txtfile(?!\.txt) |
| 测试文本 | txtfile.exe txtfile.txt |
| 匹配结果 | txtfile |
逆序肯定环视
获取指定参数的值
| 表达式 | (?<=name=).+ |
| 测试文本 | name=zxiaofan age=20 level=6 |
| 匹配结果 | zxiaofan |
匹配步骤
先来分析下正则表达式:(?<=name=).+,
.+ 是匹配至少一个字符,在贪婪模式下会尽可能多的匹配;(?<=name=) 指所在位置的左边匹配 name=,则返回匹配(结束匹配,不会继续找出满足表达式的所有匹配)。
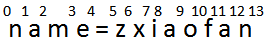
- 开始时所在位置 0,左边为空,不匹配,正则引擎向前传动;
- 此时所在位置 1,左边边为 n 不匹配 name=,正则引擎向前传动;
… - 此时所在位置 5,左边为 name= 匹配 name=,
而 .+ 贪婪模式尽可能取多,即 zxiaofan,记录匹配结果;正则引擎向前传动; - 此时所在位置 6,左边为 ame=z 不匹配 name=,正则引擎向前传动;
… - 此时所在位置 13,左边为 aofan 匹配 name=,匹配结束,返回匹配 zxiaofan。
逆序否定环视
| 表达式 | (?<!name=).+ |
| 测试文本 | name=zxiaofan |
| 匹配结果 | name=zxiaofan |
反向引用(Backreferences)
概念
捕获组
按照()子表达式划分成若干组;每出现一对()就是一个捕获组;引擎会对捕获组进行编号,编号规则是左括号(从左到右出现的顺序,从1开始编号。(\0指向整个表达式)
捕获组命名
(?exp) 匹配exp,并捕获文本到名称为name的组里,也可以写成(?'name’exp);
(?:exp) 匹配exp,不捕获匹配的文本到自动命名的组,也不给此分组分配组号。
反向引用
捕获组捕获到的内容,不仅可以在正则表达式外部通过程序进行引用,也可以在正则表达式内部进行引用。
对于普通捕获组和命名捕获组的引用,语法如下:
普通捕获组反向引用:\k,通常简写为\number;
命名捕获组反向引用:\k或者\k’name’;
普通捕获组反向引用中number是十进制的数字,即捕获组的编号;命名捕获组反向引用中的name为命名捕获组的组名。
\1表示第一组;\2表示第二组。
反向引用匹配原理
捕获组(Expression)在匹配成功时,会将子表达式匹配到的内容,保存到内存中一个以数字编号的组里,可以简单的认为是对一个局部变量进行了赋值,这时就可以通过反向引用方式,引用这个局部变量的值。一个捕获组(Expression)在匹配成功之前,它的内容可以是不确定的,一旦匹配成功,它的内容就确定了,反向引用的内容也就是确定的了。
反向引用必然要与捕获组一同使用的,如果没有捕获组,而使用了反向引用的语法,不同语言的处理方式不一致,有的语言会抛异常,有的语言会当作普通的转义处理。
示例
源字符串:abcdebbcde
正则表达式:([ab])\1
对于正则表达式“([ab])\1”,捕获组中的子表达式“[ab]”虽然可以匹配“a”或者“b”,但是捕获组一旦匹配成功,反向引用的内容也就确定了。如果捕获组匹配到“a”,那么反向引用也就只能匹配“a”,同理,如果捕获组匹配到的是“b”,那么反向引用也就只能匹配“b”。由于后面反向引用“\1”的限制,要求必须是两个相同的字符,在这里也就是“aa”或者“bb”才能匹配成功。
考察一下这个正则表达式的匹配过程,在位置0处,由“([ab])”匹配“a”成功,将捕获的内容保存在编号为1的组中,然后把控制权交给“\1”,由于此时捕获组已记录了捕获内容为“a”,“\1”也就确定只有匹配到“a”才能匹配成功,这里显然不满足,“\1”匹配失败,由于没有可供回溯的状态,整个表达式在位置0处匹配失败。
正则引擎向前传动,在位置5之前,“([ab])”一直匹配失败。传动到位置5处时,,“([ab])”匹配到“b”,匹配成功,将捕获的内容保存在编号为1的组中,然后把控制权交给“\1”,由于此时捕获组已记录了捕获内容为“b”,“\1”也就确定只有匹配到“b”才能匹配成功,满足条件,“\1”匹配成功,整个表达式匹配成功,匹配结果为“bb”,匹配开始位置为5,结束位置为7。
固化分组
考虑这样一个场景:
源字符串:[a-zA-Z]+:
正则表达式:Subject
匹配过程:[a-zA-Z]+匹配优先,一直吃到t,发现冒号不能匹配,于是使用备用状态,吐出一个字符,还是不能匹配,再吐出一个字符…一直继续下去。
这里存在问题,引擎试图吐出一个字符匹配冒号,我们知道这是徒劳的尝试。因为[a-zA-Z]+没有吃下去冒号,当然不可能吐出冒号。
如果正则表达式引擎足够聪明,意识到这一点,就不需要尝试吐出字符,直接报告匹配失败,也就是说,之前的备用状态应该丢弃。
但是,一般情况下,引擎没有这么聪明,需要人为的协助,提示引擎不需要吐出字符,也就是丢弃之前的备用状态。
固化分组:丢弃备用状态
用(?>…)实现固化分组(成功匹配后,回溯时不会考虑这个匹配的字符)
正则表达式改为 (?>[a-zA-Z]+): (?>[a-zA-Z]+)作为一个整体,吃下去文本,即使后面匹配失败,也不吐出来。也就是说,使用固化分组可以提前报告匹配失败,不需要进行徒劳的尝试,提高效率。
占有优先和环视替代固化分组
对于不支持固化分组的程序,可以使用占有优先和环视。
占有优先,如 ([a-zA-Z]++):
环视匹配一个位置,有一个重要的特点,就是匹配尝试结束后,不会留下任何备用状态,因此,使用环视解决上面的问题,如下:
(?=([a-zA-Z]+))\1:
(?=([a-zA-Z]+))匹配一个位置,右边是([a-zA-Z]+),\1反向引用([a-zA-Z]+),后面跟着一个冒号。
正则表达式匹配原理
正则引擎大体上可分为两类:DFA和NFA,而NFA基本上又可以分为传统型NFA和POSIX NFA
NFA(Non-deterministic finite automaton):非确定型有穷自动机。
大多数语言和工具使用的是传统型的NFA引擎,它有一些DFA不支持的特性:
捕获组、反向引用和$number引用方式;
环视(Lookaround,(?<=…)、(?<!…)、(?=…)、(?!…)),或者有的有文章叫做预搜索;
忽略优化量词(??、*?、+?、{m,n}?、{m,}?),或者有的文章叫做非贪婪模式;
占有优先量词(?+、*+、++、{m,n}+、{m,}+,目前仅Java和PCRE支持),固化分组(?>…)。
DFA(Deterministic finite automaton):确定型有穷自动机。DFA引擎因为不需要回溯,所以匹配快速,但不支持捕获组,所以也就不支持反向引用和$number这种引用方式。
目前使用DFA引擎的语言和工具主要有awk、egrep 和 lex。
POSIX NFA:主要指符合POSIX标准的NFA引擎,它的特点主要是提供longest-leftmost匹配,也就是在找到最左侧最长匹配之前,它将继续回溯。同DFA一样,非贪婪模式或者说忽略优先量词对于POSIX NFA同样是没有意义的。
DFA和NFA的差异
效率
构造DFA的代价远大于NFA,假设NFA的状态数为K,那么等价DFA的状态数目理论上可达2的k次方,不过实际上几乎不会出现这么极端的情况,可以肯定的是构造DFA会消耗更多的时间和内存。
但是DFA一旦构造好了之后,执行效率就非常理想了,如果一个串的长度是n,那么匹配算法的执行复杂度是O(n);而NFA在匹配过程中,存在大量的分支和回朔,假设NFA的状态数为s,因为每输入一个字符可能达到的状态数最多为s,那么匹配算法的复杂度及时输入串的长度乘以状态数O(ns)。
其他
NFA和DFA这两种匹配算法,除了效率上的差别外,从更高的视点看,形成了两种风格的引擎,进而对正则表达式的匹配的其他方面能力造成差异。NFA被称之为"表达式主导"引擎,而DFA被称之为“文本主导”引擎。
NFA:表达式主导
从表达式的第一个部分开始,每次检查一部分,同时检查当前文本是否匹配表达式的当前部分,如果是,则继续表达式的下一部分,如此继续,直到表达式的所有部分都能匹配,即整个表达式匹配成功。
来看表达式 to(nite|knight|night) 匹配文本 …tonight… 的过程: 表达式的第一个部分是t,它会不断重复扫描,直到在字符串中找到t,之后就检查随后的o,如果能匹配就继续检查下面的元素。这个例子中,下面的元素是(nite|knight|night),意思是nite或者knight或者night,引擎会依次尝试这三种可能。
整个过程,控制权在表达式的元素之间转换,因此被称之为“表达式主导”。“表达式主导”的特点是每个子表达式都是独立的,不存在内在联系。子表达式与整个正则表达式的控制结构(多选、量词)的层级关系控制了整个匹配过程。
DFA:文本主导
DFA在读入一个文本的时候,会记录当前有效的所有匹配的表达式位置(这些位置集合对应于DFA的一个状态)。
以上面的匹配过程为例:
当引擎读入文本t时,记录匹配的位置是to(nite|knight|night);
接着读入o,匹配位置to(nite|knight|night);
读入n,匹配位置to(nite|knight|night),两个位置,knight被淘汰出局;
…
这种方式被称之“文本主导”是因为被扫描的字符串,控制了引擎的执行过程。
差异之一:NFA表达式影响引擎
NFA表达式主导的特性,使得通过修改正则表达式来影响引擎,因此下面三个表达式尽管能够匹配同样的文本,但是引擎的执行过程各不相同:
- to(nite|knight|night)
- tonite|toknight|tonight
- to(k?night|nite)
但是对于DFA来说,没有任何区别。
差异之二:DFA能保证最长匹配
对于包含或选项的表达式,NFA在成功匹配一个选项之后可能报告匹配成功,此时并不知道后面的选项是否也会成功,是否包含一个更长的匹配。
假设使用 one(self)?(selfsufficient)? 来匹配 oneselfsufficient,NFA首先匹配one,然后匹配 self,此时发现 selfsufficient 无法匹配剩余子串,但是这个子表达式不是必须的,因此可以立即返回成功,此时匹配的串为 oneself。
实际上NFA引擎的匹配结果与具体实现有关,而DFA必然会成功匹配oneselfsufficient。
差异之三:NFA支持更多功能
NFA能够支持“捕获group”,“环视”,“占有优先量词”,“固话分组”等高级功能,这些功能都基于“子表达式独立进行匹配”这一特点。 而DFA无法记录匹配历史与子表达式之间的关系,因而也无法实现这些功能。
可见NFA引擎具备更大的实用价值,因而,在编程语言里面使用的正则表达式库都是基于NFA的。java的Pattern就是基于NFA的,Pattern.compile()方法显然就是在构造NFA状态图。
参考:
Java 正则表达式匹配模式[贪婪型、勉强型、占有型]
正则表达式之环视
Java正则环视和反向引用
正则基础之——反向引用
固化分组
正则表达式:NFA引擎匹配原理
正则表达式之基本原理















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









