






MYSQL5.7.2
数据库备份恢复
备份
mysqldump -u 用户名 -p 数据库名 > 磁盘SQL文件路径
dos窗口使用
恢复
mysql -u 用户名 -p 导入库名 < sql文件路径
多表查询
笛卡尔积
select * from a,b;
即做笛卡尔积返回
还需要加入过滤条件
连接
内连接
select * from A inner join B on A.A_ID=B.B_ID
左外连接
select * from A left outer join B on A.A_ID=B.B_ID
区别:左外连接如果没有关联上左表也会显示,以左为主
全外连接
select * from A full outer join B on
左外与右外结果合并,去除重复记录
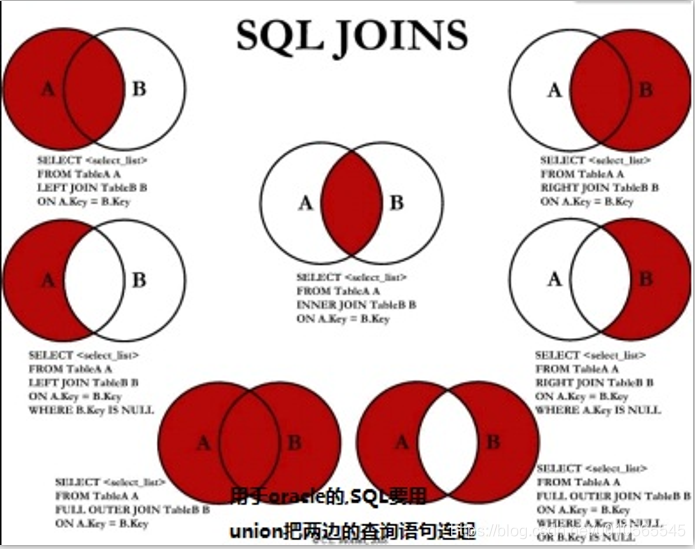
关联查询
exist–有结果返回则为true,则显示主查询结果
union和union all
- union–用于将不同表中相同列中查询的数据显示出来(不包括重复数据)
- union all–同上,但包括重复数据
case when
select *,
case
when salary <5000 then ""
when salary >=5000 then ""
end as level,
case sex
when "famale" then 1
when "male" then 0
end as flag
from employee;
元数据及函数
select VERSION() //服务器版本
show state //服务器状态
show variables //服务器配置变量
常见函数
char_length(s) //字段长度
concat("","",...) //拼接字段 concat_WS()加个分隔符
format(,) //格式化数字,后面数为保留几位
LCASE(s) //转小写
TRIM(s) //去掉字符串开始结尾的空格
ABS(s) //绝对值
CEIL(x) //向上取整
RAND() //01随机数
日期函数
adddate(d,n) //计算真实日期D加上N天的日期
curdate() //当前日期
current_timestamp //返回当前日期和时间 --now()
datediff(d,f) //两个日期差多少天
date_add("yyyy-mm-dd hh:mm:ss",interval 1 day) //加上一天
date_format(d,f) //按f格式显示日期d
高级函数
cast("2022-01-09" as DATE) //转换数据格式
coalesce(...) //返回第一个非空数据
MYSQL索引
create index index_name on mytable(username(length));
//对某字段一段长度
create index id on (B_id);
//普通索引
//改表结构添加索引
alter table tablename add indexname(columnName)
//建表直接指定
create table mytable(
id int not null,
username varchar(16) not null,
index [indexName](username(length))
);
//删除索引
drop index [indexname] on mytable;
唯一索引
索引列的值必须唯一,但允许控制
alter table tablename add primary key (column_list);
索引值必须唯一
alter table tableName add unique index_name (column_list);
创建索引的值必须是唯一的(除了null)
alter table tableName add index index_name(column_list);
普通索引,索引值可出现多次
alter table tableName add fulltext index_name(dolumn_list);
用于全文索引
show index from table_name;
索引实现原理
MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
https://www.cnblogs.com/pebblecome/p/14815340.html
mysql事务
目前mysql只有Innodb数据库引擎支持事务
ACID
原子性–
一致性–事务必须保持系统的一致性状态,不论并发。
隔离性–允许并发事务,防止多个事务执行交叉执行导致数据不一致
持久性–事务结束对数据的修改就是永久的
Mysql执行引擎
innodb/Myisam比较多
- innodb
- 优点:事务型,有行级锁定及外键约束,提供ACID支持,实现SQL标准的四种隔离级别
- 缺点:不支持全文索引,没保存表的行数
- 适用场景:常更新的表,处理多重并发的更新请求需要事务外键
- Myisam
- 优点:支持全文索引,保存表的行数
- 缺点:不支持事务,更新操作需要锁定整个表,不支持行级锁和外键
- 适用场景:经常读取的表,更新操作少
相当于事务型和分析型差别
可分别用来实现读写分离
SQL语句优化
- 能用=就不用比较符<>—使用=增加索引使用几率
- 知道只有一条查询结果,使用limit 1,可避免全表扫描,有结果就结束
- 选择合适的数据类型 ,能smallint就不int,节省空间
- 将大的delete,update,insert查询变为多个小查询
- 允许数据重复时使用union all
- where子句的列尽量用上索引
- explain查看执行计划,检查索引使用情况及扫描的行
- 分组topN
Linux
-
ls/ll
ls -l 和ll一样
-
当前目录
pwd
-
ctrl C和ctrl Z
前者取消后者结束
-
mkdir dir1[dir2 dir3 dir4]
-
删除
rm -rf dir
-
递归创建
mkdir -p dir1/dir2/dir3 scp -r分发
-
yum 安装
install -y telnet
-
自动补全
tab
-
查看进程
ps -ef | grep impala
-
查看文件
cat /more /tail -f 大文件不用cat
-
分发
scp -r /export/servers/hadoop hadoop02:/export/servers
scp -r /export/servers/hadoop hadoop02:$PWD(发到同级目录)
-
date 日期 可以+“%Y-%m-%d %H-%M-%S”
用户管理
-
添加用户
useradd username
-
更改密码
password username
-
删除用户
userdel username(不删除用户数据)
userdel -r username
压缩包管理
- gz压缩包
- tar czf file.tar.gz制作压缩包
- tar zxvf file.tar.gz -C /dir
- zip压缩包
- zip file.zip file
- unzip file.zip
查看属性
-
磁盘大小
df -h
-
内存大小
free -h
-
文件大小
du -h
-
任务管理器
top
-
清理内存
echo 1 > /proc/sys/vm/drop_caches
尝试
- linux查看进程
- 获取当前进程id
- centos6 7 的区别
hadoop3.1.3
hadoop1.0和2.0差别
- hadoop1.0 :mapreduce+HDFS
- hadoop2.0: mapreduce+HDFS+YARN(资源调度任务管理,同时支持spark、flink)
介绍hadoop(面试题)
- 大的来说,hadoop指的是hadoop生态圈(kafka、hbase、spark、flume、sqoop)
- 小的来说,hadoop就是apache hadoop开源框架,包括
- HDFS(分布式文件系统):负责海量数据存储
- YARN(作业调度和集群资源管理框架):负责资源任务调度
- mapreduce(分布式计算框架):负责海量数据计算
特性优点
- 高扩展性:hadoop基于集群存储及计算,集群可方便扩展数以千计
- 成本低:可通过廉价机器完成集群搭建
- 高效性:通过并发数据,可在节点间动态并行移动数据,在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高可靠:自动维护数据的备份,任务失败可以自动重新部署计算任务。
缺点
- 不适合低延时访问(多节点通过网络传输有延迟)
- 无法高效存储大量小文件
- 存储大量小文件导致namenode大量内存储存文件目录和块信息
- 小文件寻址时间超过读取时间
- 不支持并发写入,文件随机修改
- 一个文件只能单线程写
- 只支持数据追加(append),不支持文件随机修改
hadoop块大小为什么是128m?
在物理是分块存储(block)
Hadoop2.x以上都是128m,在集群运行的是128m,在本地运行的时候是64m
文件的寻址时间为传输时间的1%的时候,为最佳状态,寻址时间一般为10ms,
所以最佳的传输时间为10ms/1%为1000ms,也就是1s
目前的硬盘传输速率是100m/s,所以文件的大小在100m左右的时候,传输速率较高。
为什么不能随机写?
hdfs 是块存储,也就是每次读取一个块,存储也是一样的,所以你可以理解为可以随机读写文件块,但是对文件不支持随机读写,因为一个文件块中可能有很多文件。
-
启动hadoop
-
查看hadoop启动进程
-
查看50070、8088等端口
hadoop启动进程
- namenode=>HDFS守护进程,负责维护整个系统,存储整个文件系统的元数据信息image+editlog
- datanode=>具体的工作节点,需要某个数据,namenode给datanode地址,client和对应服务器通信,datanode进行数据检索,进行具体的读写操作。
- secondarynamenode=>一个守护进程,相当于namenode的元数据备份机制,定期更新,和namenode通信,将image和edits合并,可作为namenode备份使用
- resourcemanager=>yarn的守护进程,负责资源调度分配,client的请求负责,监控nodemanager
- nodemanager=>单节点的资源管理,执行resourcemanager的具体任务命令
- DFZKFailoverController=>高可用时负责监控NN状态,及时状态写入ZK,通过独立线程周期性调用NN上特定接口获取状态,FC可选择谁作为Active NN权力,先到先得,轮换。
- JournalNode 高可用下存放namenode的editlog文件
记忆==
namenode:HDFS主节点,存储元数据
datanode:工作节点,存储数据,读写数据
secondarynamenode:守护进程,备份NN元数据
resourceManager:yarn主节点,资源调度分配,监控NM
nodeManager:资源管理,听RM的
DFZKFC:高可用监控NN状态,写入ZK
JournalNode:高可用存NN的editlog
主要配置文件
-
hadoop-env.sh-------配置环境变量
-
core-site.xml----------设置hadoop文件系统地址(fs.defaultFS->dfs://hadoop01:9000)
-
hdfs-site.xml---------副本数量,secondaryNN Ip和端口
-
mapred-site.xml-----MR运行时框架,默认local,可yarn
-
yarn-site.xml---------yarn主节点地址
hadoop重要命令
-
初始化
hadoop namenode -format
-
启动dfs
start-dfs.sh
-
启动历史服务器
mr -jobhistory-daemon.sh start historyserver
-
一键启动
start-all.sh
-
NameNode 50070
-
ResourceManager 8080
-
hdfs -put
HDFS垃圾桶机制
修改core-site.xml
添加fs.trash.interval 1440 1440=24h=1day
SecondaryNameNode工作机制
SNN不是NN的热备份,职责为合并edits log文件并分担NN的压力,必要时协助恢复NN
- 工作机制
- 满足条件(1.一小时 2.达到100万条事件)开启checkpoint
- 将NN edits log和fsimage复制到SNN,NN此时生成新的edits log
- 在SNN将fsimage和edits log合并为fsimage.ckpt
- 将fsimage.ckpt复制到NN作为fsimage文件
- 若NN元数据丢失,可以从SNN恢复部分元数据,但是NN正在写的edits log没有拷贝到SNN恢复不了
SNN不能恢复全部怎么保证存储安全
NameNode HA
- HA中元数据通过"共享存储"共享数据,每次写文件写入共享存储才算成功
- 监控NN采用zookeeper,两NN分别有监控进程程序判断当前active NN是否down机,如果有则强制给原来active NN关闭,将备用NN设为active
共享存储QJM 保存editlog不保存fsimage
脑裂问题
当前active NN 的ZKfailoverController进程发生假死,ZK会认为当前active NN挂掉,NN2会替代进入active状态,此时有两个active NN运行
fencing隔离,把旧的active NN隔离
HDFS扩容缩容
HDFS安全模式
此状态下,文件系统只接受读数据请求,不接受删除,修改等请求。
NN启动时,HDFS进入安全模式,集群检查数据块完整性。DN启动会向NN汇报可用block信息,整个系统达到安全标准时,HDFS自动离开安全模式。
手动进入安全模式
hdfs dfsadmin -safemode enter
手动离开
hdfs dfsadmin -safemode leave
机架感知
hadoop本身没有此能力,需要配置一个脚本进行映射,或者通过实现DNSToSwitchMapping接口的resolve()方法来完成网络位置映射。
MapReduce
MR实现wordCount
map类
public class wordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
//map生命周期:框架每传一行数据就被调用一次
//key:这一行的起始点在文件中的偏移量
//value:这一行的内容
@override
rotected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException{
String line = value.toString();
String[] words = line.split(",");
for(String word:words){
context.write(new Text(word),new IntWritable(1));
}
}
}
reduce类
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
//map到reduce之间有一个shuffle过程,将map输出数据打乱
//来一组执行一次
@override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException{
int count=0;
for(IntWritable value:values){
count+=value.get();
}
context.write(key,new Intwritable(count));
}
}
需要注意问题:文件很小先进行小文件合并,自定义分区需要设置reduce个数,如果输出路径已经存在会报错,打包放到linux运行没有设置jar的话会报错.setJar .setJarByClass
scala实现
array.flatMap(x=>x.split(",")).groupBy(_._1).map(x._1,x._2.length)
spark离线实现
val sparkconf=new sparkConf().setAppName("wordCount").setMaster(args(0))
val SC = new sparkContext(sparkconf)
val lines = ssc.socketTextStream("localhost",9999)
Combiner
每一个map都可能产生大量本地输出,Conbiner是对map端的输出先做一次合并,减少map和reduce节点间的数据传输量,提高网络io性能
partitioner
执行MR计算时,有时需要对最终输出分到不同文件中,就需要partitioner
map的shuffle阶段做分区
实现
@override
public int getPartition(IntWritable key,IntWritable value,int numPartitions){
int intValue = key.get();
if(intValue % 5==0){
return 0;
}else{
return 1;
}
}
主类函数加
job.setPartitionerClass(classname.class);
job.setNumReduceTasks(2);设置为2
MR执行流程
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wYngImRq-1664110283006)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220223123455697.png)]
-
inputformat数据读取
-
Split将获取数据逻辑切分
获得数据对数据逻辑切分,切分128M,和HDFS存储数据块128M没关系,一个是存储层面一个是计算层面,一个集成程序正好一个数据块。
-
recordReader 以行切分,输出<K,V>K:行首字母偏移量,V:一行数据
-
Map 接受KV根据重写的map函数输出KV的list
-
shuffle=>
- 数据进入分区方法,标记好分区后发送到环形缓冲区,默认大小为100M,环形缓冲区达到80%时,进行溢写;
- 溢写前对数据排序,按照Key的字典序快排
- 溢写产生大量溢写文件,进行归并排序
- 对溢写文件汇总操作也可以combiner
- 文件按分区存储到磁盘等reduce拉取
- reduce拉取对应分区数据,先储存到内存,内存不够再放磁盘。拉取完归并排序所有数据
-
reduce按照重写reduce方法做汇总计算
-
outputformat写入HDFS
基于MR优化Hadoop
-
采用CombineFileInputFormat来作为输入,解决输入端大量小文件场景
-
合理设置Map和Reduce数:两个都不能设置太少,也不能设置太多。太少,会导致Task等待,延长处理时间;太多,会导致 Map、Reduce任务间竞争资源,造成处理超时等错误。
-
采用数据压缩的方式,减少网络IO的的时间
-
Map和reduce task的可用内存扩大(条件允许的话)以及每个task的cpu核加
压缩,可以参考这张图
:如果面试过程问起,我们一般回答压缩方式为Snappy,特点速度快,缺点无法切分(可以回答在链式MR中,Reduce端输出使用bzip2压缩,以便后续的map任务对数据进行split)
https://blog.csdn.net/a934079371/article/details/109233998
MR程序在yarn上执行流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GnuBmkmC-1664110283007)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220223141103856.png)]](https://img-blog.csdnimg.cn/072fe6b4da3641b881b0f1ef00293418.png)
-
client提交一个任务到RM
-
RM到NodeManager申请一个容器container,然后启动一个appMaster
-
ApplicationMaster陆续为app包含的每个task向ResourceManager申请一份container
-
得到container后要求该container所属的NM启动container,执行相应的task
-
执行完task后此container会被NodeManager回收
client=>RM=>(container)appMaster=>ResourceManager=>container(task)=>回收
MapReduce常见问题
client对集群HDFS没权限
- hdfs-site.xml里面permissions改为false
- 输出路径已存在
- 提交集群失败,没有setJar
- 日志打不出来,需要在项目新建log4j.properties的文件
YARN
介绍(面试题+三大组件介绍)
通用资源管理系统和调度平台,为上层应用提供统一的资源管理和调度。有点像一个分布式的操作系统平台,mapreduce等运算程序相当于运行于操作系统的应用程序,yarn为它们提供运算所需资源。
基本架构
ResourceManager 负责资源监控、分配和管理
NodeManager 负责每个节点的维护
ApplicationMaster 负责每个具体应用的调度和协调
三大组件
ResourceManager
- ResouceManager负责整个集群的资源管理和分配,全局资源管理系统
- YarnScheduler根据application的请求为其分配资源,不负责其它
NodeManager
- 心跳方式向ResourceManager汇报资源使用情况
- 每个节点上的资源和任务管理器
- 接受处理applicationMaster的container启动停止请求
ApplicationMaster
- 每个应用程序包含一个AM,可以在RM所在节点以外机器
- 与RM调度器获取资源
- 将得到的任务二次分配
- 通信NM以停止/启动任务
- 监控任务允许状态,失败重新申请资源
RM只监控AM,在AM失败启动它,不负责AM容错,AM自己完成
sqoop1.4.6
介绍
sqoop时apache旗下hadoop和关系型数据库服务器之间传输数据的工具
导入数据:MYSQL,Oracle导入数据到Hadoop的HDFS、Hive、Hbase等数据存储系统
导出数据:从hadoop的文件系统中导出数据到关系型数据库mysql等
将导入导出命令翻译成mapreduce程序来实现
常见问题
中文乱码
mysql到hdfs
bin/sqoop import \
--connect jdbc:mysql://hadoop01:3306/A \
--username root \
--password 123456 \
--target-dir /A2 \
--table B --m 1
mysql导入hive(可能乱码)
bin/sqoop import \
--connect "jdbc:mysql://hadoop01:3306/A?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--table B \
--hive-import \
--m 1 \
--hive-database default;
hdfs导入mysql
bin/sqoop export \
--connect "jdbc:mysql://hadoop01:3306/A?useUnicode=true&characterEncoding=utf-8" \
--username root \
--password 123456 \
--table B \
--export-dir /user/hive/warehouse/b
解决:加characterEncoding=utf-8
hive中文注释问题
hive注释会乱码
https://www.cnblogs.com/qingyunzong/p/8724155.html
是因为mysql中元数据乱码
配置文件把相应注释的地方的字符集由 latin1 改成 utf-8
datax常见问题
- 数据溢出oom
目标数据过大,调大datax的jvm参数防止oom
python datax.py --jvm="-Xms5G -Xmx5G"
-
字段长度过长
数据源column字段长度超过100000字符
"csvReaderConfig":{ "safetySwitch":false, }
HBASE2.2.2
介绍
bigtable的开源java版本,是建立在hdfs之上,提供高可靠性、高性能、列存储、可伸缩、实时读写nosql的数据库系统
主要应用:海量数据的并发读写,分析需求较小。原生不支持二级索引和sql,需在其上架构Phoenix、spark等。
特点
- 大:一个表可以有上十亿行,上百万列
- 面向列:面向列族的存储和权限控制,列族独立检索
- 稀疏:对于为空的列,不占用存储空间,可以很稀疏
- 数据类型单一:HBase中的数据都是字符串,没有类型。
HBase和Hdfs的区别
- HDFS
- 为分布式存储提供文件系统
- 针对存储大尺寸文件优化,不需要对HDFS上文件进行随机读写
- 直接使用文件
- 数据模型不灵活
- 使用文件系统和处理框架
- 优化一次写入,多次读取
- HBase
- 提供表状的面向列的数据存储
- 针对表状数据的随机读写进行优化
- 使用key-value操作数据
- 灵活的数据模型
- 支持mapreduce,依赖HDFS
- 优化了多次读多次写
mapreduce操作hbase,多少个region就有几个map
Redis,传统数据库,HBase,Hive区别
Redis
分布式缓存,基于内存,强调缓存,支持数据持久化,支持事务,nosql类型的key/value数据库,同时支持List,set等类型
Hbase
hbase是建立在hdfs上的,提供高可靠性的列存储。介于Nosql和关系型数据库之间,仅通过主键和主键的range来检索数据,仅支持单行事务。主要用来存储结构化和半结构化数据。
关系型数据库
mysql、oracle等,支持事务型,属于写模式,即写入数据时进行检查。针对具体业务在数据库练级的日常操作,通常对少数记录进行查询、修改。支持完善的sql功能,可对少量数据进行统计分析。
hive
基于hadoop的数据仓库工具,可以将结构化数据文件映射为数据库表,可以将sql转化为mr任务执行。因为sql比mr学习成本低,适合数据仓库的统计分析。
区别
关系型数据库和HIve都支持sql引擎。redis和hbase都是nosql类型key value数据库,支持简单的行列操作,不支持sql引擎。
redis因为存储在内存数据量较小,hbase适合大数据的持久储存,redis适合做缓存。EDMBMS一般用来做支撑业务系统。hive时面向分析的分析型工具,作为海量数据的分析工具。
hive和hbase是基于hadoop的两种不同技术。hive是一种类sql引擎,且运行MR任务,Hbase是一种在hadoop之上的nosql的k、v数据库。两者可以搭配使用,hive用来做统计查询,hbase用来做快速实时查询。可将hive映射到hbase,做对外的访问接口。
Hbase架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sPzB62Iv-1664110283007)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220224164052815.png)]](https://img-blog.csdnimg.cn/ef00c3bf10534c39bba858924f907452.png)
- HMaster
- 监控RegionServer
- 处理regionServer故障转移
- 处理元数据变更
- 处理region的分配或移除
- 空闲时间进行数据负载均衡
- 通过ZK发布自己的位置给客户端
- RegionServer
- 负责存储Hbase实际数据
- 处理分配给它的region
- 刷新缓存到HDFS
- 维护Hlog
- 执行压缩
- 负责处理region分片
常用HBASE shell
启动
先启动hdfs和zk
start -hbase.sh
hd50070 yarn8088 hbase16010
进入HBase客户端命令操作界面
bin/hbase shell
查看表
list
创建user表(包含info、data两个列族)
create 'user','info','data'
create 'user',{NAME=>'info',VERSIONS=>'3'},{NAME=>'data'}
添加数据
user表插入一行信息,rowkey为0001,列族info添加name列标示符,值为zhangsan
put 'user','rk0001','info:name','zhangsan'
put 'user','rk0001','info:gender','female'
查询操作
通过rowkey
get 'user','rk0001'
某个列族信息
get 'user','rk0001','info'
指定列族指定字段
get 'user','rk0001','info:name','info:age'
所有数据
scan 'user'
列族查询
scan 'user',{COLUMNS=>'info'}
统计
count 'user'
显示所有表
list
表数据模型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kqW1bVrh-1664110283008)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220224170257539.png)]](https://img-blog.csdnimg.cn/ca75b9374d754664880c1315b0a0eb3f.png)
row key是用来检索记录的主键,访问行:
- 通过单个row key
- 通过row key range
- 全表扫描
列族
列族是表的schema的一部分而列不是
列名都以列族做前缀如Family1:name
列族越多,取一行数据要参与的io就越多,非必要不设太多列族
cell
通过row和columns确定的一格为cell ,每个cell保存一份数据的多个版本,通过时间戳区分
Hbase读写请求过程?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Dk3pFMVC-1664110283009)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220224171429975.png)]](https://img-blog.csdnimg.cn/a8c7bc81438b40799c7218edff408a5f.png)
写
- client找到zk获取meta表位置,进而获取表位置信息
- 到表对应的region节点,写入Hlog,然后写入memoryStore
- memoryStore达到128M后flush为storefile
- storefile再压缩成Hfile到Hdfs中
读
- client找到zookeeper,获取表位置
- 到对应的region的memoryStore看是否有则返回
- 没有就下一层到storeFile
- 再没有就去Hfile中找到返回
region预分区
不做的话全部默认在一个region,太大,读写很慢
根据rowkey划分
作用
- 提高数据读写效率
- 负载均衡,防止数据倾斜
- 方便集群容灾调度region
- 优化map数量
手动设定预分区
create 'staff','info','partition1',Split=>['1000','2000','3000','4000']
16进制算法生成预分区
create 'staff2','info','partition2',{NUMREGION=>15,SPLITALGO=>'HexStringSplit'}
rowkey设计
三原则
-
长度原则
每个cell单元格都会保存rowkey,尽量不超过16字节,太长资源浪费
-
散列原则
如果rowkey按照时间戳的方式递增,不要将时间放在二进制码的前面,建议将rowkey的高位字节采用散列字段处理,由程序随即生成。低位放时间字段,这样将提高数据均衡分布,各个regionServer负载均衡的几率
rowkey是按字典序存储,将经常一起读的数据存储到一块,将最近可能被访问的数据放到一块。
例:如果最近写入的最可能被访问,因为是字典序排序可以使用Long.MAX_VALUE-timestamp作为rowkey
-
唯一原则
保证唯一性
rowkey是按字典序存储,将经常一起读的数据存储到一块,将最近可能被访问的数据放到一块。
不保证散列原则会?
热点问题
大量的client直接访问集群的一个或极少数节点,使热点region所在的节点超出承受能力,性能下降或不可用,同一region Server的其它region也被影响。
解决方案
-
加盐
在rowkey前加随机数,使其和之前rowkey开头不同。之后rowkey根据前缀不同分散到各个region避免热点![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nr8W9RV5-1664110283009)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220225131741914.png)]](https://img-blog.csdnimg.cn/61cc8606c1a4467d8eee663c7030c7c7.png)
-
哈希
哈希使同一行一直用一个前缀加盐。也可以使负载分散到整个集群,但是读是可预测的。可用get准确获取某一行数据
-
反转
如手机号,反转一下,避免因为前几位太相同而都分到一个region。
-
时间戳反转
常见情景是快速获取最近版本数据,反转时间戳作为rowkey一部分非常有用,可Long.MAX_VALUE-timestamp追加到key末尾
Redis3.0.5
介绍
由c编写的nosql类型的开源key-value存储系统。redis数据都缓存在系统内存中,可周期性把更新数据写入磁盘或把修改操作写入追加的记录文件,实现数据持久化。
- java一般用来做热点数据的存储,避免了对业务数据库的大量访问。
- 大数据一般整合实时计算,定时过期等。
数据类型
-
string
赋值 set key value 取值 get key/getset key value 数据自增和自减 incr key/decr key 拼凑 append key value -
hash
适合存储对象 赋值hset key field value(hset student name sp) 取值 hget key field 取值 hgetall key 删除 hdel key field[field..] 删除 del key 判断是否存在 hexist key field 获取所有key hkeys key 获取所有value hvals key -
list
list基本使用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-B744XOl9-1664110283010)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220225144502511.png)]](https://img-blog.csdnimg.cn/1d959fb4c9aa490c9c31a200f82adabc.png)
持久化
rdb(保存快照)
redis会定期保存数据快照至一个rdb文件中,并启动时自动加载rdb文件恢复数据。快照保存时机可配置。
- 优点
- 对性能影响小,RDB快照时fork出子进程进行。
- 每次快照是完整的数据快照文件,可配合其它存储媒介
- 恢复要比RDB快
- 缺点
- 快照是定期的,crash时会丢失数据
- 如果数据集太大且cpu不强,如单核cpu,fork子进程可能耗时较多,影响对外服务
AOF(预写日志)
redis把每个写请求记录在日志文件里,redis重启会把日志的写操作全做一遍。AOF默认关闭的
开启
appendonly yes
三种sync配置,always/everysec/no,通过配置项appendfsync指定
- appendfsync no:不进行fsync同步,刷新文件时机交给os,速度最快
- appenddsync always:每写一条同步一次,安全性最高,速度最慢
- appendfsync everysec:交给后台线程每秒同步一次
优点
- 最安全,在启用always时,数据不会丢失,everysec也最多丢失一秒数据
- AOF文件断电等问题也不会损坏,某条日志写到一半也可以使用redis-check-aof工具修复
- AOF文件易读可修改,进行了错误清除操作也可以把AOF备份出来修改恢复数据。
缺点
- AOF文件通常较大
- 性能消耗高(写入磁盘)
- 数据恢复慢
缓存穿透
一定不存在数据,每次都不会命中要去数据库查。黑客通过这点不停请求数据库,失去了缓存意义。数据库炸。
**解决**
1.布隆过滤器(比如是id就先把所有id写进布隆过滤器,有的话才查)或压缩过滤提前拦截
2.数据库找不到的时候也把空对象设置到redis中。
redis雪崩
- redis挂了,请求都访问数据库
- 对缓存数据设置相同过期时间,导致某段时间全部失效,请求到数据库
解决:
- redis挂了
- 事发前:redis高可用,主从加哨兵或者集群
- 事发中:本地缓存加限流
- 事发后:redis持久化,重启后恢复数据
- 同时过期
- 对缓存过期时间加随机值,避免在同一时间过期
项目中的使用
访客管理项目中
- 用来缓存爬取到的学校官网首页信息,用string放到redis,设置了一天的过期时间。
- 缓存了过去访问量图表信息,不用每次读数据库,延时双删
- 考虑到我们数据量不大,开启了AOF预写日志持久化,设定了always每写一条同步一次
flink实践
- 计算uv的时候考虑大量userid去重无法存在set或redis中,使用布隆过滤器,redis储存位图及count值。设置需求两倍大小减小hash碰撞的可能。
- 使用了hash,定一个位图,hash函数为每一位字符ascii码值乘seed做叠加
key到期是立马删除吗?
在过期时间上再加了个10秒随机时间假设了缓存雪崩场景。
kafka2.4.0
注意版本问题,尤其和spark的
介绍
scala编写的一个高吞吐的分布式发布订阅系统
项目里的使用
相比于其它消息队列
常见消息队列
RabbitMQ、Redis、zeroMQ、ActiveMQ(吞吐量小,容易阻塞)
kafka的优势
- 可靠性:分布式的,分区、副本等
- 可扩展性:轻松缩放不用停机
- 持久性:分布式提交日志,消息尽可能快保存在磁盘。
- 性能:高吞吐量
- 快:零停机和零数据丢失
架构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jDsxa1cu-1664110283011)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220226231621745.png)]](https://img-blog.csdnimg.cn/8ba4054255c6406ea72e85cc8b8bf0a4.png)
- Broker:kafka集群中包含一个或多个服务实例,这种服务实例称为broker
- Topic:每条消息发到kafka都有一个类别,就是topic
- partition:物理上的概率,一个topic包含多个partition
- producer:发布消息到kafka的broker中
- consumer:向kafka的broker读取消息的客户端
- consumer group:每一个consumer属于一个特定的consumer group
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ADc4K4jW-1664110283012)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220226232535607.png)]](https://img-blog.csdnimg.cn/5f5af4b75c294be79ccf11677f4235a3.png)
zookeeper集群:保存了生产者、broker、消费者元数据
如消费者的偏移量(高级保存到zk、低级的在kafka)、分区的主分区等
kafka能做到消费有序性吗?
- 设置一个大分区,一个主题下一个分区
为什么topic下多个分区不能保证有序?
- 生产者生产数据到broker的多个分区,每个分区的数据是相对有序的,但整体的数据就无序了。因为消费者在消费时时一个个分区进行消费的,不能保证全局有序。
分区与消费者组的关系?
- 同一组的消费者对于同一消息只消费一次
- 某一主题下的分区数,对于消费者组来说,应该小于等于该主题下的分区数(不然有一个消费者将空闲)
消费者和生产者能操作的最小单元是分区,也就是不可能只消费一条数据
所以分区内有序但整体不一定有序
★同一个消费者组里面不能是同时消费者消费消息,只能有一个消费者去消费
生产者分区策略
-
没有指定分区号、没指定key根据轮询的方式发送到不同分区
-
没有指定分区号,指定了key,根据key.hashcode%numPartition
可以给key加个随机值避免数据倾斜
-
指定了分区号、指定了key,数据写到指定分区
-
自定义分区策略
-
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DkDrsTcd-1664110283013)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220227162427125.png)]](https://img-blog.csdnimg.cn/560a4ed9ec28490cb16b7bba01cc9da3.png)
数据丢失
-
生产者方面
-
同步模式:配置=1(只有leader收到,-1所以副本成功,0不等待)leader挂了数据丢失
解决:设置-1,写入所以副本才算成功
-
异步模式:当缓冲区满,如果配置为0(没有收到确认,一满就会丢弃),数据立刻丢弃
解决:不限制阻塞超时时间。一满生产者就阻塞
-
-
broker方面
- 采用副本分片机制,保证高可用
-
consumer方面
-
消费数据到hbase或者mysql中,如果hbase在这个时候连接不上(网络抖动),会抛出异常,如果在处理数据的时候已经进行了提交,那么kafka上的offset已经进行了修改,但是hbase没有数据,造成数据丢失。主要因为offset使用了异步提交
解决:
- consumer处理完数据后再修改提交偏移量,,将默认自动提交改为手动提交
- 流式计算中,receiver预写日志(开启WAL,失败可恢复)director(checkpoint保证)即预写日志和checkpoint
-
数据重复
落表(主键或唯一索引的方式,避免重复数据)
业务逻辑处理(选择唯一主键存储到redis或mongodb,查询是否存在,不存在则先插入在进行业务逻辑处理)
数据过大也可考虑布隆过滤器
kafka数据查找过程?
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GNYrpzLe-1664110283013)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220227163220143.png)]](https://img-blog.csdnimg.cn/29b9181d13dd4f32898752c2317caf74.png)
分区中以segment段划分,达到一个g划分一个segment
-
通过offset确定数据在哪一个segment
-
查找对应的segment里面的index文件,index文件哦都是key/value对的。key为log中对应的顺序,value记录了这条数据在全局的标号。如果能直接找到对应的offset直接去获取对应数据
如果index文件里没有存储offset,就会找最近的一个offset,例如找不到7就去6,再取下一条数据
kafka auto.offset.reset
earliest
分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时从头开始消费
latest
当分区下有已提交offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
none
topic各分区都存在已提交offset时,从offset后开始消费;只要有一个分区不存在已提交offset则报错
latest情况(默认)
先发送了几条消息 1 2 3——————》topic order
此时启动消费者1,所有分区都没有offset,不消费
又发送了几条消息 4 5 6 -------》topic order
此时消费者可消费到4 5 6,但 1 2 3 消费不到
earliest
先发送了几条消息 1 2 3——————》topic order
此时启动消费者1,此时无offset,从头消费 1 2 3
又发送了几条消息 4 5 6 -------》topic order
消费者正常消费
latest容易丢失消息,如果kafka突然出错,依然在往topic写入,此时重启kafka会按最新offset开始消费,前面的就丢失了
oozie和azkaban对比
https://www.cnblogs.com/gxgd/p/8671271.html
ES-6.7.0(了解)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FzjUyMip-1664110283014)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220227224522018.png)]](https://img-blog.csdnimg.cn/c05223d4277a499286a27ad2f3a41419.png)
简而言之
- mysql无法满足大数据量的实时存储查询
- 出现了lucene全文检索,但是api不好用效率太低
- 出现了sorl,但是建立索引时搜索能力急速下降,即导入数据时查询很慢
- 出现了ES,基于RESTful web接口,拓展方便,接近实时搜索海量数据
介绍
开源分布式全文检索引擎,近乎实时存储检索数据。扩展性良好。
信息检索相关企业可用,法律类、车管类、金融类
对比结构
Relational DB-> Database ->Tables ->Rows ->Columns
Hbase -> nameSpace->ns:Table ->rowkey ->列族下一个个列
ElasticSearch ->Index -> Types -> Documents->Fields
基本类型
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6r1WRc6G-1664110283015)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220301144007904.png)]](https://img-blog.csdnimg.cn/8a2dc110e83543f2aae179a144967f1a.png)
类型在7.x版本以后消失
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZYmn0cHX-1664110283016)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220301144154408.png)]](https://img-blog.csdnimg.cn/31d667ac03e94ed4864b268ffd6e7d4f.png)
基本操作
1.创建索引
curl -XPUT http://node01:9200/blog01/?pretty
2.插入文档
curl -XPUT http://hadoop01:9200/blog01/article/1?pretty -d '{"id":"1","title":"what is lecene"}'
3.查询文档
curl -XGET http://hadoop01:9200/blog01/article/1?pretty
4.更新文档
curl -XPUT http://hadoop01:9200/blog01/article/1?pretty -d '{"id":"1","title":"what is elasticsearch"}'
5.搜索文档
curl -XGET "http://hadoop01:9200/blog01/article/_search?q=title:elasticsearch"
6.删除文档
curl -XDELETE "http://hadoop01:9200/blog01/article/1?pretty"
7.删除索引
curl -XDELETE http://hadoop01:9200/blog01?pretty
返回值说明及常用查询
返回值说明
- hits
- took
- shard
- timeout
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CvgjiWmJ-1664110283016)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220301145458554.png)]](https://img-blog.csdnimg.cn/dd2d4bd26446414a9ac5875ccc903ccd.png)
es中配置mappings及settings
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cjqdWfGm-1664110283017)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220301145901194.png)]](https://img-blog.csdnimg.cn/c9977c60f78c4581affdc547e56fb0d0.png)
分片交互过程
创建索引
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ljWOgpY2-1664110283018)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220301150147488.png)]](https://img-blog.csdnimg.cn/af05d72f23fe4a0fbef5ca3a0a002485.png)
删除索引
查询索引
scala-2.12.11
spark-3.0.1 -2.4.0
介绍
apache spark是用于大规模数据处理的统一的分析计算引擎
基于内存计算,提高实时性,同时保证了高容错和高可伸缩性。
spark比较吃内存,不能像hadoop部署在廉价机器上
从项目介绍自己的使用
与hadoop区别
spark相比hadoop有较大优势,但并不完全替代hadoop,spark主要用于替代hadoop中的mapreduce计算模型,存储依然可使用hdfs,但是中间结果放内存中,调度可用spark内置的也可用成熟的yarn调度。
个人使用时是部署的with hadoopXX版本,借助yarn实现资源调度管理,借助hdfs分布式存储
spark对硬件要求比hadoop要高,对内存和cpu有一定要求
特点
-
快
与hadoop的mapreduce相比,spark基于内存的运算要快100倍以上,基于硬盘的运算也要快10倍以上,spark实现了高效的DAG执行引擎,可通过基于内存来高效处理数据流
-
易用
spark支持多种语言,以及很多高级算法,且支持交互式的scala和python的shell。
-
通用
提高了统一的解决方案,批处理、交互式查询(sparksql)、实时流处理(streaming)、机器学习(MLlib)和图计算(GraphX)。减少开发和维护的成本
-
兼容性
方便和其它开源产品融合,可使用yarn和mesos作为资源管理和调度器,可处理hadoop支持的数据。方便搭建了hadoop集群的不需要做数据迁移即可使用spark的计算处理。同时standalone也可以不依赖第三方。
运行模式
-
local本地模式
本地开发使用,idea线程模拟
-
standalone
开发测试用,master/slave模式
-
Stand alone-HA
使用zk搭建高可用
-
on yarn集群
由yarn负责资源管理,spark负责任务调度和计算。
计算资源按需伸缩,集群利用率高,共享底层存储。
FIFO(大小任务在一个队列容易阻塞)
Fair:公平调度
Capacity(容量):默认的,多一个队列,大任务和小任务
-
on mesos
运行在mesos资源管理框架,国内用的少
-
on cloud
如AWS和EC2,
spark shell
提交任务和交互式测试,入门学习使用
spark-shell --master local[N\*]
spark-shell --master spark://hadoop01:7077,hadoop02:7077
##集群上
shell-submit
-
提交到standalone
/export/servers/spark/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master saprk://hadoop01:7077 \ --executor-memory 1g \ --total-executor-cores 2 \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \ 10 -
提交到standalone-HA
/export/ servers/spark/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://hadoop01:7077,hadoop01:7077 \ #轮询 --executor-memory 1g\ --total-executor-cores 2 \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \ 10#并行度 -
提交到yarn集群(cluster) 生产中大多为cluster部署模式
/export/servers/spark/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ --driver memory 1g \ #收集最终结果时,广播变量时 --executor-memory 1g \ --executor-cores 2 \ --queue default \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \ 10 #Driver是在nodemanager节点上的![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SxdFLLap-1664110283018)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220302140643838.png)]](https://img-blog.csdnimg.cn/e6e87eee54004c038d657bcfbedfab7d.png)
-
提交到yarn(client) 学习测试时使用
driver在客户端上
客户端影响很大,客户端终止了任务就终止了
/export/servers/spark/bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode client \ --driver memory 1g \ #收集最终结果时,广播变量时 --executor-memory 1g \ --executor-cores 2 \ --queue default \ /export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \ 10
wordcount
- idea手写本地
集群下需修改参数
1.setMaster需去掉,提交时指定
2.路径需修改(定为个参数)
rdd
弹性分布式数据集
不可变,可分区,元素可并行计算的集合。
五大属性
- 分区列表,分片数决定并行度
- 函数作用每个分区
- 依赖关系
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UGGxYx2f-1664110283019)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220302142455613.png)]](https://img-blog.csdnimg.cn/1f2b58ee0a514b678492380773bef96c.png)
5.数据本地性
创建RDD方式
-
读取文件(sc.textFile)(wholeTextFile:文件夹下大量小文件KV)
-
通过已有rdd转换
-
读取scala集合创建(sc.parallelize)
transformation算子
- Transformation转换操作,返回值为RDD,懒加载
- Action返回值不是RDD,任务提交
-
map和mapPartitions
前者处理一个个元素,后者为处理一个个分区内的数据集合(迭代器)
-
reduceByKey和groupByKey
reduceByKey性能更高,会在map端进行一次聚合,后者没有,则造成更多的磁盘文件读写,以及网络传输损耗更多
-
join
宽窄依赖
-
reparttion和coalesce
- 看看源码
action算子
-
collect
数组形式返回数据集到driver
-
conutByKey
可检查数据倾斜,查看key分布情况
-
foreach和foreachPartition
例如在连数据库时,数据量大的话不能foreach对每一个元素,
spark的checkpoint
更加可靠的数据持久化,放到HDFS上,比内存和磁盘都安全。实现了rdd的高容错和高可靠。
sc.setcheckpointDir( "hdfs://hadoop01:8020/ckpdir")
//设置检查点目录,会立即在HDFS上创建一个空目录
val rdd1 = sc.textFile("hdfs://node01:8020/wordcount/input/words.txt").flatMap(_ .split(" ")).map(( ,1)).reduceByKey(_+_)
rdd1.checkpoint //对rdd1进行检查点保存
rdd1.collect //Action操作才会真正执行checkpoint
//后续如果要使用到rdd1可以从checkpoint中读取
持久化和checkpoint区别
-
位置
persist和cache只能保存在本地
checkpoint可用保存数据到HDFS这类可靠的存储上
-
生命周期
cache和persist的RDD会在程序结束后被清除或手动调用unpersist方法
checkpoint的RDD在程序结束依然存在,不会被删除
-
依赖关系
persist和cache不会丢掉RDD间的依赖关系,因为这种缓存不可靠,如果出现问题需要回溯依赖关系重新计算
checkpoint会斩断依赖链,因为checkpoint会把结果保存在HDFS这类存储中,更加安全可靠,一般不需要回溯依赖链
rdd依赖关系
- 窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
- 宽依赖:父RDD的一个分区会被子RDD多个分区依赖(shuffle)
shuffle影响性能,窄依赖能并行计算(shuffle产生磁盘io、网络io、产生排序)
设计宽窄依赖的作用
-
窄依赖
- spark可以并行计算
- 如果有一个分区数据丢失,只需从父RDD的对应一个分区重新计算,无需重新计算整个任务,提高容错。
-
宽依赖
- 是划分stage的依据
-
特殊
join可以是宽依赖也可以是窄依赖
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HwksIwRT-1664110283020)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220302220616740.png)]](https://img-blog.csdnimg.cn/67e6fcc7f5a14be69850af2a8dd7a020.png)
如果在join之前做groupbyKey就不会发生shuffle了
DAG
数据转换执行的过程,有方向无闭环(RDD执行流程)
原始的RDD通过一系列转换操作形成了DAG有向无环图,任务执行时可以按照DAG描述,执行真正的计算。
一个Spark应用中可以有一到多个DAG,取决于触发了多少次action。一个DAG代表一个Job**
每个DAG划分为stage,stage可以并行计算。
stage划分
为什么要划分stage?
一个复杂逻辑如果有shuffle,意味着前面阶段产生结果才能执行下一阶段。按宽窄依赖进行划分,在同一个stage可以并行执行平行的分区。
如何划分stage和task?
spark根据shuffle使用回溯算法对DAG进行stage划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前RDD加入到当前stage。
每个 stage 里面 task 的数目由该 stage 最后一个 RDD 中的 partition 个数决定。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KPNIY27c-1664110283021)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220303121911251.png)]](https://img-blog.csdnimg.cn/3938c3f3a5334f1aa87491e6a75bb81f.png)
spark程序运行流程*
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GpThIyM8-1664110283021)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220303121943617.png)]](https://img-blog.csdnimg.cn/80f145b0fa074348ab2635546c40a665.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0HhSfB0z-1664110283022)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220303122224163.png)]](https://img-blog.csdnimg.cn/8f95a1cbb2824364b745523f7cc606c7.png)
- 任务遇到action算子,driver端启动一个SC,SC向资源管理器注册申请资源,资源管理器给分配Executor资源。
- SC构建DAG并分解为stage以taskSet发送给task schedule,executor再向SC注册申请task。task schedule将task发送给executor执行
- 计算完之后sc将executor注销
DF和DS(sparksql)
- DataFrame
DF前身为SchemaRDD,1.3之后不再继承自RDD。
是一种以RDD为基础的分布式数据集,类似数据库二维表,带有schema元信息。
- DataSet
1.6添加的新接口
与RDD相比保存了更多描述信息,类似二维表。
与DF相比,保存了类型信息,强类型的,有编译时的类型检查。
2.0后两者统一,DF表示为DS[Row]
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-REH43sfh-1664110283023)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220303125725651.png)]](https://img-blog.csdnimg.cn/eb9a2e1406af4a1aa054e0dcc7508d2d.png)
DF=RDD-泛型+schema+SQL+优化
DF=DS[Row]
DS=DF+泛型
DS=RDD+Schema+SQL+优化
创建DF
由一个RDD,绑定样例类person,然后.toDF
注册表 .createOrReplaceTempView(“table_name”)
然后进行sql操作
也可以直接读文件为DF,但是没有完整schema信息
或者读parque文件或者json,方便。
指定列名转换DF
//指定类型
val rowRDD = linesRDD.map(line=>{line(0).toInt,line(1),line(2).toInt})
val personDF = rowRDD.toDF("id","name","age")
sparkStreaming原理
sparkStreaming基于spark core之上的实时计算框架。高吞吐和高容错。
Dstream本质上就是一系列时间上连续的RDD
reduceByKeyAndWindow
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object WordCount3 {
def main(args: Array[String]): Unit = {
//1.创建StreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5表示5秒中对数据进行切分形成一个RDD
//2.监听Socket接收数据
//ReceiverInputDStream就是接收到的所有的数据组成的RDD,封装成了DStream,接下来对DStream进行操作就是对RDD进行操作
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.操作数据
val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1))
//4.使用窗口函数进行WordCount计数
//reduceFunc: (V, V) => V,集合函数
//windowDuration: Duration,窗口长度/宽度
//slideDuration: Duration,窗口滑动间隔
//注意:windowDuration和slideDuration必须是batchDuration的倍数
//windowDuration=slideDuration:数据不会丢失也不会重复计算==开发中会使用
//windowDuration>slideDuration:数据会重复计算==开发中会使用
//windowDuration<slideDuration:数据会丢失
//下面的代码表示:
//windowDuration=10
//slideDuration=5
//那么执行结果就是每隔5s计算最近10s的数据
//比如开发中让你统计最近1小时的数据,每隔1分钟计算一次,那么参数该如何设置?
//windowDuration=Minutes(60)
//slideDuration=Minutes(1)
val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5))
wordAndCount.print()
ssc.start()//开启
ssc.awaitTermination()//等待优雅停止
}
}
使用updateStateByKey(func)进行累加
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object WordCount2 {
def main(args: Array[String]): Unit = {
//1.创建StreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5表示5秒中对数据进行切分形成一个RDD
//requirement failed: ....Please set it by StreamingContext.checkpoint().
//注意:我们在下面使用到了updateStateByKey对当前数据和历史数据进行累加
//那么历史数据存在哪?我们需要给他设置一个checkpoint目录
ssc.checkpoint("./wc")//开发中HDFS
//2.监听Socket接收数据
//ReceiverInputDStream就是接收到的所有的数据组成的RDD,封装成了DStream,接下来对DStream进行操作就是对RDD进行操作
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.操作数据
val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1))
//val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
//====================使用updateStateByKey对当前数据和历史数据进行累加====================
val wordAndCount: DStream[(String, Int)] =wordAndOneDStream.updateStateByKey(updateFunc)
wordAndCount.print()
ssc.start()//开启
ssc.awaitTermination()//等待优雅停止
}
//currentValues:当前批次的value值,如:1,1,1 (以测试数据中的hadoop为例)
//historyValue:之前累计的历史值,第一次没有值是0,第二次是3
//目标是把当前数据+历史数据返回作为新的结果(下次的历史数据)
def updateFunc(currentValues:Seq[Int], historyValue:Option[Int] ):Option[Int] ={
val result: Int = currentValues.sum + historyValue.getOrElse(0)
Some(result)
}
}
整合kafka
- Receiver接收。offset存在zk,在消费时为了保证数据不丢失再ckpt也存了offset,可能数据不一致。
- Direct直连,offset自己维护默认保存到ckpt,消除与zk不一致,手动+直连能达到精确一次性
package cn.itcast.streaming
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkKafka2 {
def main(args: Array[String]): Unit = {
//1.创建StreamingContext
val config: SparkConf =
new SparkConf().setAppName("SparkStream").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("./kafka")
//==============================================
//2.准备配置参数
val kafkaParams = Map("metadata.broker.list" -> "node01:9092,node02:9092,node03:9092", "group.id" -> "spark")
val topics = Set("spark_kafka")
val allDStream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
//3.获取topic的数据
val data: DStream[String] = allDStream.map(_._2)
//==============================================
//WordCount
val words: DStream[String] = data.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
shuffle
1.2之前都是hash based shuffle
1.2之后是sort based shuffle
hash shuffle
未优化前有大量中间小文件
优化后合并了中间小文件
sort shuffle
map任务按分区id和key对记录进行排序,然后放入内存缓存,全部结果写入一个数据文件,同时生成一个索引文件。类似mapreduce的shuffle
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-33FRSb0L-1664110283023)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220303140334140.png)]](https://img-blog.csdnimg.cn/9ec41b7c96104bedbd91d9af98644392.png)
tungsten 优化
使用堆外内存和新的内存管理模型。节省了内存空间和大量gc。提高性能
spark常见问题
内存溢出
spark Executor内存分三块,execution内存,storage内存,other内存
- execution内存:执行内存,join等,shuffle也先写内存再放磁盘。
- storage内存,broadcast,cache,persist数据。
- other内存,程序预留给自己的内存。
一般oom在execution内存,storage内存满了会自己清除旧的。
三种情况
- map内存溢出
- shuffle内存溢出
- driver内存溢出
-
Driver heap OOM
从Executor端收集数据回Driver端
解决:
1能避免到Driver端做的尽量在Executor端RDD操作。
2不能避免自己评估需要内存,增加Deiver内存大小。
(*)从数据库拉到deriver的对象太大
考虑将对象转换成executor端加载sc.textFile等,加大内存解决。
-
map task运行溢出
增大堆内内存
增大堆外内存(默认申请的堆外内存为executor的10%)
--conf spark.executor.memoryoverhead 2048M -
shuffle阶段
reduce task去map拉数据,一边拉数据一边聚合
- 增加聚合内存比例
- 增加executor内存
- 减少拉取的数据量
gc导致shuffle文件拉取失败
有时报错shuffle file not found,再跑一遍就好了
增大重试次数和等待时间间隔即可
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries","6")
.set("spark.suffle.io.retryWait")
yarn-cluster模式jvm栈内存溢出
client模式driver在本地,JVM永久代为128M,而cluster模式在集群节点上默认是82M
提交时修改即可
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -xx:MaxPermSize=256M"
spark性能调优
数据仓库
parquet
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ArGF6qiE-1664110283024)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220410202450334.png)]](https://img-blog.csdnimg.cn/5095db2865e04cbfa6eed5f93a3b4b93.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-usxhJ96X-1664110283025)(C:\Users\宋大帅\AppData\Roaming\Typora\typora-user-images\image-20220410202545396.png)]](https://img-blog.csdnimg.cn/265c78e807fa4628a1564ec4ce900e89.png)
自解释的数据类型,自身内容包含对自身结果的描述
通常用于Impala、spark
和ORC主要区别:ORC支持ACID和update操作
hive 0.13之后支持行级别的ACID就是仅支持ORC格式
ORC
它并不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗
ORC列式存储
由于OLAP查询的特点,列式存储可以提升其查询性能,但是它是如何做到的呢?这就要从列式存储的原理说起,从图1中可以看到,相对于关系数据库中通常使用的行式存储,在使用列式存储时每一列的所有元素都是顺序存储的。由此特点可以给查询带来如下的优化:
- 查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍,另外可以保存每一列的统计信息(min、max、sum等),实现部分的谓词下推。
- 由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步减小I/O。
- 由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。
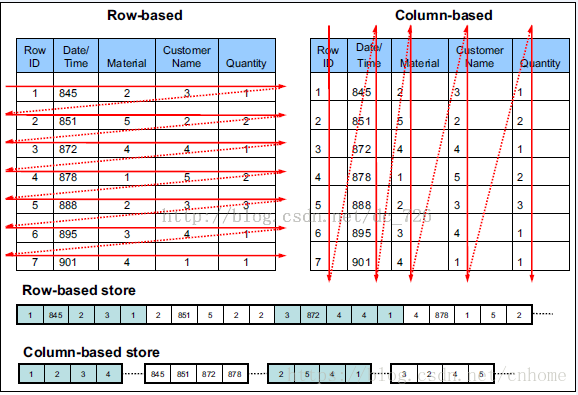
ORC、Parquet两者的对比
https://blog.csdn.net/lsr40/article/details/107975889
83023)]
tungsten 优化
使用堆外内存和新的内存管理模型。节省了内存空间和大量gc。提高性能
spark常见问题
内存溢出
spark Executor内存分三块,execution内存,storage内存,other内存
- execution内存:执行内存,join等,shuffle也先写内存再放磁盘。
- storage内存,broadcast,cache,persist数据。
- other内存,程序预留给自己的内存。
一般oom在execution内存,storage内存满了会自己清除旧的。
三种情况
- map内存溢出
- shuffle内存溢出
- driver内存溢出
-
Driver heap OOM
从Executor端收集数据回Driver端
解决:
1能避免到Driver端做的尽量在Executor端RDD操作。
2不能避免自己评估需要内存,增加Deiver内存大小。
(*)从数据库拉到deriver的对象太大
考虑将对象转换成executor端加载sc.textFile等,加大内存解决。
-
map task运行溢出
增大堆内内存
增大堆外内存(默认申请的堆外内存为executor的10%)
--conf spark.executor.memoryoverhead 2048M -
shuffle阶段
reduce task去map拉数据,一边拉数据一边聚合
- 增加聚合内存比例
- 增加executor内存
- 减少拉取的数据量
gc导致shuffle文件拉取失败
有时报错shuffle file not found,再跑一遍就好了
增大重试次数和等待时间间隔即可
val conf = new SparkConf()
.set("spark.shuffle.io.maxRetries","6")
.set("spark.suffle.io.retryWait")
yarn-cluster模式jvm栈内存溢出
client模式driver在本地,JVM永久代为128M,而cluster模式在集群节点上默认是82M
提交时修改即可
--conf spark.driver.extraJavaOptions="-XX:PermSize=128M -xx:MaxPermSize=256M"
spark性能调优
数据仓库
parquet
[外链图片转存中…(img-ArGF6qiE-1664110283024)]
[外链图片转存中…(img-usxhJ96X-1664110283025)]
自解释的数据类型,自身内容包含对自身结果的描述
通常用于Impala、spark
和ORC主要区别:ORC支持ACID和update操作
hive 0.13之后支持行级别的ACID就是仅支持ORC格式
ORC
它并不是一个单纯的列式存储格式,仍然是首先根据行组分割整个表,在每一个行组内进行按列存储。ORC文件是自描述的,它的元数据使用Protocol Buffers序列化,并且文件中的数据尽可能的压缩以降低存储空间的消耗
ORC列式存储
由于OLAP查询的特点,列式存储可以提升其查询性能,但是它是如何做到的呢?这就要从列式存储的原理说起,从图1中可以看到,相对于关系数据库中通常使用的行式存储,在使用列式存储时每一列的所有元素都是顺序存储的。由此特点可以给查询带来如下的优化:
- 查询的时候不需要扫描全部的数据,而只需要读取每次查询涉及的列,这样可以将I/O消耗降低N倍,另外可以保存每一列的统计信息(min、max、sum等),实现部分的谓词下推。
- 由于每一列的成员都是同构的,可以针对不同的数据类型使用更高效的数据压缩算法,进一步减小I/O。
- 由于每一列的成员的同构性,可以使用更加适合CPU pipeline的编码方式,减小CPU的缓存失效。
ORC、Parquet两者的对比
https://blog.csdn.net/lsr40/article/details/107975889














 5389
5389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









