








 超级会员免费看
超级会员免费看



灵巧的抓取仍然是机器人技术中一个基本但具有挑战性的问题。通用机器人必须能够在任意场景中抓取各种物体。但是,现有研究通常依赖于特定的假设,例如单对象设置或有限环境,从而导致受约束的泛化。我们的解决方案是 DexGraspVLA,这是一个分层框架,它利用预先训练的视觉语言模型作为高级任务规划器,并学习基于扩散的策略作为低级动作控制器。关键的见解在于将不同的语言和视觉输入迭代地转换为领域不变的表示,由于域偏移的缓解,模仿学习可以得到有效应用。因此,它可以在各种实际场景中实现稳健的泛化。值得注意的是,在 “零镜头” 环境中,我们的方法在数千个看不见的物体、照明和背景组合下实现了 90+% 的成功率。实证分析进一步证实了内部模型行为在环境变化中的一致性,从而验证了我们的设计并解释了其泛化性能。我们希望我们的工作可以成为实现一般灵巧抓握的一步。
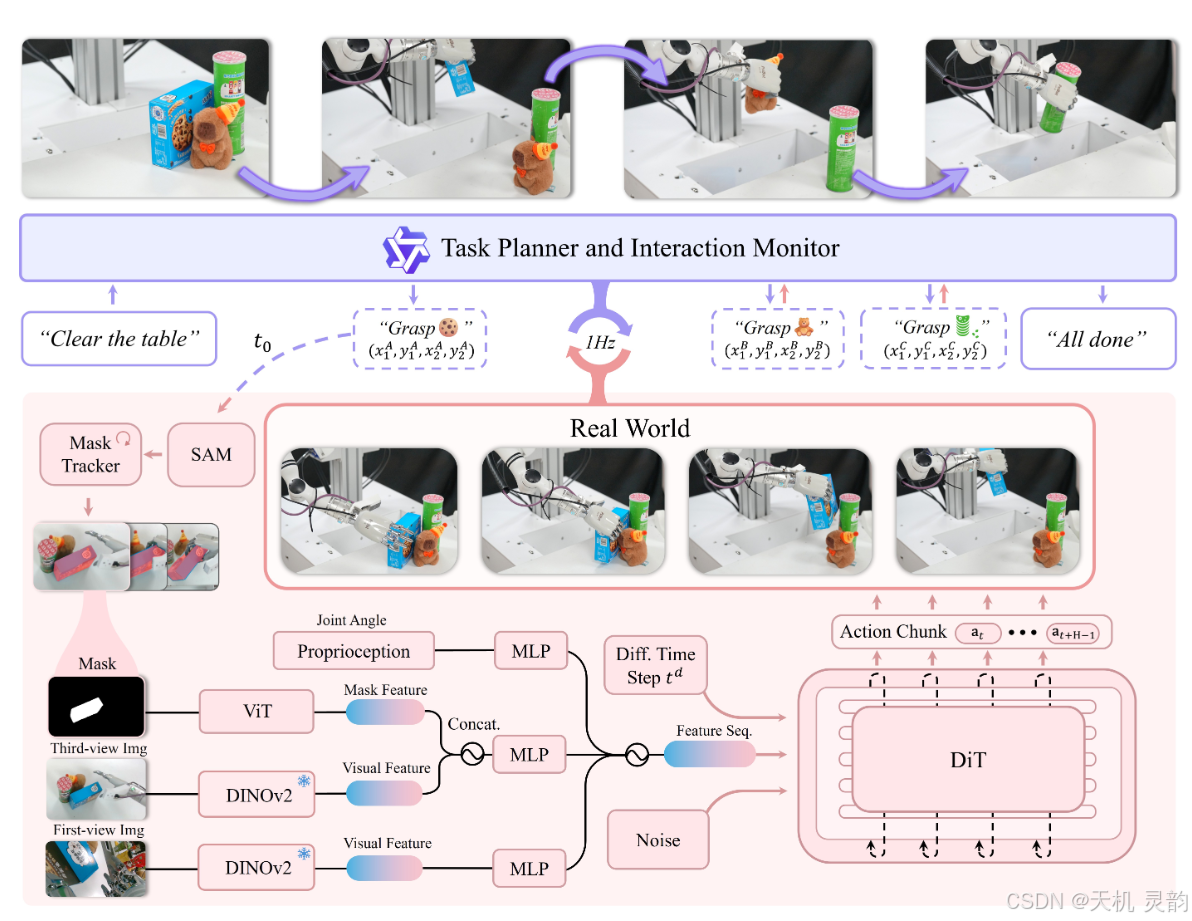
1. 引言:灵巧抓取的“圣杯”挑战
在机器人技术领域,

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











