







1.索引介绍
1.1什么是MySQL的索引
MySQL官方对于索引的定义:索引是帮助MySQL高效获取数据的数据结构。
MySQL在存储数据之外,数据库系统中还维护着满足特定查找算法的数据结构,这些数据结构以某种引用(指向)表中的数据,这样我们就可以通过数据结构上实现的高级查找算法来快速找到我们想要的数据。而这种数据结构就是索引。
简单理解为“排好序的可以快速查找数据的数据结构”。
例子:
如果现在有一张USER表,里面有name字段,我们想要查找值为赵六的那条数据,如果没有索引,我们要全局搜索,在第六次查到此条数据,如果使用二叉排序树,那我们只需要查找三次,效率翻倍!
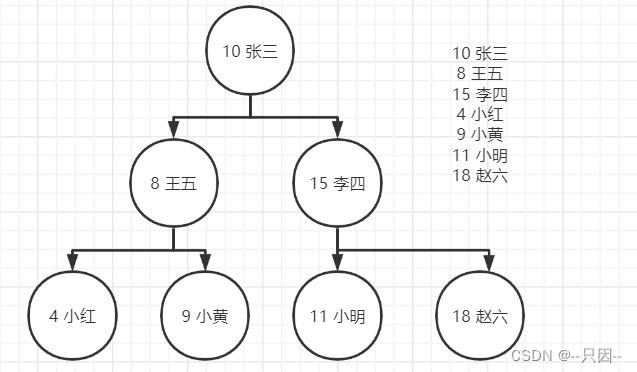
1.2索引数据结构
下图就是一种可能的二叉树的索引方式:
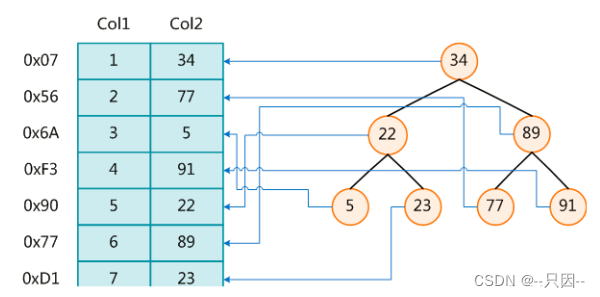
二叉树数据结构的弊端:当极端情况下,数据递增插入时,会一直向右插入,形成链表,查询效率会降低。
MySQL中常用的的索引数据结构有BTree索引(Myisam普通索引),B+Tree索引(Innodb普通索引),Hash索引(memory存储引擎)等等。
1.3索引优势
提高数据检索的效率,降低数据库的IO成本。
通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
1.4索引劣势
索引实际上也是一张表,保存了主键和索引的字段,并且指向实体表的记录,所以索引也是需要占用空间的。在索引大大提高查询速度的同时,却会降低表的更新速度,在对表进行数据增删改的同时,MySQL不仅要更新数据,还需要保存一下索引文件。每次更新添加了的索引列的字段,都会去调整因为更新带来的减值变化后的索引的信息。
1.5索引使用场景
哪些情况需要创建索引:
1.主键自动建立唯一索引
2.频繁作为查询条件的字段应该创建索引(where 后面的语句)
3.查询中与其它表关联的字段,外键关系建立索引
4.多字段查询下倾向创建组合索引
5.查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
6.查询中统计或者分组字段
哪些情况不推荐建立索引:
1.表记录太少
2.经常增删改的表
3.Where条件里用不到的字段不建立索引
1.6索引分类
1.6.1主键索引
1.表中的列设定为主键后,数据库会自动建立主键索引。
2.单独创建和删除主键索引语法:
创建主键索引语法:
alter table 表名 add primary key (字段);
删除主键索引语法:
alter table 表名 drop primary key;
1.6.2唯一索引
1.表中的列创建了唯一约束时,数据库会自动建立唯一索引。
2.单独创建和删除唯一索引语法:
创建唯一索引语法:
alter table 表名 add unique 索引名(字段);
或者
create unique index 索引名 on 表名(字段);
删除唯一索引语法:
drop index 索引名 on 表名;
1.6.3单值索引
即一个索引只包含单个列,一个表可以有多个单值索引。
1.建表时可随表一起建立单值索引
2.单独创建和删除单值索引:
创建单值索引:
alter table 表名 add index 索引名(字段);
或者
create index 索引名 on 表名(字段);
删除单值索引:
drop index 索引名 on 表名;
1.6.4复合索引
即一个索引包含多个列:
1.建表时可随表一起建立复合索引
2.单独创建和删除复合索引:
创建复合索引:
create index 索引名 on 表名(字段1,字段2);
或者
alter table 表名 add index 索引名(字段,字段2);
删除复合索引:
drop index 索引名 on 表名;
例子:
首先我们随表创建索引

在设计表中我们可以查看创建的索引

我们也可以在创建表之后添加索引
将之前创建的表删除 再创建不带索引的表

现在没有任何索引


然后通过1.6中的命令进行增加删除索引,这里不再概述!
#创建主键索引
alter table customer add primary key(id);
#删除主键索引
alter table customer drop primary key;
#创建唯一索引
alter table customer add unique idx_customer_no(customer_no);
#删除唯一索引
drop index idx_customer_no on customer;
#创建单值索引
alter table customer add index idx_customer_name(customer_name);
#删除单值索引
drop index idx_customer_name on customer;
#创建复合索引
alter table customer add index idx_customer_no_name(customer_no,customer_name);
#删除复合索引
drop index idx_customer_no_name on customer;
1.7索引测试
1.通过存储过程往数据库中插入300W条数据。
2.分别测试使用索引和没有使用索引的情况下,where查询的一个效率对比。
例子:
-- 建表
DROP TABLE IF EXISTS person;
CREATE TABLE person (
PID int(11) AUTO_INCREMENT COMMENT '编号',
PNAME varchar(50) COMMENT '姓名',
PSEX varchar(10) COMMENT '性别',
PAGE int(11) COMMENT '年龄',
SAL decimal(7, 2) COMMENT '工资',
PRIMARY KEY (PID)
);
-- 创建存储过程
create procedure insert_person(in max_num int(10))
begin
declare i int default 0;
set autocommit = 0;
repeat
set i = i +1;
insert into person (PID,PNAME,PSEX,PAGE,SAL) values (i,concat('test',floor(rand()*10000000)),IF(RAND()>0.5,'男','女'),FLOOR((RAND()*100)+10),FLOOR((RAND()*19000)+1000));
until i = max_num
end repeat;
commit;
end;
-- 调用存储过程
call insert_person(30000000);
-- 不使用索引,根据pName进行查询
select * from person where PNAME = "test1209325"; #10.813S
-- 给PNAME建立索引
alter table person add index idx_pname(PNAME);
select * from person where PNAME = "test1209325"; # 0.032S
select * from person where PID = 2800000; #0.021
可以看到,添加了普通索引,查询效率提高了很多!
















 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









