







目录
# 定义书籍模型类
class BookInfo(models.Model):
btitle = models.CharField(max_length=20) # 书籍名称
bpub_date = models.DateField() # 发布日期
bread = models.IntegerField(default=0) # 阅读量
bcomment = models.IntegerField(default=0) # 评论量
isDelete = models.BooleanField(default=False) # 逻辑删除
# 定义英雄模型类
class HeroInfo(models.Model):
hname = models.CharField(max_length=20) # 英雄姓名
hgender = models.BooleanField(default=True) # 英雄性别,True为男
hcomment = models.CharField(max_length=200) # 英雄描述信息
hbook = models.ForeignKey(BookInfo, on_delete=models.DO_NOTHING) # 英雄与书籍关系为一对多下面所有例子均使用上面两个模型类
一、定义属性
Django根据属性的类型确定以下信息:
- 当前选择的数据库支持字段的类型
- 渲染管理表单时使用的默认html控件
- 在管理站点最低限度的验证
django会为表创建自动增长的主键列,每个模型只能有一个主键列,如果使用选项设置某属性为主键列后django不会再创建自动增长的主键列。
默认创建的主键列属性为id,可以使用pk代替,pk全拼为primary key。
注意:pk是主键的别名,若主键名为id2,那么pk是id2的别名。
属性命名限制:
- 不能是python的保留关键字。
- 不允许使用连续的下划线,这是由django的查询方式决定的
- 定义属性时需要指定字段类型,通过字段类型的参数指定选项,语法如下:
属性=models.字段类型(选项)字段类型
使用时需要引入django.db.models包,字段类型如下:
- AutoField:自动增长的IntegerField,通常不用指定,不指定时Django会自动创建属性名为id的自动增长属性。
- BooleanField:布尔字段,值为True或False。
- CharField(max_length=字符长度):字符串。
- 参数max_length表示最大字符个数。
- TextField:大文本字段,一般超过4000个字符时使用。
- IntegerField:整数。
- DecimalField(max_digits=None, decimal_places=None):十进制浮点数。
- 参数max_digits表示总位数。
- 参数decimal_places表示小数位数。
- FloatField:浮点数。
- DateField[auto_now=False, auto_now_add=False]):日期。
- 参数auto_now表示每次执行.save保存对象时,自动设置该字段为当前时间(不是数据库默认回填),用于"最后一次修改"的时间戳,它总是使用当前日期,默认为false。
- 参数auto_now_add表示当对象第一次被创建时自动设置当前时间,用于创建的时间戳,它总是使用当前日期,默认为false。
- 参数auto_now_add和auto_now是相互排斥的,组合将会发生错误。
- TimeField:时间,参数同DateField。
- DateTimeField:日期时间,参数同DateField。
- FileField:上传文件字段。
选项
通过选项实现对字段的约束,选项如下:
- null:如果为True,表示允许为空,默认值是False。
- blank:如果为True,则该字段允许为空白,默认值是False。
- 注意:null是数据库范畴的概念,blank是表单验证范畴的。
- db_column:字段的名称,如果未指定,则使用属性的名称。
- db_index:若值为True, 则在表中会为此字段创建索引,默认值是False。
- default:默认值。
- primary_key:若为True,则该字段会成为模型的主键字段,默认值是False,一般作为AutoField的选项使用。
- unique:如果为True, 这个字段在表中必须有唯一值,默认值是False。
二、查询集
查询集表示从数据库中获取的对象集合,在管理器上调用某些过滤器方法会返回查询集,查询集可以含有零个、一个或多个过滤器。过滤器基于所给的参数限制查询的结果,从Sql的角度,查询集和select语句等价,过滤器像where和limit子句。
返回查询集的过滤器如下:
- all():返回所有数据。
- filter():返回满足条件的数据。
- exclude():返回满足条件之外的数据,相当于sql语句中where部分的not关键字。
- order_by():对结果进行排序。
返回单个值的过滤器如下:
- get():返回单个满足条件的对象
- 如果未找到会引发"模型类.DoesNotExist"异常。
- 如果多条被返回,会引发"模型类.MultipleObjectsReturned"异常。
- count():返回当前查询结果的总条数。
- aggregate():聚合,返回一个字典。
判断某一个查询集中是否有数据:
- exists():判断查询集中是否有数据,如果有则返回True,没有则返回False。
两大特性
- 惰性执行:创建查询集不会访问数据库,直到调用数据时,才会访问数据库,调用数据的情况包括迭代、序列化、与if合用。
- 缓存:使用同一个查询集,第一次使用时会发生数据库的查询,然后把结果缓存下来,再次使用这个查询集时会使用缓存的数据。
示例:查询所有,编辑booktest/views.py的index视图,运行查看。
# 不会执行查询
books = BookInfo.objects.all()
# 调用时执行查询
for book in books:
bid = book.id查询集的缓存
每个查询集都包含一个缓存来最小化对数据库的访问。
在新建的查询集中,缓存为空,首次对查询集求值时,会发生数据库查询,django会将查询的结果存在查询集的缓存中,并返回请求的结果,接下来对查询集求值将重用缓存中的结果。
限制查询集
可以对查询集进行取下标或切片操作,等同于sql中的limit和offset子句。
注意:不支持负数索引。
对查询集进行切片后返回一个新的查询集,不会立即执行查询。
如果获取一个对象,直接使用[0],等同于[0:1].get(),但是如果没有数据,[0]引发IndexError异常,[0:1].get()如果没有数据引发DoesNotExist异常。
示例:获取第1、2项,运行查看。
list=BookInfo.objects.all()[0:2]三、条件查询
条件运算符
1) 查询相等
exact:表示判相等。
例:查询编号为1的图书。
list=BookInfo.objects.filter(id__exact=1) # 字段与运算符使用双下划线连接
可简写为:
list=BookInfo.objects.filter(id=1)2) 模糊查询
contains:是否包含。
例:查询书名包含'传'的图书。
list = BookInfo.objects.filter(btitle__contains='传')startswith、endswith:以指定值开头或结尾。
例:查询书名以'部'结尾的图书
list = BookInfo.objects.filter(btitle__endswith='部')以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith
3) 空查询
isnull:是否为null。
例:查询书名不为空的图书。
list = BookInfo.objects.filter(btitle__isnull=False)4) 范围查询
in:是否包含在范围内。
例:查询编号为1或3或5的图书
list = BookInfo.objects.filter(id__in=[1, 3, 5])5) 比较查询
gt、gte、lt、lte:大于、大于等于、小于、小于等于。
例:查询编号大于3的图书
list = BookInfo.objects.filter(id__gt=3)不等于的运算符,使用exclude()过滤器。
list = BookInfo.objects.exclude(id=3)6) 日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
例:查询1980年发表的图书。
list = BookInfo.objects.filter(bpub_date__year=1980)例:查询1980年1月1日后发表的图书。
list = BookInfo.objects.filter(bpub_date__gt=date(1990, 1, 1))F对象
之前的查询都是对象的属性与常量值比较,两个属性怎么比较呢? 可使用F对象,被定义在django.db.models中。
语法如下:
F(属性名)例:查询阅读量大于等于评论量的图书。
from django.db.models import F
...
list = BookInfo.objects.filter(bread__gte=F('bcomment'))可以在F对象上使用算数运算。
例:查询阅读量大于2倍评论量的图书。
list = BookInfo.objects.filter(bread__gt=F('bcomment') * 2)Q对象
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
例:查询阅读量大于20,并且编号小于3的图书。
list=BookInfo.objects.filter(bread__gt=20,id__lt=3)
或
list=BookInfo.objects.filter(bread__gt=20).filter(id__lt=3)如果需要实现逻辑或or的查询,需要使用Q()对象结合|运算符,Q对象被义在django.db.models中。
语法如下:
Q(属性名__运算符=值)例:查询阅读量大于20的图书,改写为Q对象如下。
from django.db.models import Q
...
list = BookInfo.objects.filter(Q(bread__gt=20))Q对象可以使用&、|连接,&表示逻辑与,|表示逻辑或。
例:查询阅读量大于20,或编号小于3的图书,只能使用Q对象实现
list = BookInfo.objects.filter(Q(bread__gt=20) | Q(pk__lt=3))Q对象前可以使用~操作符,表示非not。
例:查询编号不等于3的图书。
list = BookInfo.objects.filter(~Q(pk=3))聚合函数
使用aggregate()过滤器调用聚合函数。聚合函数包括:Avg,Count,Max,Min,Sum,被定义在django.db.models中。
例:查询图书的总阅读量。
from django.db.models import Sum
...
list = BookInfo.objects.aggregate(Sum('bread'))注意aggregate的返回值是一个字典类型,格式如下:
{'聚合类小写__属性名':值}
如:{'sum__bread':3}使用count时一般不使用aggregate()过滤器。
例:查询图书总数。
list = BookInfo.objects.count()注意count函数的返回值是一个数字。
四、关联查询
关系型数据库的关系包括三种类型:
-
ForeignKey(模型类名称, on_delete=models.DO_NOTHING):创建外键,一对多关系,将字段定义在多的一端中。。
- on_delete:删除关联表中的数据时,当前表与其关联的field的行为
-
on_delete = models.CASCADE, # 删除主键表中数据时,外键表中与之关联需要先删除
-
on_delete = models.DO_NOTHING, # 删除关联数据,什么也不做
-
on_delete = models.PROTECT, # 删除关联数据,引发错误ProtectedError
-
on_delete = models.SET_NULL, # 删除关联数据,与之关联的值设置为null(前提FK字段需要设置为可空,一对一同理)
-
on_delete = models.SET_DEFAULT, # 删除关联数据,与之关联的值设置为默认值(前提FK字段需要设置默认值,一对一同理)
- ManyToManyField:多对多,将字段定义在任意一端中。
- OneToOneField:一对一,将字段定义在任意一端中。
- 可以维护递归的关联关系,使用'self'指定,详见"自关联"。
通过对象执行关联查询
根据主键表查询外键表,语法如下:
主键表实例对象.外键表模型名称_set例:查询图书id为1的所有英雄信息。
b = BookInfo.objects.get(id=1)
b.heroinfo_set.all() # 关联的模型类名需要小写等效于SQL语句:select * from booktest_heroinfo where hbook_id=(select id from booktest_bookinfo where id=1);
根据外键表查询主键表,语法如下:
外键表实例对象.创建外键时的变量名称例:查询HeroInfo对应的表中id为5的英雄关联的图书
hero = HeroInfo.objects.get(pk=3) # pk=3指的主键值为3
hero.hbook # HeroInfo模型类创建外键的变量是 hbook
等效于SQL语句:select * from booktest_bookinfo where id=(select hbook_id from booktest_heroinfo where id=5);
通过模型类执行关联查询
由多模型类条件查询一模型类数据,语法如下:
关联模型类名小写__属性名__条件运算符=值例:查询图书,要求图书中英雄的描述包含'六'。
BookInfo.objects.filter(heroinfo__hcontent__contains='六')等效于SQL语句:select * from booktest_bookinfo where id in (select hbook_id from booktest_heroinfo where hcomment like '%六%');
由一模型类条件查询多模型类数据,语法如下:
一模型类关联属性名__一模型类属性名__条件运算符=值例:查询书名为“天龙八部”的所有英雄。
HeroInfo.objects.filter(hbook__btitle='天龙八部')等效于SQL语句:select * from booktest_heroinfo where hbook_id in (select id from booktest_bookinfo where btitle="天龙八部");
五、执行原生 SQL 查询
官方执行原生SQL查询文档的地址:https://docs.djangoproject.com/zh-hans/3.1/topics/db/sql/
使用管理器方法 raw() 能用于执行原生 SQL 查询,语法如下:
Manager.raw(sql, params=None, translations=None)该方法接受一个原生 SQL 查询语句,执行它,并返回一个 django.db.models.query.RawQuerySet 实例。这个 RawQuerySet 能像普通的 QuerySet 一样被迭代获取对象实例。
例:查询BookInfo中所有书籍
books = BookInfo.objects.all()
# 等效于上面的代码
books = BookInfo.objects.raw('select * from booktest_bookinfo')例:查询HeroInfo对应的表中id为7的英雄关联的图书所有信息
hero = HeroInfo.objects.get(pk=3) # pk=3指的主键值为3
hero.hbook # HeroInfo模型类创建外键的变量是 hbook
# 等同于
BookInfo.objects.raw('select * from booktest_bookinfo where id=(select hbook_id from booktest_heroinfo where id=7)')
# 等同于
HeroInfo.objects.raw('select * from booktest_bookinfo where id=(select hbook_id from booktest_heroinfo where id=7)')使用raw()执行需要注意以下方面:
1、使用raw()时,查询出来的是一个 RawQuerySet 对象,能像普通的 QuerySet 一样被迭代获取对象实例。
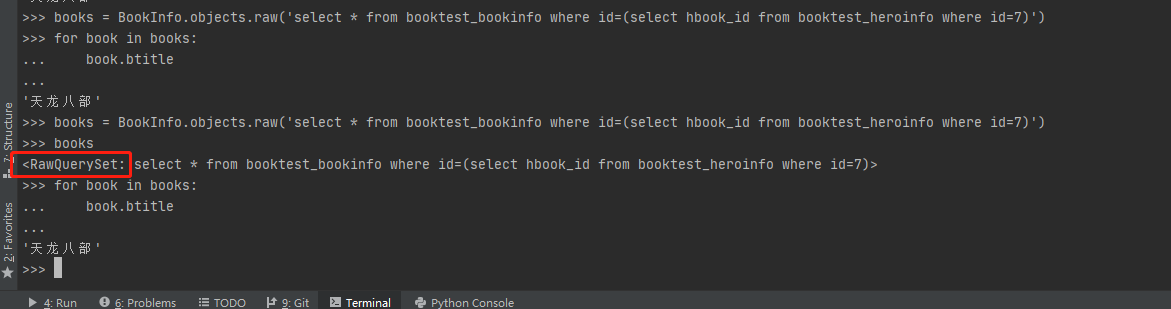
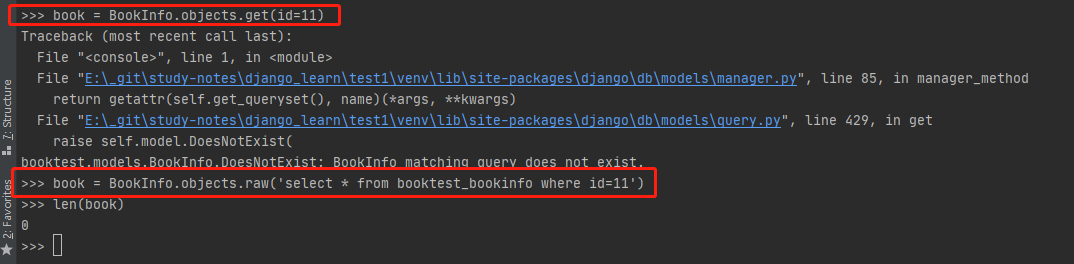
2、Django不会对传给 .raw() 的 SQL 语句做任何检查。如果查询的数据不存在会返一个空对象集,而不会像QuerySet 对象有提示
3、如果需要执行参数化的查询,可以使用 raw() 的 params 参数,防止SQL注入
>>> id = 7
>>> books = HeroInfo.objects.raw('select * from booktest_bookinfo where id=(select hbook_id from booktest_heroinfo where id=%s)', [id])
>>> for book in books:
... book.btitle
...
'天龙八部'
>>>不要写成如下样式,有SQL注入的风险
>>> query ='select * from booktest_bookinfo where id=(select hbook_id from booktest_heroinfo where id=%s)' %id
>>>HeroInfo.objects.raw(query)六、管理器Manager
前面的查询都是通过 模型类.objects.查询集,比如:BookInfo.objects.all() 那objects是什么东西呢?objects其实是Django帮我们自动生成的一个 models.Manager类的实例对象,也就是管理器,通过这个管理器可以实现对数据的查询。
自定义管理器
既然objects是一个实例对象,那我们也就能自己定义一个管理器。自定义管理器步骤如下:
- 自定义一个管理器类,这个类继承 models.Manager 类
- 在模型类中创建自定义的管理器类的实例对象
这个实例对象就是我们自定义的管理器
例:自定义BookInfo模型类的管理器为book,并查看所有书籍
# 自定义模型管理类
class BookInfoManager(models.Manager):
pass
# 定义书籍模型类
class BookInfo(models.Model):
btitle = models.CharField(max_length=20) # 书籍名称
bpub_date = models.DateField() # 发布日期
bread = models.IntegerField(default=0) # 阅读量
bcomment = models.IntegerField(default=0) # 评论量
isDelete = models.BooleanField(default=False) # 逻辑删除
# 自定义模型管理器
book = BookInfoManager()
def __str__(self):
return F"btitle:{self.btitle},bpub_date:{self.bpub_date}"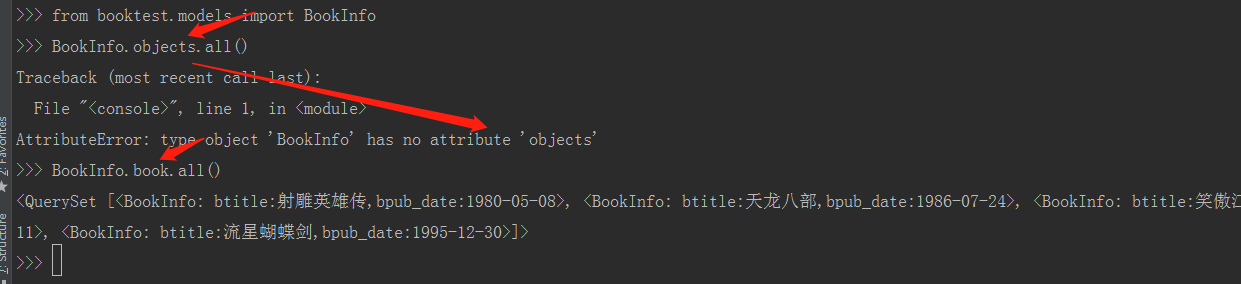
从上图中可以看出,一旦我们自定义管理器后,objects这个管理器就会失效。
自定义管理器类的作用
上面自定义的管理器类完全继承了 models.Manager ,没有做任何修改,这样是毫无意义。
自定义管理器类主要用于两种情况:
- 修改原始查询集,如重写all()方法
- 在管理器类中添加额外的方法,如向数据库中插入数据
1、 修改原始查询集
例如:返回数据库中 isDelete 等于0 的书籍

将上面的 BookInfoManager 修改成如下代码:
class BookInfoManager(models.Manager):
# 默认查询未删除的图书信息
# 调用父类的成员语法为:super().方法名
def all(self):
return super().all().filter(isDelete=0)在shell中调用 all() 方法

2、在管理器类中添加额外的方法
例如:在管理器类中创建一个添加书籍的 create_book 方法
# 自定义模型管理类
class BookInfoManager(models.Manager):
# 默认查询未删除的图书信息
# 调用父类的成员语法为:super().方法名
def all(self):
return super().all().filter(isDelete=0)
def create_book(self, title, bpub_date):
# 获取 self 所在的模型类。self此时表示实例化对象 objects ,objects所在的模型类就是 BookInfo,所以model_class此时指向的就是 BookInfo。
# 使用此方法可以避免因模型类修改名称而导致的实例化找不到类对象的问题
model_class = self.model
# 创建实例对象
book = model_class()
# book = BookInfo()
book.btitle = title
book.bpub_date = bpub_date
book.bread = 0
book.bcomment = 0
book.isDelete = 0
book.save()注:已将上面自定义的管理名从 book 改为 objects,这个objects仍为自定义的管理器

除了在管理器类中添加额外的方法,我们也能在模型类 BookInfo 中添加类方法来实现相同功能,如:
# 定义书籍模型类
class BookInfo(models.Model):
...
@classmethod
def cls_create_book(cls, title, bpub_date):
# cls 此时代表的是 BookInfo 这个类,book=cls() 也就是 book=BookInfo()
book = cls()
book.btitle = title
book.bpub_date = bpub_date
book.bread = 0
book.bcomment = 0
book.isDelete = 0
book.save()
但是,模型类主要是为了建立与数据库表之间的一种对应关系,假如在模型类中封装过多的方法,就会让模型类中多很多与数据表关联无关的内容,为了将模型类与数据库表之间的关系和操作数据库表的方法分离开,所以我们在管理器类中添加操作数据库表的方法。
django已为我们定义了一个创建的通用方法 create ,使用时需要以键值对的方式传入参数:

模型管理器类与模型类的关系
通过在模型类中创建模型管理器类的实例对象建立联系

七、元选项
模型类创建的数据表格的格式是:应用名_模型类名,比如BookInfo这个模型类,在数据库中是以booktest_bookinfo作为表名。此时,如果我们修改应用的名称为booktest2,那么模型类对应的表名就变成了 booktest2_bookinfo,但是这个模型类对应的表名已经生成了,此时再去调用这个模型类就会报错。
我们可以通过元选项 Meta 的db_table来指定模型类的表名,一旦指定表名,通过模型类创建的表就不再依赖应用名了。
# 定义书籍模型类
class BookInfo(models.Model):
btitle = models.CharField(max_length=20) # 书籍名称
bpub_date = models.DateField() # 发布日期
bread = models.IntegerField(default=0) # 阅读量
bcomment = models.IntegerField(default=0) # 评论量
isDelete = models.BooleanField(default=False) # 逻辑删除
# 自定义模型管理器
objects = BookInfoManager()
class Meta:
db_table = 'bookinfo'
db_table只是django元选项中常用的一个,更多选项请查阅 官方文档:https://docs.djangoproject.com/zh-hans/3.1/ref/models/options/
源码等资料获取方法

各位想获取源码的朋友请点赞 + 评论 + 收藏,三连!
三连之后我会在评论区挨个私信发给你们~















 1855
1855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









