







Sort
全排序
从map -> reduce ,shuffle过程中会根据key进行排序,但是这个排序只保证输入到每个reduce前的数据是有序的。那么如何产生一个全局排序的文件?最简单的方法是所有数据都在一个分区(如果不指定分区class,默认使用HashPartitioner),但是在处理大数据的时,显然不是个好注意。有一种思路:按照排序的key顺序划分partitioner,保证各个分区输出是有序的,然后将各个分区连接在一起,构成一个整体有序的文件。
但是如何均匀划分partitioner是一件简单而有困难的事情。简单,遍历一遍数据集,自然可以划分出来,困难,对于遍历整个数据集,当数据量大时,操作起来还是比较麻烦的。在数学统计上,有种方法叫抽样。幸运的是,Hadoop已经实现了若干抽样方法!
/**
* Interface to sample using an
* {@link org.apache.hadoop.mapreduce.InputFormat}.
*/
public interface Sampler<K,V> {
/**
* For a given job, collect and return a subset of the keys from the
* input data.
*/
K[] getSample(InputFormat<K,V> inf, Job job)
throws IOException, InterruptedException;
}InputSampler 类实现了Sampler接口。该接口通常不直接由客户端调用,而是InputSampler类的方法writePartitionFile()调用,目的是创建一个顺序文件来存储定义分区的键。
顺序文件由TotalOrderPartitioner使用,为排序作业创建分区。
public class SortByTemperatureUsingTotalOrderPartitioner extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this,getConf(),strings);
if (job == null){
return -1;
}
job.setInputFormatClass(SequenceFileInputFormat.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputFormatClass(SequenceFileOutputFormat.class);
SequenceFileOutputFormat.setCompressOutput(job,true);
SequenceFileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
SequenceFileOutputFormat.setOutputCompressionType(job, SequenceFile.CompressionType.BLOCK);
// 分区
job.setPartitionerClass(TotalOrderPartitioner.class);
//抽样
//采样率 0.1 样本数10000 最大分区 10
InputSampler.Sampler<IntWritable,Text> sampler = new InputSampler.RandomSampler<IntWritable, Text>(0.1,10000,10);
InputSampler.writePartitionFile(job,sampler);
//Add to DistributedCache
Configuration configuration = job.getConfiguration();
String partitionFile = TotalOrderPartitioner.getPartitionFile(configuration);
URI uri = new URI(partitionFile);
job.addCacheFile(uri);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(
new SortByTemperatureUsingTotalOrderPartitioner(), args);
System.exit(exitCode);
}
}二次排序
在mapreduce程序中,在到达reduce前,记录会按照key进行排序。但是,键所对应的值并不会被排序。甚至在不同的执行轮次中,排序也不是固定的。因为它们来自不同的map任务且这些map任务在不同的轮次完成的时间各不相同。一般来说,程序会避免让reduce函数依赖于排序。但是,总有特殊的情况。
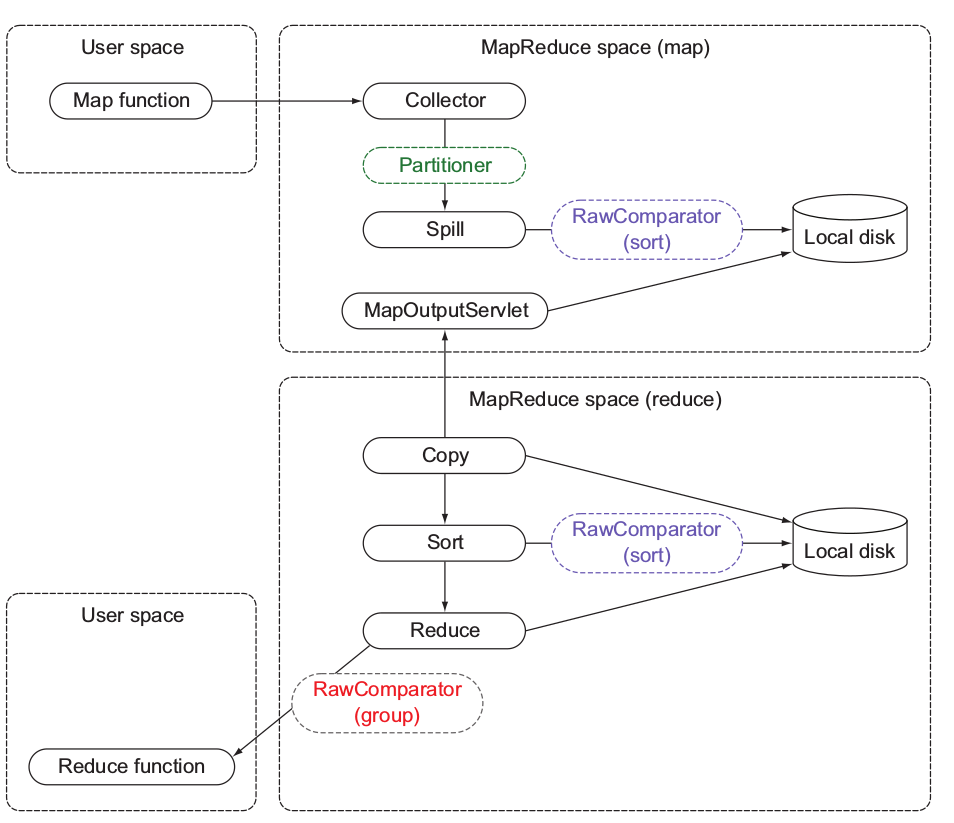
上图展示了影响mapreduce中数据结构和数据流的因素:分区、排序和分组。
partitioner 决定接受记录的reducer
RawComparator(sort) 决定如何排序记录
RawComparator(group) 决定如何调用单个reducer函数对排序后的记录进行分组
分区是在map输出收集过程中被调用的,且用于决定哪些reduce端应该接收map输出。RawComparator 用于对各自分区中的map 输出进行排序。最后RawComparator负责通过被排序的记录确定分组边界。
拿个例子说话,来源于 hadoop 权威指南 第4版
计算每年的最高气温。如果全部记录均按照气温降序排序排列,则无需遍历整个数据集就可以得到结果。
1900 35°C
1900 34°C
1900 34°C
...
1901 36°C
1901 35°C
如上,分组排序(如果有这种简单的实现就好了:groupBy(year).sort(temperature))。首先按照 year 进行 partition,可以保证每一个reducer接受一个年份的所有记录。然后,进行分组设置。这地方有些绕,不急,先说说具体如何操作
- 定义包括自然键和自然值的组合键
- 根据组合键对记录进行排序,即同时用自然键和自然值进行排序
针对组合键进行分区和分组时均只考虑自然
还是没懂?看代码会直观清晰许多。
public class MaxTemperatureUsingSecondarySort
extends Configured implements Tool {
static class MaxTemperatureMapper
extends Mapper<LongWritable, Text, IntPair, NullWritable> {
private NcdcRecordParser parser = new NcdcRecordParser();
@Override
protected void map(LongWritable key, Text value,
Context context) throws IOException, InterruptedException {
parser.parse(value);
if (parser.isValidTemperature()) {
/*[*/context.write(new IntPair(parser.getYearInt(),
parser.getAirTemperature()), NullWritable.get());/*]*/
}
}
}
static class MaxTemperatureReducer
extends Reducer<IntPair, NullWritable, IntPair, NullWritable> {
@Override
protected void reduce(IntPair key, Iterable<NullWritable> values,
Context context) throws IOException, InterruptedException {
/*[*/context.write(key, NullWritable.get());/*]*/
}
}
public static class FirstPartitioner
extends Partitioner<IntPair, NullWritable> {
@Override
public int getPartition(IntPair key, NullWritable value, int numPartitions) {
// multiply by 127 to perform some mixing
return Math.abs(key.getFirst() * 127) % numPartitions;
}
}
public static class KeyComparator extends WritableComparator {
protected KeyComparator() {
super(IntPair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
int cmp = IntPair.compare(ip1.getFirst(), ip2.getFirst());
if (cmp != 0) {
return cmp;
}
return -IntPair.compare(ip1.getSecond(), ip2.getSecond()); //reverse
}
}
public static class GroupComparator extends WritableComparator {
protected GroupComparator() {
super(IntPair.class, true);
}
@Override
public int compare(WritableComparable w1, WritableComparable w2) {
IntPair ip1 = (IntPair) w1;
IntPair ip2 = (IntPair) w2;
return IntPair.compare(ip1.getFirst(), ip2.getFirst());
}
}
@Override
public int run(String[] args) throws Exception {
Job job = JobBuilder.parseInputAndOutput(this, getConf(), args);
if (job == null) {
return -1;
}
job.setMapperClass(MaxTemperatureMapper.class);
/*[*/job.setPartitionerClass(FirstPartitioner.class);/*]*/
/*[*/job.setSortComparatorClass(KeyComparator.class);/*]*/
/*[*/job.setGroupingComparatorClass(GroupComparator.class);/*]*/
job.setReducerClass(MaxTemperatureReducer.class);
job.setOutputKeyClass(IntPair.class);
job.setOutputValueClass(NullWritable.class);
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
int exitCode = ToolRunner.run(new MaxTemperatureUsingSecondarySort(), args);
System.exit(exitCode);
}
}IntPair类实现了writable接口,定义了组合键。FirstPartitioner以组合键的首字段(年份)进行分区。为了按照年份(升序)和气温(降序)排列键,这里使用了KeyComparator。类似的分组按照年份进行分组(GroupComparator,只选取键的首字段进行比较)。
public class IntPair implements WritableComparable<IntPair> {
private int first;
private int second;
public IntPair() {
}
public IntPair(int first, int second) {
set(first, second);
}
public void set(int first, int second) {
this.first = first;
this.second = second;
}
public int getFirst() {
return first;
}
public int getSecond() {
return second;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(first);
out.writeInt(second);
}
@Override
public void readFields(DataInput in) throws IOException {
first = in.readInt();
second = in.readInt();
}
@Override
public int hashCode() {
return first * 163 + second;
}
@Override
public boolean equals(Object o) {
if (o instanceof IntPair) {
IntPair ip = (IntPair) o;
return first == ip.first && second == ip.second;
}
return false;
}
@Override
public String toString() {
return first + "\t" + second;
}
@Override
public int compareTo(IntPair ip) {
int cmp = compare(first, ip.first);
if (cmp != 0) {
return cmp;
}
return compare(second, ip.second);
}
/**
* Convenience method for comparing two ints.
*/
public static int compare(int a, int b) {
return (a < b ? -1 : (a == b ? 0 : 1));
}
}join
在mapreduce中,join适用于将多个数据集进行合并的情况。比如:将用户信息与包含用户活动细节的日志文件合并。合并的两种常见类型是 inner join 和 outer join。inner join对所有的L和R关系元组进行比较,如果遇到相等的键,将会产生一个结果。outer join并不需要进行基于连接词的元组匹配,而是在没有遇到合适的匹配存在的情况下,仍会保留一条来自L或者R的记录。
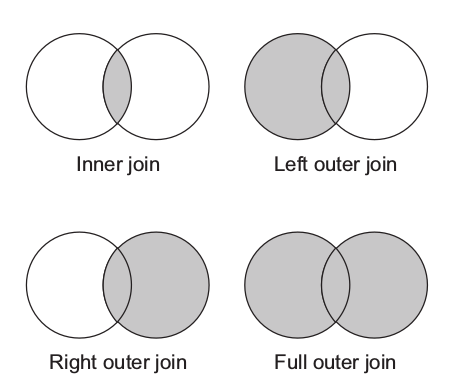
在mapreduce中,join操作分为map 端和 reduce端,这两种形式适合不同的情况
- reparation join — reduce-side join适合于合并两个或更多大型数据集
- replication join— map-side join适合数据集小于缓存容量的情形
- semi-join — 另一种map-side join,适用于数据集 太大而不能导入内存的情形,但是经过一些过滤措施可以将其减小到适用于内存处理的大小。
map-side join
在两个输入数据集之间的 map-side join会在数据到达map函数之前就执行连接操作。如果要达到这个目的,各map的输入数据必须先分区并且以特定方式排序。同一键的所有记录均会放在同一分区之中。
map-side join操作可以连接多个作业的输出,至于这些作业的reducer数量相同、键相同并且输出文件是不可切分的。
CompositeInputFormat类可以执行一个map-side join操作。CompositeInputFormat类的输入源和连接类型可以通过一个链接表达式进行配置。
/**
* An InputFormat capable of performing joins over a set of data sources sorted
* and partitioned the same way.
* @see #setFormat
*
* A user may define new join types by setting the property
* <tt>mapreduce.join.define.<ident></tt> to a classname.
* In the expression <tt>mapreduce.join.expr</tt>, the identifier will be
* assumed to be a ComposableRecordReader.
* <tt>mapreduce.join.keycomparator</tt> can be a classname used to compare
* keys in the join.
* @see JoinRecordReader
* @see MultiFilterRecordReader
*/
@SuppressWarnings("unchecked")
@InterfaceAudience.Public
@InterfaceStability.Stable
public class CompositeInputFormat<K extends WritableComparable>
extends InputFormat<K, TupleWritable> {reduce-side join
reduce-side join并不要求输入数据集符合特定结构,因而reduce端连接比map端更为常用。但是,由于两个数据集均需经过MapReduce的shuffle过程,所以reduce-side join效率要低一些。基本思路是 mapper未各个记录标记源,并且使用连接键作为map输出键,使键相同的记录放在同一reducer中。
(未完)















 498
498











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









