







原理篇
数据管道
Pipeline接口定义了Crunch中管道。MemPipeline,MRPipeline,SparkPipeline实现了Pipeline接口。
public interface Pipeline {
// 将数据读入集合类
<T> PCollection<T> read(Source<T> source);
<K, V> PTable<K, V> read(TableSource<K, V> tableSource);
PCollection<String> readTextFile(String pathName);
//将集合写入某个目标
void write(PCollection<?> collection, Target target);
void write(PCollection<?> collection, Target target, Target.WriteMode writeMode);
<T> void writeTextFile(PCollection<T> collection, String pathName);
//通知管道开始执行
PipelineResult run();
PipelineExecution runAsync();
PipelineResult done();
}管道包含以下定义:一个或者多个输入集合,在输入集合和中间集合上的一组操作,以及将这些集合写入目标的操作等。实际上,所有的管道操作都会延迟到run或者done方法被调用时才执行,这时Crunch将管道转换成一个或多个MapReduce作业,并开始执行。
集合
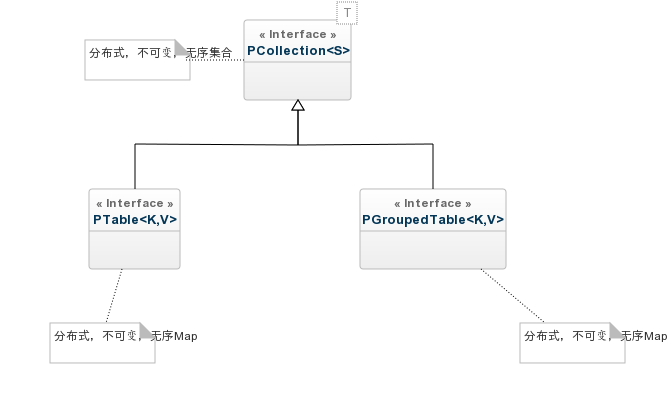
PGroupedTable是一种特殊的集合,源自在PTable上调用groupByKey,该操作在Reduce阶段执行分组。
public interface PCollection<S> {
//将多个集合合成一个集合
PCollection<S> union(PCollection<S> other);
PCollection<S> union(PCollection<S>... collections);
//在该集合上执行操作
<T> PCollection<T> parallelDo(DoFn<S, T> doFn, PType<T> type);
<T> PCollection<T> parallelDo(String name, DoFn<S, T> doFn, PType<T> type);
<T> PCollection<T> parallelDo(String name, DoFn<S, T> doFn, PType<T> type,
//执行特定的操作,产生一个多映射集合类
ParallelDoOptions options);
<K, V> PTable<K, V> parallelDo(DoFn<S, Pair<K, V>> doFn, PTableType<K, V> type);
<K, V> PTable<K, V> parallelDo(String name, DoFn<S, Pair<K, V>> doFn, PTableType<K, V> type);
<K, V> PTable<K, V> parallelDo(String name, DoFn<S, Pair<K, V>> doFn, PTableType<K, V> type,
ParallelDoOptions options);
PCollection<S> write(Target target);
PCollection<S> write(Target target, Target.WriteMode writeMode);
PCollection<S> filter(FilterFn<S> filterFn);
PCollection<S> filter(String name, FilterFn<S> filterFn);
PTable<S, Long> count();
PObject<S> max();
PObject<S> min();
PCollection<S> aggregate(Aggregator<S> aggregator);
}
public interface PGroupedTable<K, V> extends PCollection<Pair<K, Iterable<V>>> {
//将每个组中所有值合并为一个值
PTable<K, V> combineValues(CombineFn<K, V> combineFn);
PTable<K, V> combineValues(CombineFn<K, V> combineFn, CombineFn<K, V> reduceFn);
PTable<K, V> combineValues(Aggregator<V> aggregator);
PTable<K, V> combineValues(Aggregator<V> combineAggregator, Aggregator<V> reduceAggregator);
<U> PTable<K, U> mapValues(MapFn<Iterable<V>, U> mapFn, PType<U> ptype);
<U> PTable<K, U> mapValues(String name, MapFn<Iterable<V>, U> mapFn, PType<U> ptype);
//将组转换为映射
PTable<K, V> ungroup();
PGroupedTableType<K, V> getGroupedTableType();
}数据函数
通过使用集合接口中的parallelDo方法,可以在集合上使用函数。所有的parallelDo都有一个DoFn实现,它用MapReduce方式执行真正的集合操作。

initialize()方法会在调用process之前调用,而process方法MapReduce输入集合中的每个元素都会调用一次。
类型和序列化
parallelDo方法根据返回的结果是Pcollection还是PTable类型,输入参数将是PType或PTableType类型。Crunch通过接口管道使用的数据类型和HDFS读写数据使用的序列化格式进行映射。
Crunch支持原始的Hadoop Writable类和Avro类型的序列化。















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









