







索引
一. 概念
一种有序的数据结构。通过索引指向数据。

二. 索引结构

三. B+ 树索引结构
每个节点存储在一个页的单位上。

为什么B+树的IO次数更少? / InnoDB选择B+Tree索引结构
- 多路查找【B树和B+树的优势】:一个节点允许有多个子节点,树会低矮
- 可以存放更多指针【B+树的优势】:节点由页存储,页的大小固定16K,非叶子节点不存储数据可以存储更多指针。经计算,一个指针占6字节,一个键占8字节的场景下,一个页可以存放1171个指针!
- 数据的连续性【B+树的优势】:叶子节点在磁盘上是连续的。
- 维持平衡较简单【B树和B+树的优势】
- 预读优化【B+树的优势】:由于叶子节点是双向循环链表链接,往往会提起取出目标数据的相邻节点,减少未来发生IO的次数。
四. Hash索引

innoDB引擎在不同情况下会自动将B+树转为Hash
五. B 树索引结构
红黑树就是由2-3-4B树转变而来。
六. 索引的分类


一般选取主键作为聚集索引。如果没有主键,选择unique作为唯一索引。如果都没有,存储引擎自动生成rowID作为聚集索引。
聚集索引:叶子节点上挂具体数据。以主键/UNIQUE/rowID作为Key
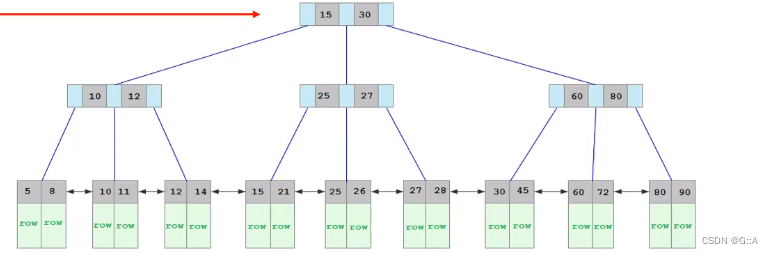
二级索引,叶子节点上挂的是主键,而不是row数据。【通过回表查询查询具体的row数据】
七. 语法
- 创建索引

索引可以关联多个字段,分为组合索引和单例索引。
- 查看索引
SHOW INDEX FROM table_name; - 删除索引
DROP INDEX index_name ON table_name;
八. SQL优化
主要优化查询。故SQL优化第一步就是分析执行频率,对于增删改频率高的语句,可以放轻优化。

对当前数据库进行频率分析。
若当前数据库查询语句执行占比高,则对Select进行优化。
方式:
- 慢查询优化:

-ShowProFiles

- Explain
EXPLAIN 语句并不会真的去执行相关的语句,而是通过查询优化器对语句进行分析,找出最优的查询方案,并显示对应的信息。
id值代表优先级,越大越高。
重点关注type。详情。
九. 最左前缀法则 与 索引条件下推

单列索引可以使用联合索引;而多列索引可能会出现索引失效的情况。
- 缺失失效原则
查询条件与联合索引按索引顺序依次比较【不缺失时,可打乱;缺失时,按索引顺序之后的列索引失效】,如果某一列缺失,那么查询条件第一次不匹配的列及之后的列将不参与索引的条件比较注意是不参与索引条件比较,不是不走索引。当第一列就缺失时,才会不走索引
- 范围查询失效原则
查询条件中出现范围查询(>或<)注意大于等于和小于等于不会造成这一情况,范围查询 -> 等价于缺失失效。 - 索引进行运算操作(函数运算) —> 等价缺失失效。
- 字符串类型的字段,没有加单引号,-> 等价缺失失效。

- 模糊匹配:尾部模糊匹配,索引不失效;头部模糊匹配,-> 等价缺失失效。
- OR连接条件:OR的两边的索引依据根据以上原则判断。如果OR有任一一边没有索引,则索引都不会生效。

- 自适应索引:如果mysql评估,索引效率低于全表扫描,则索引不生效。主要就是表中大部分数据都可以击中条件的情况。
索引条件下推:
MySQL会尽量将更多的查询条件推送到索引搜索过程中,这样在从索引中检索数据时就可以更早地过滤掉不匹配的记录,从而减少从表中检索的行数。【也就是说,即使非索引条件,也会代入到索引的B+树中进行判断比较,以减少回表次数,即下推到执行引擎去做】这显然是利用了mysql过多的索引失效情况的特性而进行的优化。
十. SQL提示
默认情况下,在某个字段对应多种索引的时候,更倾向于使用联合索引。为更个性化,故有SQL提示
-
use index : 指定使用哪个索引

-
ignore index: 禁用哪个索引
-
force index: 强制用哪个索引
-
useindex: 强制哪个索引
十一. 覆盖索引
将查询的目标列和查询条件设为一个索引。可以有效避免回表。在使用查询语句时,可以多建覆盖索引,并避免select *。
十二. 前缀索引
对于varChar和text等类型数据,往往数据长度特别长。如果针对它们构建索引,将会导致占用空间特别大,甚至放不下去。
create index idx_xxx on xxx(xxxxx(n));
n为将数据截取为前n个来建立索引。通过下列公式来判断:

以给email建立n=5的前缀索引为例,截取后统计该索引的distinct数(去重)与count(*)进行比较,越大越好。最好的情况就是唯一索引。
十三. 设计原则
- 针对数据量大且查询频繁的表建立索引。
- 针对常用作查询条件、oder by、group by的字段建立索引。
- 索引所在列尽量区分度高。
- 长字段建立前缀索引。
- 尽量使用联合索引和覆盖索引,减少回表。
- 控制索引数量(占空间的)。
- 索引字段的数据应该尽量不为 NULL。如果一定有空数据,设计默认值区分。
尽管许多数据库系统对NULL值的存储进行了优化,但在索引结构中,NULL值仍然需要额外的标记来表示它们。这可能会增加存储需求;
执行计划的预测性可能会受到影响。优化器可能会基于统计数据选择不同的执行计划,而NULL值可能会影响这些统计数据;
NULL = NULL在SQL中的结果是未定义的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









