








GitHub代码:https://github.com/tesseract-ocr/tesseract
知乎教程:https://zhuanlan.zhihu.com/p/23487530
我们有时候会进行中文识别功能。比如识别验证码,比如通过关键字符串来定位某些控件。这都需要识别图片上的字符。对于英文字符,现在很多开源库都能够很好的进行识别,效果显著。但是对于中文识别,库非常少,而且准确度特别差。国内有很多工具能够很好识别中文,但都是收费的。而免费的开源库中,Tesseract是性价比最好的(注意3.0以上版本才支持中文识别)。虽然这个库识别率不高,但这个强大的库增加了自我学习的功能,可以训练库的中文识别能力。同时,我们可以通过其他的手段,比如文本要求必须使用印刷体,对图片进行灰度化,二值化,去除干扰区域来大幅提升中文的识别能力。
一。编译Tesseract库
现在Tesseract官网上都可以下载。一种是下载一个安装程序,会安装到你电脑上,可以直接使用命令行来识别图片。但是你看不到源代码。另一个是下载源代码,自己进行编译,这样方便全面的去了解整个库的内容。但是编译Tesseract并不容易,首先这个库依赖了许多其他库,这些都要下载下来,初学者很容易搞混哪个才是真正的Tesseract库。其次,下载这些内容地址不一定在一起,需要去找。官网有好多页面的跳转,跳几次就糊涂了。
最新版的Tesseract库要求最新版的Leptonica,这是个处理和分析图像的C开源库。同时这个库又要求最新版的zlib库,libpng库,libtiff库,libjpeg库,giflib库。Tesseract会提供一个已经编译过的Leptonica库,当然其他的依赖库自然也包含了。这样你就不会自己去设置VS了,因为比较繁琐。在Tesseract官网上,都有一步在C盘放置include和lib这两个文件,其实这里面就是这些依赖库的内容。

电脑上安装Git,安装SVN,安装VS2013
创建一个用来放置Tesseract工程的目录,我是在E盘创建了一个文件夹TesseractProject。在该文件夹上右键点击Git Bash Here,进入命令行。从Github上克隆Tessaeract所依赖的库:
打开VS 2013 Developer Command Prompt(在开始菜单里应该可以找到),切换到之前的代码目录,编译整个工程。
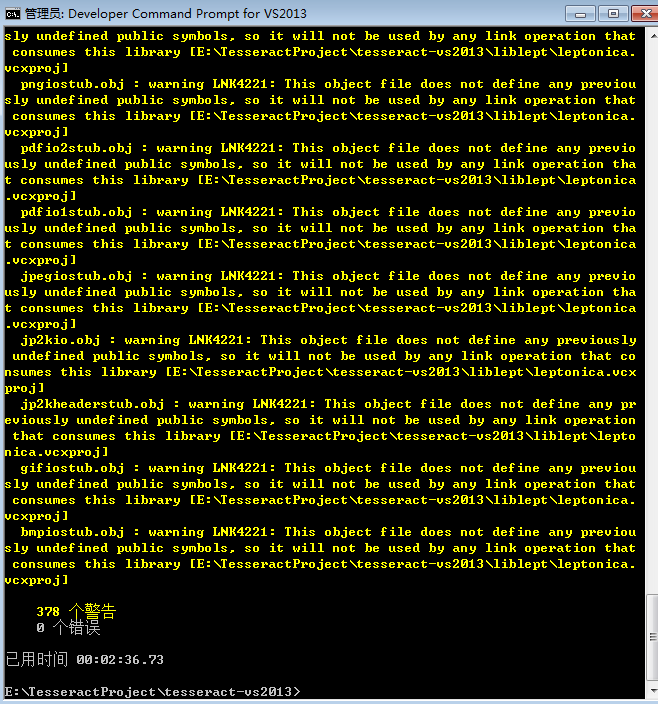
编译成功后便可以关闭命令行了。
现在开始编译Tesseract库,在E:\TesseractProject文件夹上右键点击Git Bash Here。输入命令:
开始克隆源代码,这里可能需要翻qiang下载,注意下。
现在Tesseract的源代码都下载好了。然后来生成VS2013的工程
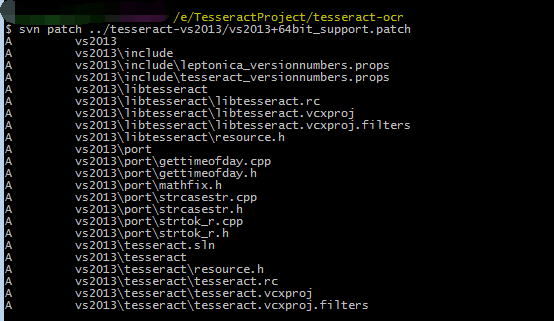
现在将E:\TesseractProject\tesseract-vs2013\release\ 文件夹下的两个文件夹拷贝到E:\TesseractProject\下,这样代码目录就是这样了:

用VS2013打开E:\TesseractProject\tesseract-ocr\vs2013\tesseract.sln工程,重新编译整个解决方案。
可以根据需要配置32位或64位相应的静态或动态的链接版本。编译后可在E:\TesseractProject\tesseract-ocr\vs2013\bin\文件里查看。这里要说明一下,本地编译的时候可能有错误


解决方法参考下面:
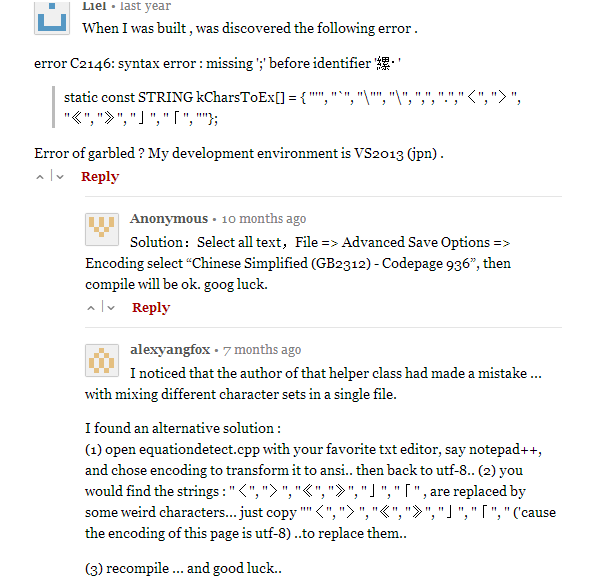
编译后进入相应的文件夹,就可以看到生成的dll和exe文件了,然后拷贝到之前的lib文件中,就可以开始使用了:


二。使用Tesseract库
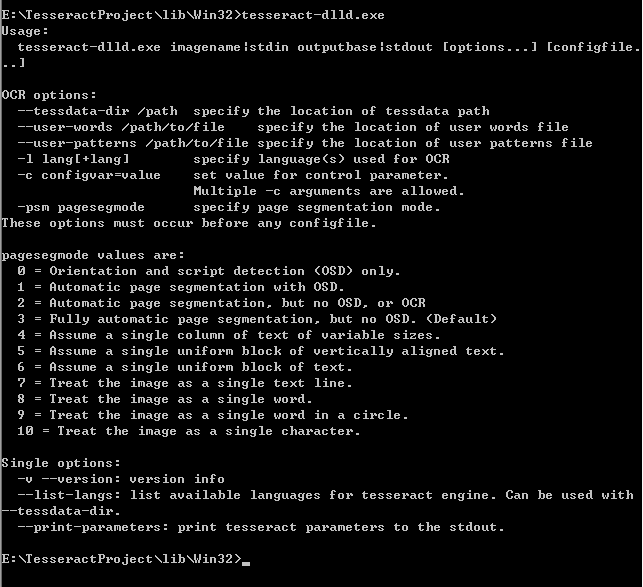
tesseract imagename outputbase [-l lang] [-psm pagesegmode] [configfile...]
tesseract 图片名 输出文件名 -l 字库文件 -psm pagesegmode 配置文件
例如:
tesseract code.jpg result -l chi_sim -psm 7 nobatch
-l chi_sim 表示用简体中文字库
-psm 7 表示告诉tesseract code.jpg图片是一行文本 这个参数可以减少识别错误率. 默认为 3
configfile 参数值为tessdata\configs 和 tessdata\tessconfigs 目录下的文件名
Tesseract对英文识别的非常好,好多英文字体的解析几乎都是0错误。我们这里只对中文进行解析试验,首先要保证字体是印刷体,我们可以在word里面写几个字,然后截图保存,看看效果。

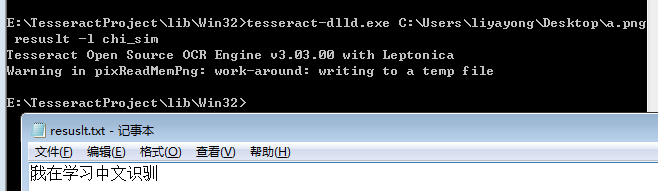
存在一定的误差。这里要注意,识别中文要用到相应的中文语言库,在代码目录tesseract-ocr\tessdata存放着所有用到的语言,但下载后是没有中文的,你需要去手动下载,然后放到这里目录里。同时还要注意,你要把tessdata这个目录写到环境变量TESSDATA_PREFIX里,不然会提示找不到的错误。
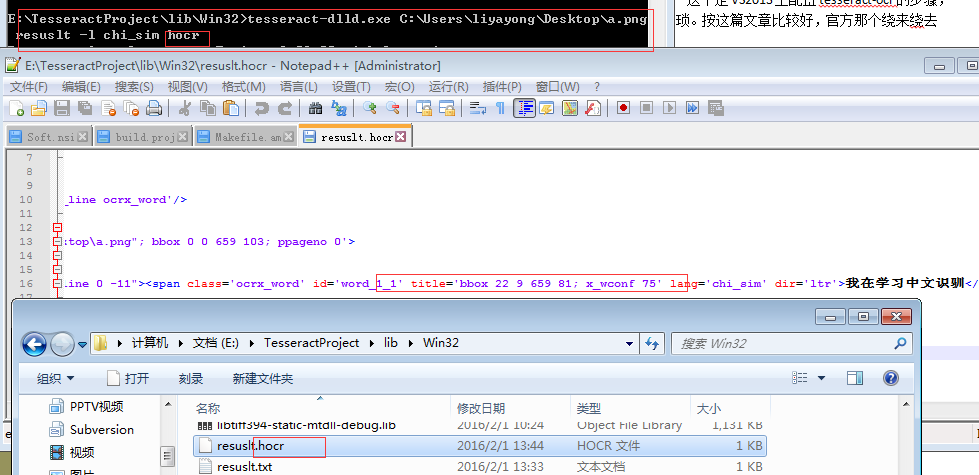
这里有个技巧,默认识别出来的文本是保存在txt里面,但如果我们想获取到文本的具体位置咋办?其实,只要在后面加个 hocr,生成出来的就是xml文件,里面包含的文本的位置信息。
三。提升识别率
从上面的例子看到,即使是黑体放大,字间距拉大,还是会有些错误。那彩色图片上的干扰信息更多,错误率也较大。那如何提高错误率呢?
第一个方法是对Tesseract进行训练,这方法适合于用到的汉字比较固定,比如我们只关注 确定,取消这样的字,那我们就可以将大量的不同写法字体训练进去,这样识别率就会提升了。关于如何操作自行百度。
如果我们不确定识别的字体。那就只能在图片上进行处理。首先必须保证图片上的字体是印刷体,或者其他计算机容易识别的。其次,我们对图片进行灰度化,这样,字体信息就会变得清晰。灰度化后可以再来一次二值化,这样图片上只有两种颜色,字体识别更加准确。然后如果二值化后图片上会出现大片的空白区域,则想办法定位并去除。这样,中文的识别将极大提升。















 3612
3612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









