







 本文详细解析了Storm中Ack机制的工作原理,包括Spout如何生成RootID,Bolt如何处理Tuple并通过Ack值确保数据流的一致性和完整性。此外还介绍了在不同故障场景下如何保证数据不丢失。
本文详细解析了Storm中Ack机制的工作原理,包括Spout如何生成RootID,Bolt如何处理Tuple并通过Ack值确保数据流的一致性和完整性。此外还介绍了在不同故障场景下如何保证数据不丢失。
storm ack机制现在网上一堆资料。根据我的理解,对可靠版的word count进行了流程分析。
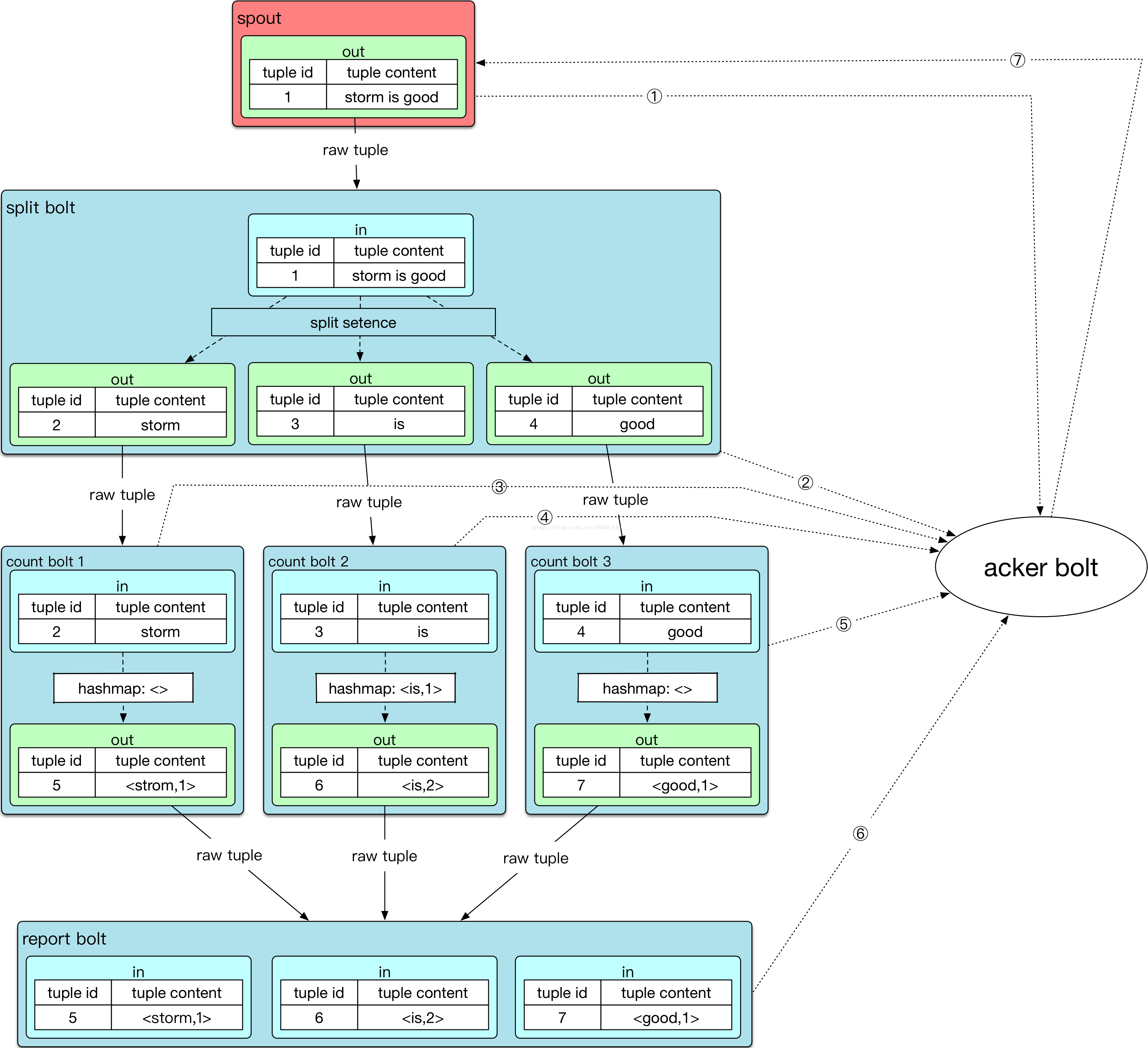
spout每发出一条信息,会根据用户指定的message id生成root id(假设为111),用于标记本次数据流;不论bolt还是spout,ack val = (输入tuple id) ^ (所有输出tuple id的异或结果),只不过ack val的输入tuple不存在。acker bolt会根据root id去更新对应数据流的ack value。详解如下:
- 第①步,spout发出一个tuple给下游,生成root id、tuple id、taskid(标记spout的本次任务,用户acker bolt通过emitDirect方式发送ack结果时使用,假设为222)。此时发送给acker bolt的ack消息为<root id = 111,ack value = 1,task id = 222>,acker bolt中记录的ack信息为<root id = 111,ack value = 1>
- 第②步split bolt接收到句子后,切割出三个单词,发送三个tuple。三个tuple发送完成后,调用ack函数,ack val = (输入tuple id) ^ (所有输出tuple id的异或结果)。则发送给acker bolt的ack消息为<root id = 111,ack value = 1 ^ 2 ^ 3 ^ 4>,acker bolt中记录的ack信息更新为<root id = 111,ack value = 1 ^ (1 ^ 2 ^ 3 ^ 4)>
- 第③④⑤步,实际上没有先后顺序,与第②步类似,每一个bolt分别输出的ack消息分别是<root id = 111,ack value = 2 ^ 5>、<root id = 111,ack value = 3 ^ 6>、<root id = 111,ack value = 4 ^ 7>,acker bolt中记录的ack信息更新为为<root id = 111,ack value = 1 ^ (1 ^ 2 ^ 3 ^ 4) ^ (2 ^ 5) ^ (3 ^ 6) ^ (4 ^ 7)>
- 第⑥步,report bolt没有输出,其ack val = (输入tuple id)。则当count bolt的三个tuple都到达并处理完成时,会向acker bolt发送三次消息,三次的ack消息分别为<root id = 111,ack value = 5>、<root id = 111,ack value = 6>、<root id = 111,ack value = 7>,acker bolt中记录的ack信息更新为<root id = 111,ack value = 1 ^ (1 ^ 2 ^ 3 ^ 4) ^ (2 ^ 5) ^ (3 ^ 6) ^ (4 ^ 7) ^ 5 ^ 6 ^ 7> = <root id = 111, ack value = 0>
- 第⑦步,acker bolt检测到ack value为0,ack bolt通过其对应的root id拿到对应的spout task id(222),通过emitDirect方式将ack的消息发送给对应的spout task。从而完成整个消息流的处理。
上述ack机制,可以在以下异常情况保证数据不丢失:
- 由于对应的task挂掉了,一个tuple没有被ack: storm的超时机制在超时之后会把这个tuple标记为失败,从而可以重新处理。
- Acker挂掉了: 这种情况下由这个acker所跟踪的所有spout tuple都会超时,也就会被重新处理。
- Spout挂掉了: 在这种情况下给spout发送消息的消息源负责重新发送这些消息。比如Kestrel和RabbitMQ在一个客户端断开之后会把所有”处理中“的消息放回队列。

















 1272
1272

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









