









目录
1. 图的概念
图是由顶点集合及顶点间的关系组成的一种数据结构:G = (V, E),其中:
- 顶点集合V = {x|x属于某个数据对象集}是有穷非空集合;
- E = {(x,y)|x,y属于V}或者E = {<x, y>|x,y属于V && Path(x, y)}是顶点间关系的有穷集合,也叫做边的集合。
- (x, y)表示x到y的一条双向通路,即(x, y)是无方向的;Path(x, y)表示从x到y的一条单向通路,即Path(x, y)是有方向的。
- 顶点和边:图中结点称为顶点,第i个顶点记作vi。两个顶点vi和vj相关联称作顶点vi和顶点vj之间有一条边,图中的第k条边记作ek,ek = (vi,vj)或<vi,vj>。
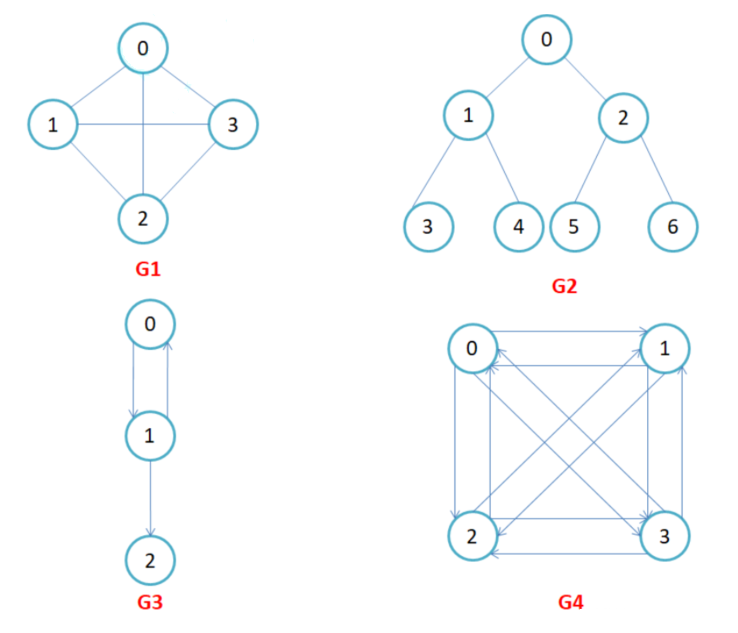
- 有向图和无向图:在有向图中,顶点对<x, y>是有序的,顶点对<x,y>称为顶点x到顶点y的一条边(弧),<x, y>和<y, x>是两条不同的边,比如下图G3和G4为有向图。在无向图中,顶点对(x, y)是无序的,顶点对(x,y)称为顶点x和顶点y相关联的一条边,这条边没有特定方向,(x, y)和(y,x)是同一条边,比如下图G1和G2为无向图。注意:无向边(x, y)等于有向边<x, y>和<y, x>。

- 完全图:在有n个顶点的无向图中,若有n * (n-1)/2条边,即任意两个顶点之间有且仅有一条边,则称此图为无向完全图,比如上图G1;在n个顶点的有向图中,若有n * (n-1)条边,即任意两个顶点之间有且仅有方向相反的边,则称此图为有向完全图,比如下图G4。
- 邻接顶点:在无向图中G中,若(u, v)是E(G)中的一条边,则称u和v互为邻接顶点,并称边(u,v)依附于顶点u和v;在有向图G中,若<u, v>是E(G)中的一条边,则称顶点u邻接到v,顶点v邻接自顶点u,并称边<u, v>与顶点u和顶点v相关联。
- 顶点的度:顶点v的度是指与它相关联的边的条数,记作deg(v)。在有向图中,顶点的度等于该顶点的入度与出度之和,其中顶点v的入度是以v为终点的有向边的条数,记作indev(v);顶点v的出度是以v为起始点的有向边的条数,记作outdev(v)。因此:dev(v) = indev(v) + outdev(v)。注意:对于无向图,顶点的度等于该顶点的入度和出度,即dev(v) = indev(v) = outdev(v)。
- 路径:在图G = (V, E)中,若从顶点vi出发有一组边使其可到达顶点vj,则称顶点vi到顶点vj的顶点序列为从顶点vi到顶点vj的路径。
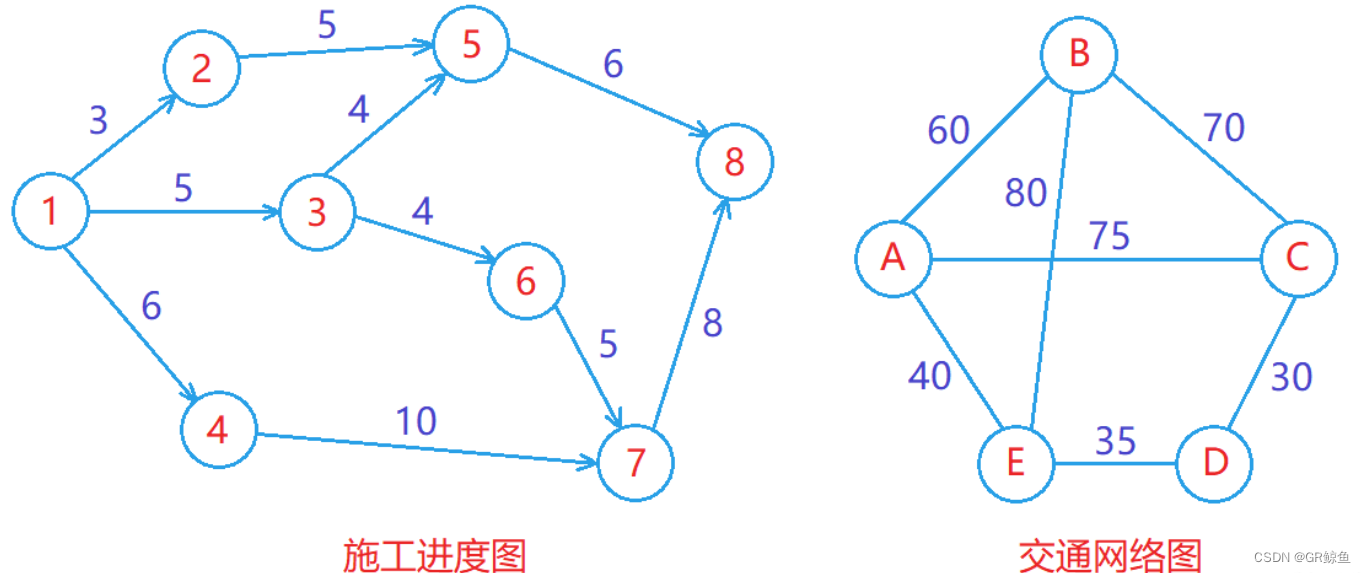
- 路径长度:对于不带权的图,一条路径的路径长度是指该路径上的边的条数;对于带权的图,一条路径的路径长度是指该路径上各个边权值的总和。
带权图示例:
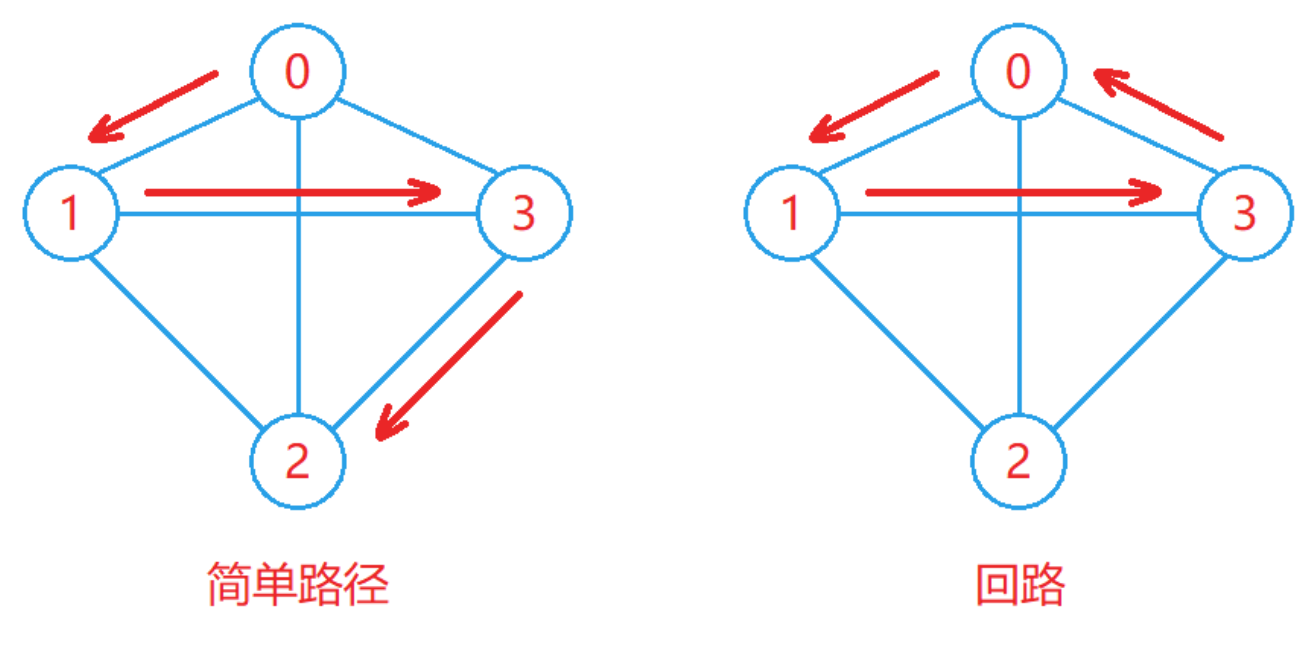
简单路径与回路:
- 若路径上的各个顶点均不相同,则称这样的路径为简单路径。
- 若路径上第一个顶点与最后一个顶点相同,则称这样的路径为回路或环。
如下图:
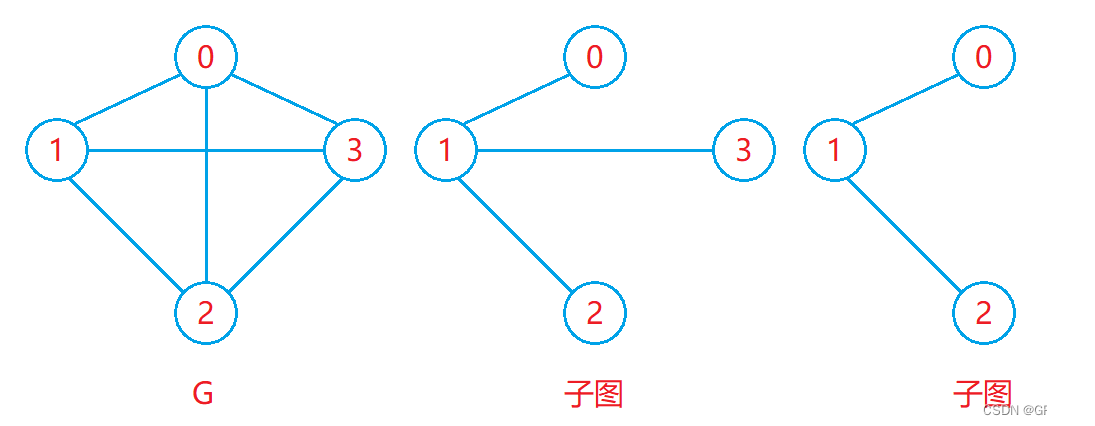
子图:设图G = {V, E}和图G1 = {V1,E1},若V1属于V且E1属于E,则称G1是G的子图。
- 连通图:在无向图中,若从顶点v1到顶点v2有路径,则称顶点v1与顶点v2是连通的。如果图中任 意一 对顶点都是连通的,则称此图为连通图。
- 强连通图:在有向图中,若在每一对顶点vi和vj之间都存在一条从vi到vj的路径,也存在一条从vj 到 vi的路径,则称此图是强连通图。
- 生成树:一个连通图的最小连通子图称作该图的生成树。有n个顶点的连通图的生成树有n个顶点 和n - 1条边。
- 最小生成树:一个图的生成树中,总权值最小的生成树。
图常见的表示场景如下:
- 交通网络:图中的每个顶点表示一个地点,图中的边表示这两个地点之间是否有直接相连的公路,边的权值可以是这两个地点之间的距离、高铁时间等。
- 网络设备拓扑:图中的每个顶点表示网络中的一个设备,图中的边表示这两个设备之间是否可以互传数据,边的权值可以是这两个设备之间传输数据所需的时间、丢包的概率等。
- 社交网络:图中的每个顶点表示一个人,图中的边表示这两个人是否互相认识,边的权值可以是这两个人之间的亲密度、共同好友个数等。
关于有向图和无向图:
- 交通网络对应的图可以是有向图,也可以是无向图,无向图对应就是双向车道,有向图对应就是单向车道。
- 网络设备拓扑对应的图通常是无向图,两个设备之间有边表示这两个设备之间可以互相收发数据。
- 社交网络对应的图可以是有向图,也可以是无向图,无向图通常表示一些强社交关系,比如QQ、微信等(一定互为好友),有向图通常表示一些弱社交关系,比如微博、抖音(不一定互相关注)。
图的其他相关作用:
- 在交通网络中,根据最短路径算法计算两个地点之间的最短路径,根据最小生成树算法得到将各个地点连通起来所需的最小成本。
- 在社交网络中,根据广度优先搜索得到两个人之间的共同好友进行好友推荐,根据入边表和出边表得知有哪些粉丝以及关注了哪些博主。
图与树的联系与区别:
- 树是一种有向无环且连通的图(空树除外),但图并不一定是树。
- 有 n 个结点的树必须有 n − 1条边,而图中边的数量不取决于顶点的数量。
- 树通常用于存储数据,并快速查找目标数据,而图通常用于表示某种场景。
2. 图的存储结构
图由顶点和边组成,存储图本质就是将图中的顶点和边存储起来。
本篇博客的各种关于图的算法都用图的领接矩阵实现。
2.1 邻接矩阵(后面算法所用)
邻接矩阵存储图的方式如下:
- 用一个数组存储顶点集合,顶点所在位置的下标作为该顶点的编号(所给顶点可能不是整型)。
- 用一个二维数组 matrix 存储边的集合,其中 matrix[i][j]表示编号为 i 和 j 的两个顶点之间的关系。
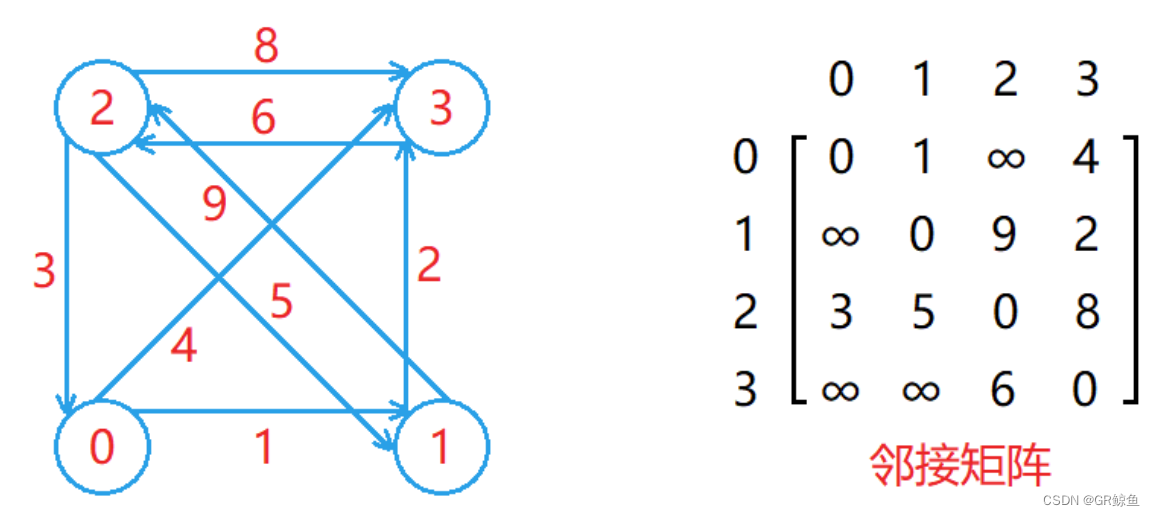
注意事项:
- 对于不带权的图,两个顶点之间要么相连,要么不相连,可以用0和1表示,matrix [ i ] [ j ] 为1表示编号为 i 和 j 的两个顶点相连,为0表示不相连。
- 对于带权的图,连接两个顶点的边会带有一个权值,可以用这个权值来设置对应matrix [ i ] [ j ]的值,如果两个顶点不相连,则使用不会出现的权值进行设置即可(图中为无穷大)。
- 对于无向图来说,顶点 i 和顶点 j 相连,那么顶点 j 就和顶点 i 相连,因此无向图对应的邻接矩阵是一个对称矩阵,即matrix [ i ] [ j ] 的值等于matrix [ i ] [ j ]的值。
- 在邻接矩阵中,第 i 行元素中有效权值的个数就是编号为 i 的顶点的出度,第 i 列元素中有效元素的个数就是编号为 i 的顶点的入度。
邻接矩阵的优点:
- 邻接矩阵适合存储稠密图,因为存储稠密图和稀疏图时所开辟的二维数组大小是相同的,因此图中的边越多,邻接矩阵的优势就越明显。
- 邻接矩阵能够O(1)地判断两个顶点是否相连,并获得相连边的权值。
邻接矩阵的缺点:
- 邻接矩阵不适合查找一个顶点连接出去的所有边,需要遍历矩阵中对应的一行,该过程的时间复杂度是O ( N ) ,其中 N 表示的是顶点的个数。
邻接矩阵的实现:
#pragma once
#include <vector>
#include <iostream>
#include <string>
#include <queue>
#include <map>
#include <set>
#include <functional>
using namespace std;
namespace Matrix // 临接矩阵
{
template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph //Vertex顶点,Weight权值,MAX_W不存在边的标识值 ,Direction有向无向
{
private:
vector<V> _vertexs; // 顶点集合
map<V, size_t> _vIndexMap; // 顶点映射下标
vector<vector<W>> _matrix; // 存储边集合的矩阵(领接矩阵)
public:
struct Edge
{
V _srci;
V _dsti;
W _w;
Edge(const V& srci, const V& dsti, const W& w)
:_srci(srci)
, _dsti(dsti)
, _w(w)
{}
bool operator<(const Edge& eg) const
{
return _w < eg._w;
}
bool operator>(const Edge& eg) const
{
return _w > eg._w;
}
};
typedef Graph<V, W, MAX_W, Direction> Self;
Graph() = default;
Graph(const V* vertexs, int n)
: _vertexs(vertexs, vertexs + n) // 设置顶点集合
, _matrix(n, vector<int>(n, MAX_W)) // 开辟二维数组空间,MAX_W作为不存在边的标识值
{
for (int i = 0; i < n; i++) // 建立顶点与下标的映射关系
{
_vIndexMap[vertexs[i]] = i;
}
}
size_t GetVertexIndex(const V& v) // 获取顶点对应的下标
{
auto ret = _vIndexMap.find(v);
if (ret != _vIndexMap.end()) // 顶点存在
{
return ret->second;
}
else
{
throw invalid_argument("不存在的顶点");
return -1;
}
}
void _AddEdge(int srci, int dsti, const W& weight)
{
_matrix[srci][dsti] = weight; // 设置邻接矩阵中对应的值
if (Direction == false) // 无向图
{
_matrix[dsti][srci] = weight; // 添加从目标顶点到源顶点的边
}
}
void AddEdge(const V& src, const V& dst, const W& w) // 添加边
{
size_t srci = GetVertexIndex(src); // 获取源顶点和目标顶点的下标
size_t dsti = GetVertexIndex(dst);
_AddEdge(srci, dsti, w);
}
void Print()
{
for (size_t i = 0; i < _vertexs.size(); ++i) // 打印顶点和下标映射关系
{
cout << _vertexs[i] << "-" << i << " ";
}
cout << endl << endl;
cout << " ";
for (size_t i = 0; i < _vertexs.size(); ++i)
{
cout << i << " ";
}
cout << endl;
for (size_t i = 0; i < _matrix.size(); ++i) // 打印矩阵
{
cout << i << " ";
for (size_t j = 0; j < _matrix[i].size(); ++j)
{
if (_matrix[i][j] != MAX_W)
cout << _matrix[i][j] << " ";
else
cout << "#" << " ";
}
cout << endl;
}
cout << endl;
for (size_t i = 0; i < _matrix.size(); ++i) // 打印所有的边
{
for (size_t j = 0; j < _matrix[i].size(); ++j)
{
if (i < j && _matrix[i][j] != MAX_W)
{
cout << _vertexs[i] << "-" << _vertexs[j] << ":" << _matrix[i][j] << endl;
}
}
}
}
};
void TestGraph()
{
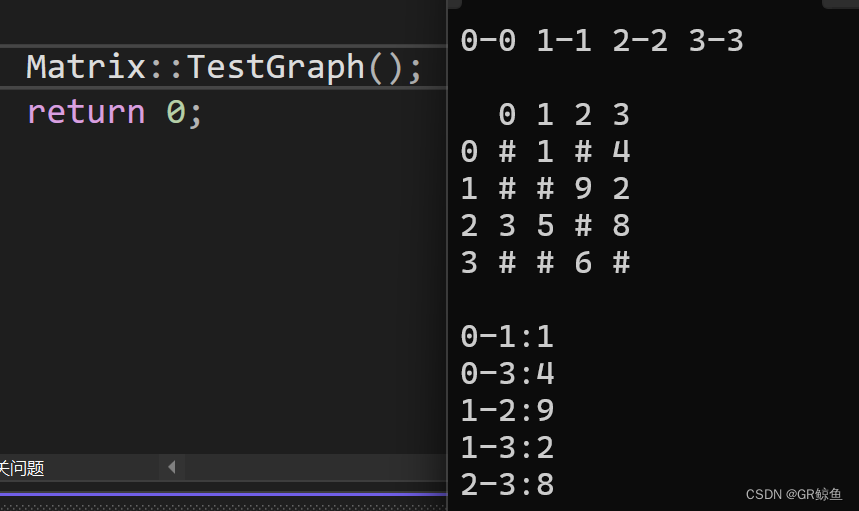
Graph<char, int, INT_MAX, true> g("0123", 4);
g.AddEdge('0', '1', 1);
g.AddEdge('0', '3', 4);
g.AddEdge('1', '3', 2);
g.AddEdge('1', '2', 9);
g.AddEdge('2', '3', 8);
g.AddEdge('2', '1', 5);
g.AddEdge('2', '0', 3);
g.AddEdge('3', '2', 6);
g.Print();
}
}
2.2 邻接表
邻接表(类似哈希桶):使用数组存储顶点的集合,使用链表存储顶点的关系(边)。
邻接表存储图的方式如下:
- 用一个数组存储顶点集合,顶点所在的位置的下标作为该顶点的编号(所给顶点可能不是整型)。
- 用一个出边表存储从各个顶点连接出去的边,出边表中下标为 i 的位置存储的是从编号为 i 的顶点连接出去的边。
- 用一个入边表存储连接到各个顶点的边,入边表中下标为 i 的位置存储的是连接到编号为 i 的顶点的边。
如下图: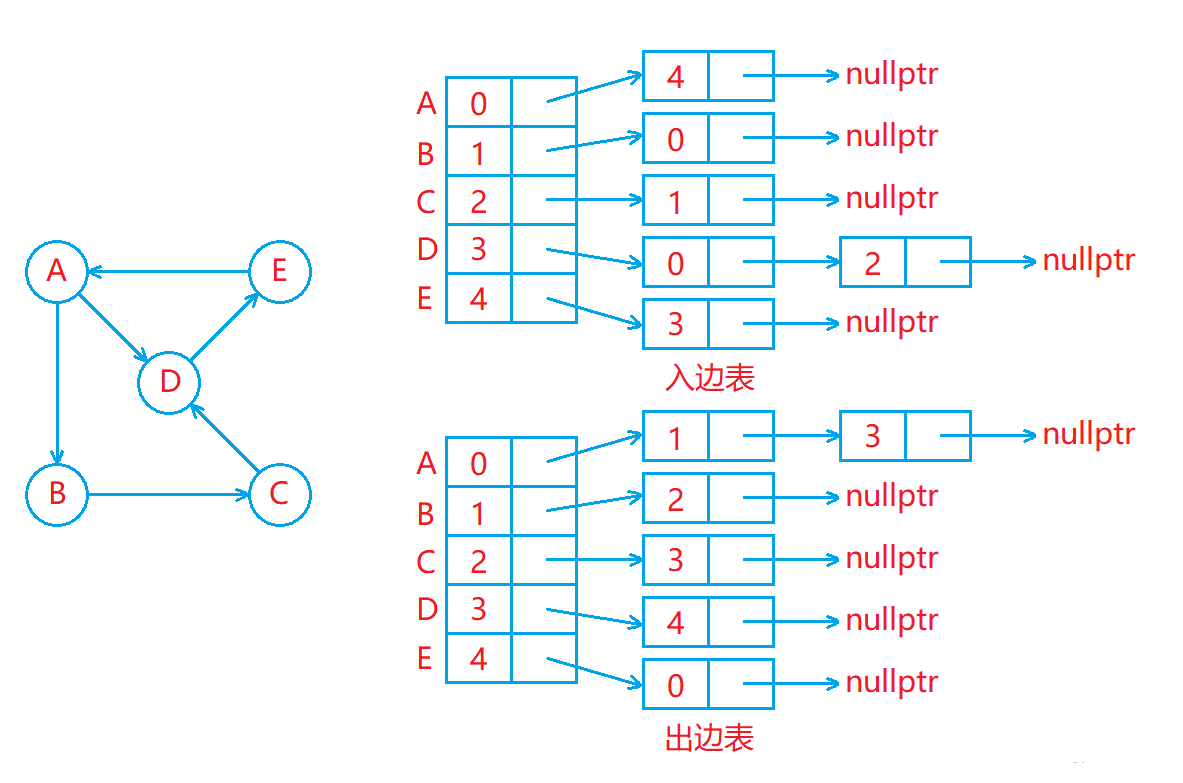
- 出边表和入边表类似于哈希桶,其中每个位置存储的都是一个链表,出边表中下标为 i 的位置的链表中存储的都是从编号为 i 的顶点连接出去的边,入边表中下标为 i 的位置的链表中存储的都是连接到编号为 i 的顶点的边。
- 在邻接表中,出边表中下标为 i 的位置的链表中元素的个数就是编号为 i 的顶点的出度,入边表中下标为 i 的的位置的链表中元素的个数就是编号为 i 的顶点的入度。
- 在实现邻接表时,一般只需要用一个出边表来存储从各个顶点连接出去的边即可,因为大多数情况下都是需要从一个顶点出发找与其相连的其他顶点,所以一般不需要存储入边表。
邻接表的优点:
- 邻接表适合存储稀疏图,因为邻接表存储图时开辟的空间大小取决于边的数量,图中边的数量越少,邻接表存储边时所需的内存空间就越少。
- 邻接表适合查找一个顶点连接出去的所有边,出边表中下标为 i 的位置的链表中存储的就是从顶点 i 连接出去的所有边。
邻接表的缺点:
- 邻接表不适合确定两个顶点是否相连,需要遍历出边表中源顶点对应位置的链表,该过程的时间复杂度是O(E),其中 E 表示从源顶点连接出去的边的数量。
邻接表的实现:
#pragma once
#include <vector>
#include <iostream>
#include <string>
#include <queue>
#include <map>
#include <set>
#include <functional>
using namespace std;
namespace LinkTable // 临接表
{
template<class W>
struct LinkEdge
{
int _srcIndex;
int _dstIndex;
W _w;
LinkEdge<W>* _next;
LinkEdge(const W& w)
: _srcIndex(-1)
, _dstIndex(-1)
, _w(w)
, _next(nullptr)
{}
};
template<class V, class W, bool Direction = false>
class Graph // 构造函数
{
typedef LinkEdge<W> Edge;
private:
map<string, int> _vIndexMap;
vector<V> _vertexs; // 顶点集合
vector<Edge*> _linkTable; // 边的集合的临接表
public:
Graph(const V* vertexs, size_t n) // 构造函数
{
_vertexs.reserve(n); // 设置顶点集合
for (size_t i = 0; i < n; ++i)
{
_vertexs.push_back(vertexs[i]);
_vIndexMap[vertexs[i]] = i; // 建立顶点与下标的映射关系
}
_linkTable.resize(n, nullptr); // 开辟邻接表的空间
}
size_t GetVertexIndex(const V& v) // 获取顶点对应的下标
{
auto ret = _vIndexMap.find(v);
if (ret != _vIndexMap.end()) // 顶点存在
{
return ret->second;
}
else
{
throw invalid_argument("不存在的顶点");
return -1;
}
}
void AddEdge(const V& src, const V& dst, const W& w) // 添加边
{
size_t srcindex = GetVertexIndex(src);
size_t dstindex = GetVertexIndex(dst);
Edge* sd_edge = new Edge(w); // 添加从源顶点到目标顶点的边
sd_edge->_srcIndex = srcindex;
sd_edge->_dstIndex = dstindex;
sd_edge->_next = _linkTable[srcindex];
_linkTable[srcindex] = sd_edge;
if (Direction == false) // 1 0 无向图
{
Edge* ds_edge = new Edge(w); // 添加从目标顶点到源顶点的边
ds_edge->_srcIndex = dstindex;
ds_edge->_dstIndex = srcindex;
ds_edge->_next = _linkTable[dstindex];
_linkTable[dstindex] = ds_edge;
}
}
void print() // 打印顶点集合和邻接表
{
int n = _vertexs.size();
for (int i = 0; i < n; i++) // 打印顶点集合
{
cout << "[" << i << "]->" << _vertexs[i] << " ";
}
cout << endl << endl;
for (int i = 0; i < n; i++) // 打印邻接表
{
Edge* cur = _linkTable[i];
cout << "[" << i << ":" << _vertexs[i] << "]->";
while (cur)
{
cout << "[" << cur->_dstIndex << ":" << _vertexs[cur->_dstIndex] << ":" << cur->_w << "]->";
cur = cur->_next;
}
cout << "nullptr" << endl;
}
}
};
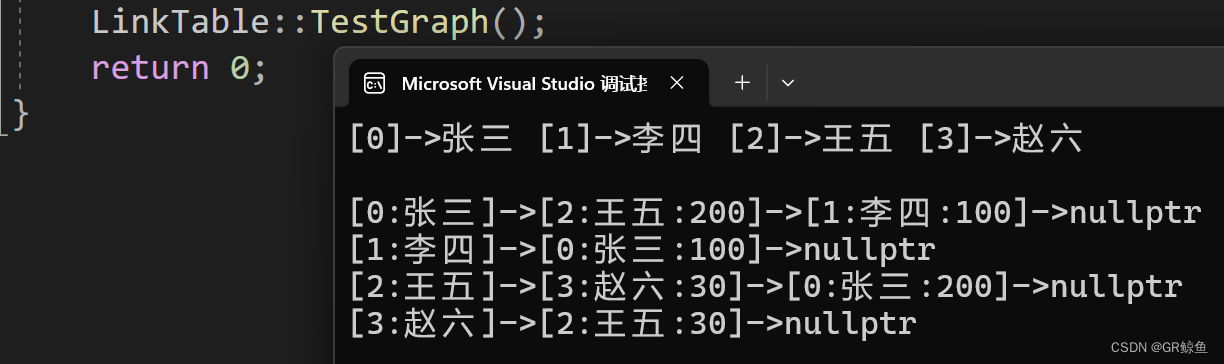
void TestGraph()
{
string a[] = { "张三", "李四", "王五", "赵六" };
Graph<string, int> g1(a, 4);
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
g1.print();
}
}
3. 图的遍历
图的遍历指的是遍历图中的顶点,主要有BFS广度优先遍历和DFS深度优先遍历两种方式。
3.1 BFS广度优先遍历
广度优先遍历又称BFS,其遍历过程类似于二叉树的层序遍历,从起始顶点开始一层一层向外进行遍历。
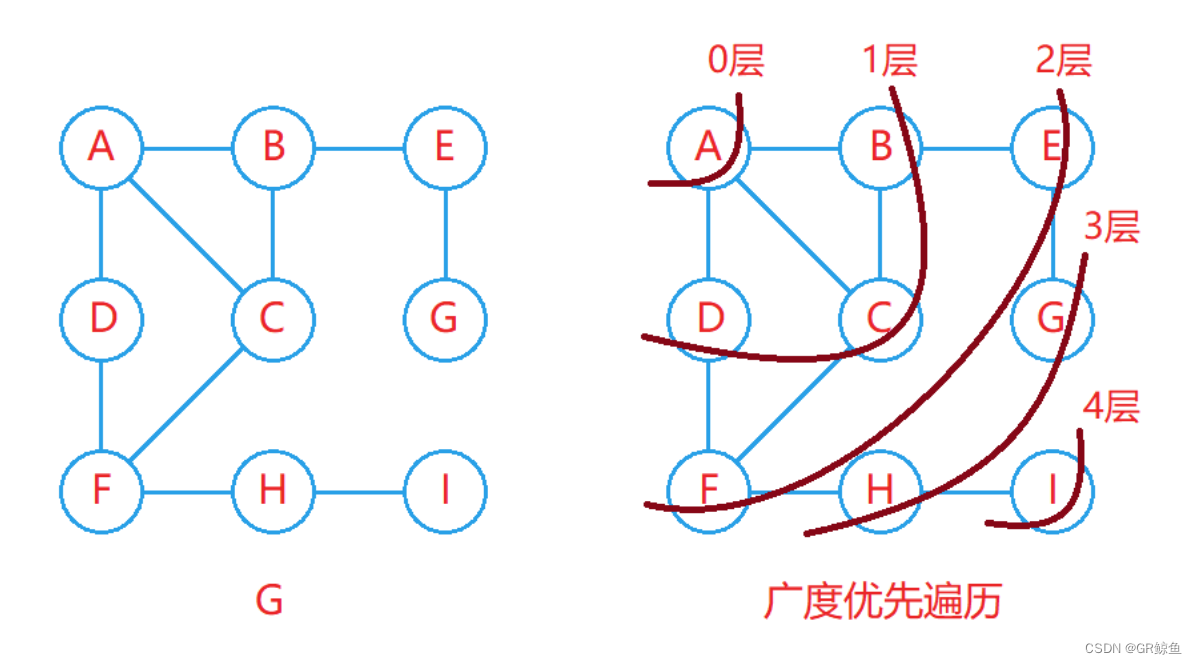
广度优先遍历的实现:
- 广度优先遍历需要借助一个队列和一个标记数组,利用队列先进先出的特点实现一层一层向外遍历,利用标记数组来记录各个顶点是否被访问过。
- 刚开始时将起始顶点入队列,并将起始顶点标记为访问过,然后不断从队列中取出顶点进行访问,并判断该顶点是否有邻接顶点,如果有邻接顶点并且该邻接顶点没有被访问过,则将该邻接顶点入队列,并在入队列后立即将该邻接顶点标记为访问过。
代码如下:
namespace Matrix // 临接矩阵
{
template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph //Vertex顶点,Weight权值,MAX_W不存在边的标识值 ,Direction有向无向
{
private:
vector<V> _vertexs; // 顶点集合
map<V, size_t> _vIndexMap; // 顶点映射下标
vector<vector<W>> _matrix; // 存储边集合的矩阵(领接矩阵)
public:
void BFS(const V& src)
{
size_t srci = GetVertexIndex(src);
queue<int> q; // 队列和标记数组
vector<bool> visited(_vertexs.size(), false);
q.push(srci);
visited[srci] = true;
int levelSize = 1;
size_t n = _vertexs.size();
while (!q.empty())
{
for (int i = 0; i < levelSize; ++i) // 一层一层出
{
int front = q.front();
q.pop();
cout << front << ":" << _vertexs[front] << " ";
for (size_t i = 0; i < n; ++i) // 把front顶点的邻接顶点入队列
{
if (_matrix[front][i] != MAX_W)
{
if (visited[i] == false)
{
q.push(i);
visited[i] = true;
}
}
}
}
cout << endl;
levelSize = q.size();
}
cout << endl;
}
}
void TestGraphBFS()
{
string a[] = { "张三", "李四", "王五", "赵六", "周七" };
Graph<string, int> g1(a, sizeof(a) / sizeof(string));
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
g1.AddEdge("王五", "周七", 30);
g1.BFS("张三");
}
}- 为了防止顶点被重复加入队列导致死循环,因此需要一个标记数组,当一个顶点被访问过后就不应该再将其加入队列了。
- 如果当一个顶点从队列中取出访问时才再将其标记为访问过,也可能会存在顶点被重复加入队列的情况,比如当图中的顶点B出队列时,顶点C作为顶点B的邻接顶点并且还没有被访问过(顶点C还在队列中),此时顶点C就会再次被加入队列,因此最好在一个顶点被入队列时就将其标记为访问过。
- 如果所给图不是一个连通图,那么从一个顶点开始进行广度优先遍历,无法遍历完图中的所有顶点,这时可以遍历标记数组,查看哪些顶点还没有被访问过,对于没有被访问过的顶点,则从该顶点处继续进行广度优先遍历,直到图中所有的顶点都被访问过。
3.2 DFS深度优先遍历
深度优先遍历又称DFS,其遍历过程类似于二叉树的先序遍历,从起始顶点开始不断对顶点进行深入遍历。
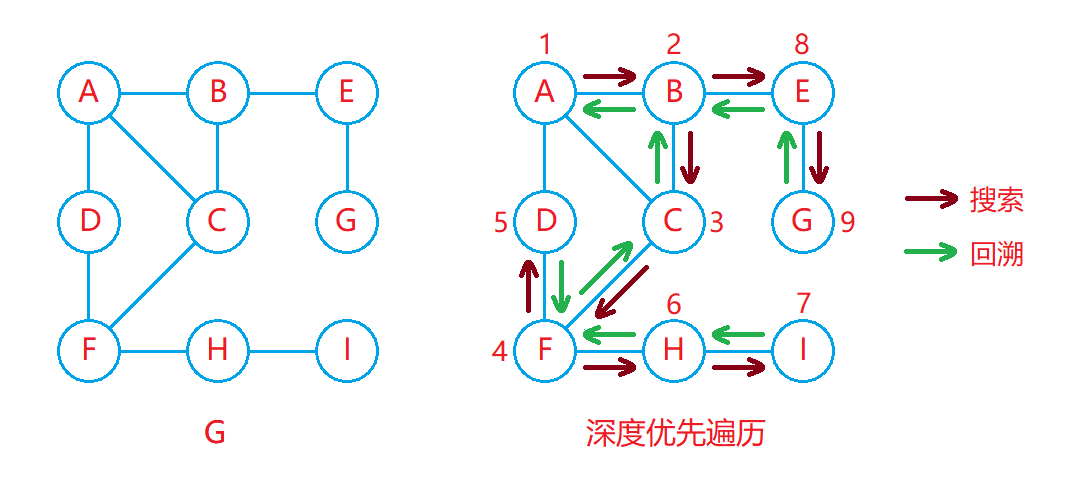
深度优先遍历的实现:
- 深度优先遍历可以通过递归实现,同时也需要借助一个标记数组来记录各个顶点是否被访问过。
- 从起始顶点处开始进行递归遍历,在遍历过程中先对当前顶点进行访问,并将其标记为访问过,然后判断该顶点是否有邻接顶点,如果有邻接顶点并且该邻接顶点没有被访问过,则递归遍历该邻接顶点。
代码如下:
namespace Matrix // 临接矩阵
{
template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph //Vertex顶点,Weight权值,MAX_W不存在边的标识值 ,Direction有向无向
{
private:
vector<V> _vertexs; // 顶点集合
map<V, size_t> _vIndexMap; // 顶点映射下标
vector<vector<W>> _matrix; // 存储边集合的矩阵(领接矩阵)
public:
void _DFS(size_t srci, vector<bool>& visited)
{
cout << srci << ":" << _vertexs[srci] << endl; // 访问
visited[srci] = true;
for (size_t i = 0; i < _vertexs.size(); ++i) // 找一个srci相邻的没有访问过的点,深度遍历
{
if (_matrix[srci][i] != MAX_W && visited[i] == false) // 邻接顶点,且没有被访问过
{
_DFS(i, visited);
}
}
}
void DFS(const V& src)
{
size_t srci = GetVertexIndex(src); // 起始顶点的下标
vector<bool> visited(_vertexs.size(), false);
_DFS(srci, visited);
}
}
void TestGraphDFS()
{
string a[] = { "张三", "李四", "王五", "赵六", "周七" };
Graph<string, int> g1(a, sizeof(a) / sizeof(string));
g1.AddEdge("张三", "李四", 100);
g1.AddEdge("张三", "王五", 200);
g1.AddEdge("王五", "赵六", 30);
g1.AddEdge("王五", "周七", 30);
g1.DFS("张三");
}
}- 如果所给图不是一个连通图,那么从一个顶点开始进行深度优先遍历,无法遍历完图中的所有顶点,这时可以遍历标记数组,查看哪些顶点还没有被访问过,对于没有被访问过的顶点,则从该顶点处继续进行深度优先遍历,直到图中所有的顶点都被访问过。

4. 最小生成树
最小生成树的概念:
- 一个连通图的最小连通子图称为该图的生成树,若连通图由 n 个顶点组成,则其生成树必含 n 个顶点和 n − 1 条边,最小生成树指的是一个图的生成树中,总权值最小的生成树。
- 连通图中的每一棵生成树都是原图的一个极大无环子图,从其中删去任何一条边,生成树就不再连通,在其中引入任何一条新边,都会形成一条回路。
注意事项:
- 对于各个顶点来说,除了第一个顶点之外,其他每个顶点想要连接到图中,至少需要一条边使其连接进来,所以由 n 个顶点的连通图的生成树有 n 个顶点和 n − 1 条边。
- 对于生成树来说,图中的每个顶点已经连通了,如果再引入一条新边,那么必然会使得被新边相连的两个顶点之间存在一条直接路径和一条间接路径,即形成回路。
- 最小生成树是图的生成树中总权值最小的生成树,生成树是图的最小连通子图,而连通图是无向图的概念,有向图对应的是强连通图,所以最小生成树算法的处理对象都是无向图。
构成最小生成树的准则:
- 只能使用图中的边来构造最小生成树。
- 只能使用恰好 n − 1 条边来连接图中的 n 个顶点。
- 选用的 n − 1 条边不能构成回路。
构造最小生成树的算法有Kruskal算法和Prim算法,这两个算法都采用了逐步求解的贪心策略。
Kruskal算法是全局最优的策略,而Prim算法是局部最优的策略。
4.1 Kruskal算法
Kruskal算法(克鲁斯卡尔算法)的基本思想如下:
- 构造一个含 n 个顶点、不含任何边的图作为最小生成树,对原图中的各个边按权值进行排序。
- 每次从原图中选出一条最小权值的边,将其加入到最小生成树中,如果加入这条边会使得最小生成树中构成回路,则重新选择一条边。
- 按照上述规则不断选边,当选出 n − 1 条合法的边时,则说明最小生成树构造完毕,如果无法选出 n − 1 条合法的边,则说明原图不存在最小生成树。
动图演示:(注意到选7,不选6,就是不能构成环)
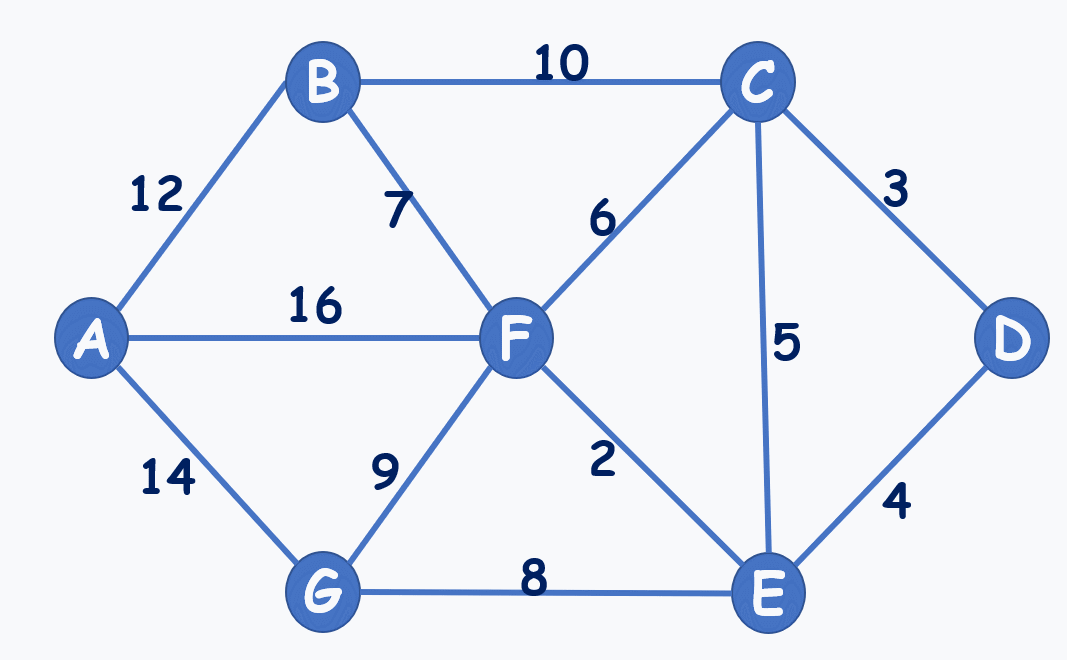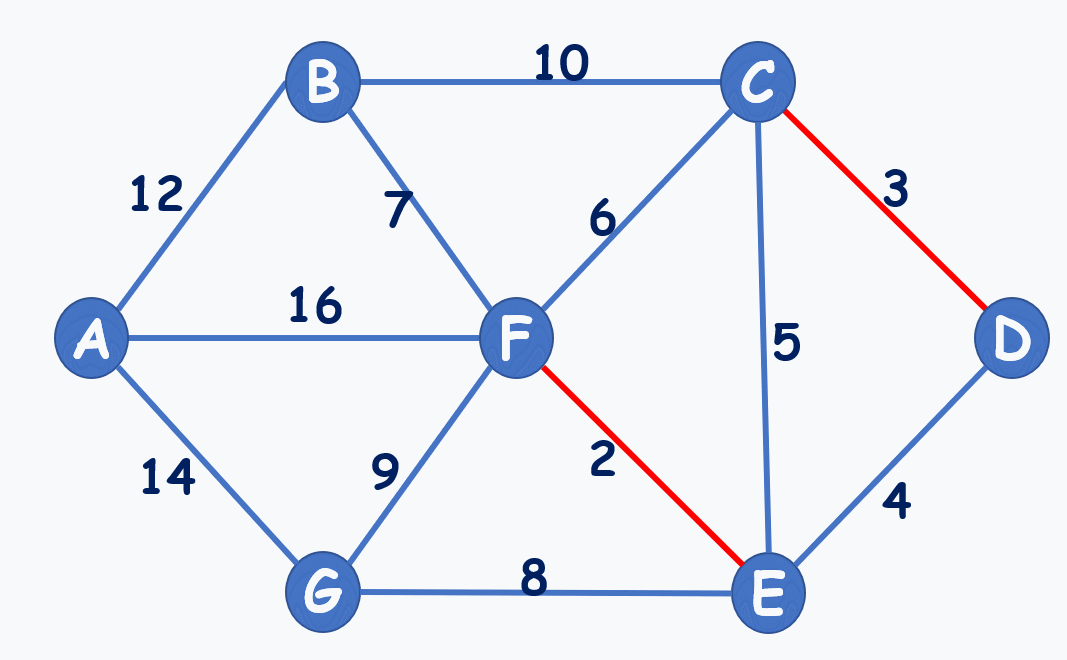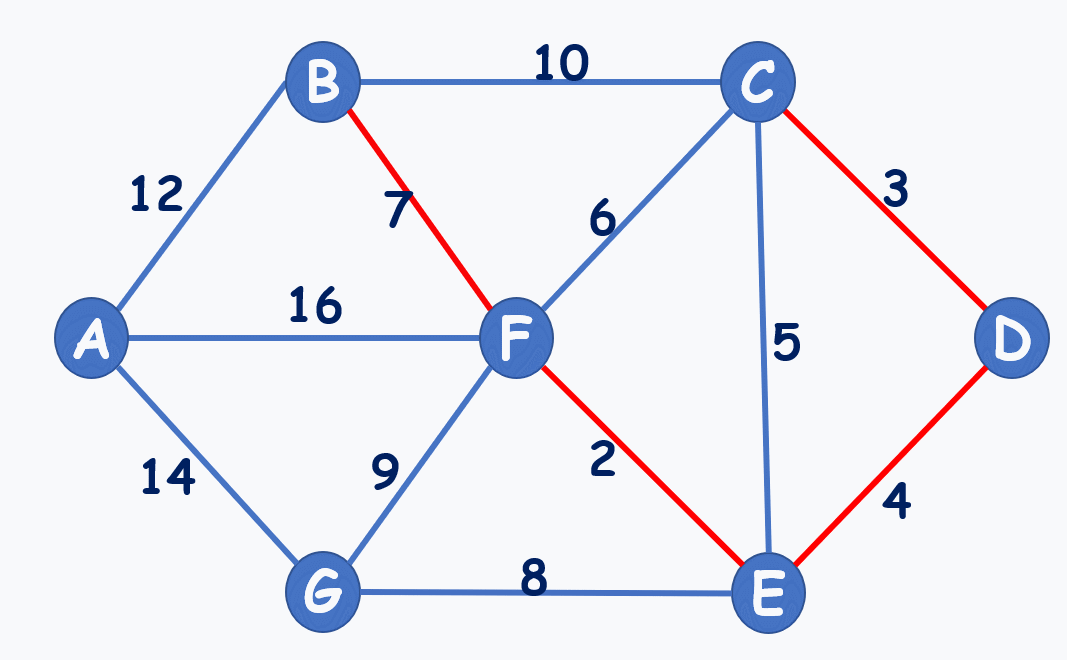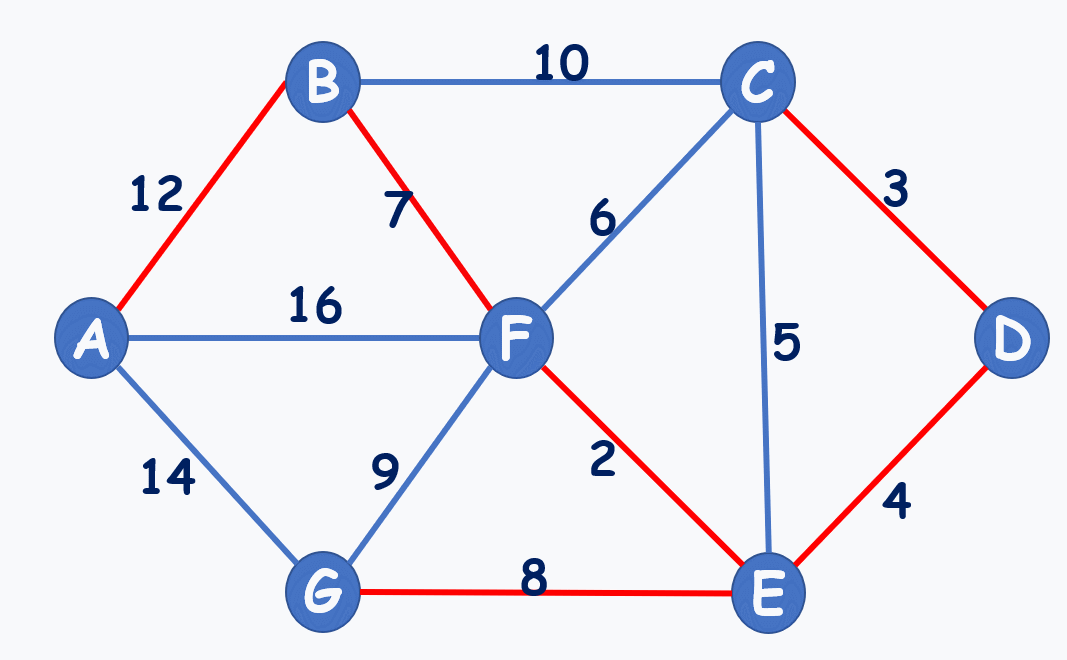
再贴个动图:
以下是《算法导论》里对Kruskal算法的步骤图解:
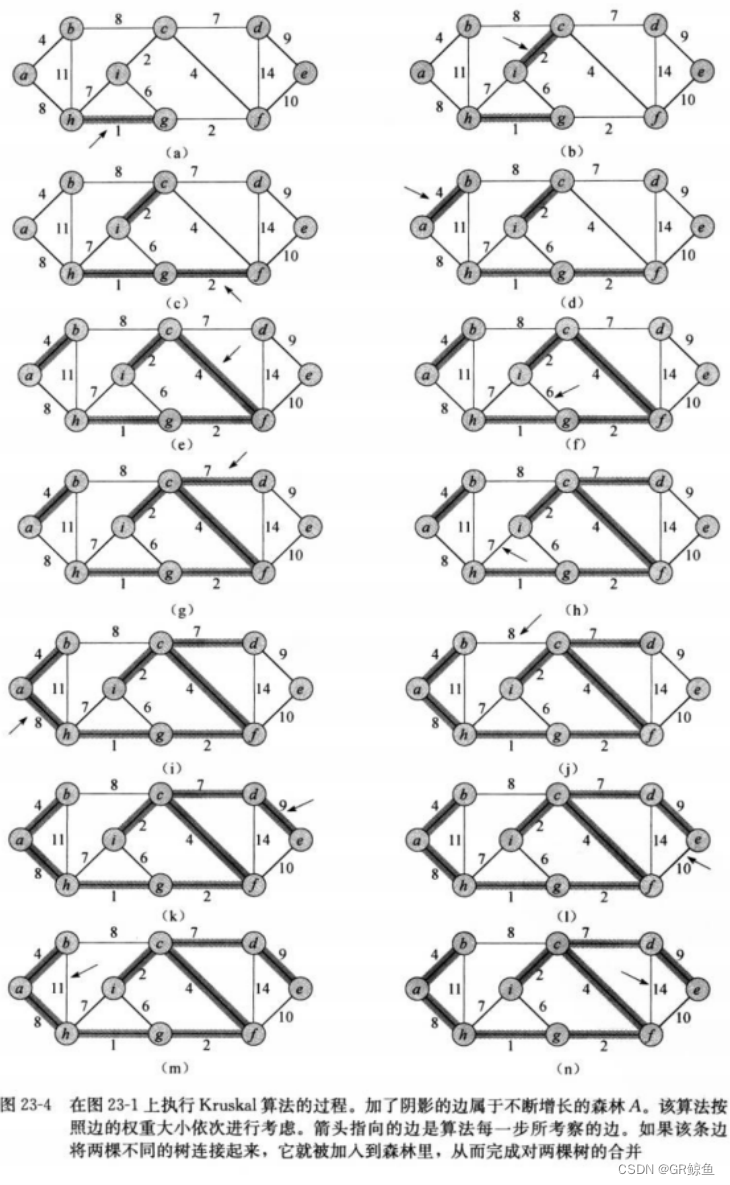
代码实现:
namespace Matrix // 临接矩阵
{
template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph //Vertex顶点,Weight权值,MAX_W不存在边的标识值 ,Direction有向无向
{
private:
vector<V> _vertexs; // 顶点集合,顶点所在位置的下标作为该顶点的编号
map<V, size_t> _vIndexMap; // 顶点映射下标
vector<vector<W>> _matrix; // 存储边集合的矩阵,_matrix[i][j]表示编号为i和j的两个顶点之间的关系
public:
struct Edge
{
V _srci;
V _dsti;
W _w;
Edge(const V& srci, const V& dsti, const W& w)
:_srci(srci)
, _dsti(dsti)
, _w(w)
{}
bool operator<(const Edge& eg) const
{
return _w < eg._w;
}
bool operator>(const Edge& eg) const
{
return _w > eg._w;
}
};
void _AddEdge(int srci, int dsti, const W& weight)
{
_matrix[srci][dsti] = weight; // 设置邻接矩阵中对应的值
if (Direction == false) // 无向图
{
_matrix[dsti][srci] = weight; // 添加从目标顶点到源顶点的边
}
}
void AddEdge(const V& src, const V& dst, const W& w) // 添加边
{
size_t srci = GetVertexIndex(src); // 获取源顶点和目标顶点的下标
size_t dsti = GetVertexIndex(dst);
_AddEdge(srci, dsti, weight);
}
typedef Graph<V, W, MAX_W, Direction> Self;
W Kruskal(Self& minTree) // 克鲁斯卡尔算法
{
int n = _vertexs.size(); // 二维数组空间
minTree._vertexs = _vertexs; // 设置最小生成树的顶点集合
minTree._vIndexMap = _vIndexMap; // 设置最小生成树顶点与下标的映射
minTree._matrix.resize(n, vector<W>(n, MAX_W)); // 开辟最小生成树的二维数组空间
priority_queue<Edge, vector<Edge>, greater<Edge>> pq; // 优先级队列(小堆)
for (size_t i = 0; i < n; ++i) // 将所有边添加到优先级队列
{ // 最小生成树算法的处理对象都是无向图
for (size_t j = 0; j < i; ++j) // 只遍历矩阵的一半,避免重复添加相同的边
{
if (_matrix[i][j] != MAX_W)
{
pq.push(Edge(i, j, _matrix[i][j]));
}
}
}
UnionFindSet ufs(n); // n个顶点的并查集
size_t i = 1; // 已选边的数量,贪心策略,从最小的边开始选
W total = W(); // 总权值
while (!pq.empty() && i < n)
{
Edge min = pq.top(); // 从优先级队列中获取一个权值最小的边
pq.pop();
// 边不在一个集合,说明不会构成环,则添加到最小生成树
if (ufs.InSet(min._srci, min._dsti))
{
// cout << _vertexs[min._srci] << "-" << _vertexs[min._dsti] << ":"
// << _matrix[min._srci][min._dsti] << endl;
minTree._AddEdge(min._srci, min._dsti, min._w); // 在最小生成树中添加边
total += min._w;
ufs.Union(min._srci, min._dsti);
++i;
cout << "选边: " << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
}
else // 边的源顶点和目标顶点在同一个集合,加入这条边会构成环
{
cout << "成环: " << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
}
}
if (i == n)
{
cout << "构建最小生成树成功" << endl;
return total;
}
else
{
cout << "无法构成最小生成树" << endl;
return W();
}
}
}
}- 在获取图的最小生成树时,会以无参的方式定义一个最小生成树对象,然后用原图对象调用上述Kruskal函数,通过输出型参数的方式获取原图的最小生成树,由于我们定义了一个带参的构造函数,使得编译器不再生成默认构造函数,因此需要通过default关键字强制生成Graph类的默认构造函数。
- 一条边包含两个顶点和边的权值,可以定义一个Edge结构体来描述一条边,结构体内包含边的源顶点和目标顶点的下标以及边的权值,在使用优先级队列构造小堆结构时,需要存储的对象之间能够支持 > 运算符操作,因此需要对Edge结构体的 > 运算符进行重载,将其重载为边的权值的比较。
- 当选出的边不会构成回路时,需要将这条边插入到最小生成树对应的图中,此时已经知道了这条边的源顶点和目标顶点对应的下标,可以在Graph类中新增一个_AddEdge子函数,该函数支持通过源顶点和目标顶点的下标向图中插入边,而Graph类中原有的AddEdge函数可以复用这个_AddEdge子函数。
- 最小生成树不一定是唯一的,特别是当原图中存在很多权值相等的边的时候,比如对于动图中的图来说,将最小生成树中的 b c 边换成 a h 边也是一棵最小生成树。
- 上述代码中通过优先级队列构造小堆来依次获取权值最小的边,也可以通过其他排序算法按权值对边进行排序,然后按权值从小到大依次遍历各个边进行选边操作。
- 上述代码中使用的并查集UnionFindSet类,在本专栏上一篇博客中已经讲解过了。
4.2 Prim算法
Prim算法是一种解决连通图最小生成树问题的贪心算法。最小生成树是原图的一个子图,包含了图中所有的顶点,并且是一棵树,使得所有边的权重之和最小。Prim算法通过逐步选择顶点来构建最小生成树。
Prim算法的核心思想是从一个初始顶点开始,每次选择一个与当前最小生成树相邻的顶点,将权重最小的边加入最小生成树,直到所有顶点都被包含在最小生成树中。在整个过程中,保持当前最小生成树的所有顶点都是连通的。Prim算法的每一步都选择当前最小生成树与其余顶点之间的最小权重边,逐步构建最小生成树。这个过程保证了每一步都是局部最优的,最终得到的最小生成树是全局最优的。
Prim算法动图:
- Prim算法中的边选择:
- 在Prim算法的执行过程中,每一步都是从已经选择的顶点集合到未选择的顶点中选择一条最小权重的边。这条边将一个未选择的顶点连接到已经选择的顶点集合中。
- 由于每一步都是通过选择连接已有树和未选择顶点的最小权重边,新加入的边不会形成环。这是因为Prim算法每次都是选择最小权重的边,而非随机选择。
- 无需专门考虑成环问题:
- 由于Prim算法每一步的选择都确保了不会形成环,所以无需在算法实现中专门考虑成环问题。
- 成环问题通常涉及到判断当前考虑的边是否会形成环,需要使用一些额外的数据结构(例如并查集)来判断。Kruskal算法就需要在每一步中判断加入的边是否形成环,因此需要处理成环问题。
- 简化实现:
- 由于Prim算法在每一步的选择中已经考虑了不形成环这一点,实现上更加简单。Prim算法通常可以通过优先队列(最小堆)等数据结构来高效地选择最小权重的边。
- 相对而言,Kruskal算法需要额外的成环判断,通常涉及更复杂的数据结构和算法。
以下是《算法导论》里对Prim算法的介绍:
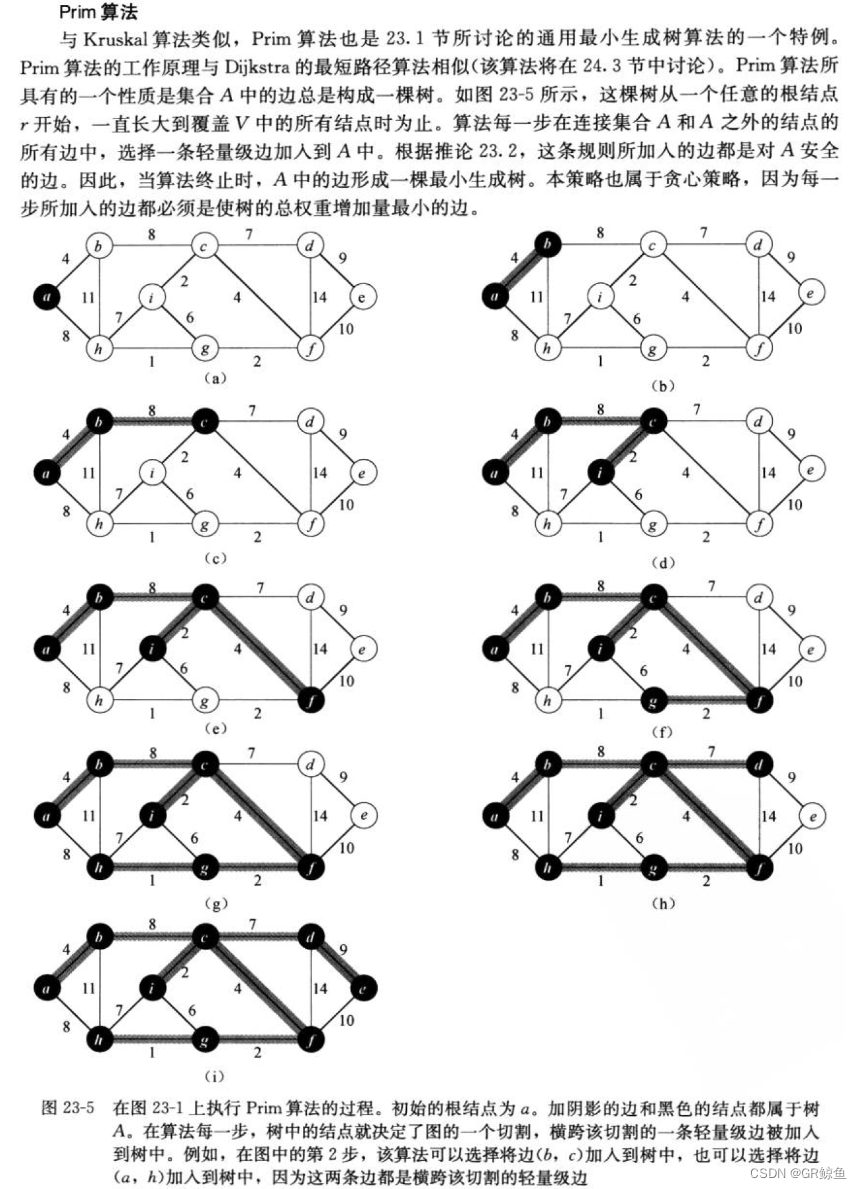
代码:
namespace Matrix // 临接矩阵
{
template<class V, class W, W MAX_W = INT_MAX, bool Direction = false>
class Graph //Vertex顶点,Weight权值,MAX_W不存在边的标识值 ,Direction有向无向
{
private:
vector<V> _vertexs; // 顶点集合,顶点所在位置的下标作为该顶点的编号
map<V, size_t> _vIndexMap; // 顶点映射下标
vector<vector<W>> _matrix; // 存储边集合的矩阵,_matrix[i][j]表示编号为i和j的两个顶点之间的关系
public:
struct Edge
{
V _srci;
V _dsti;
W _w;
Edge(const V& srci, const V& dsti, const W& w)
:_srci(srci)
, _dsti(dsti)
, _w(w)
{}
bool operator<(const Edge& eg) const
{
return _w < eg._w;
}
bool operator>(const Edge& eg) const
{
return _w > eg._w;
}
};
void _AddEdge(int srci, int dsti, const W& weight)
{
_matrix[srci][dsti] = weight; // 设置邻接矩阵中对应的值
if (Direction == false) // 无向图
{
_matrix[dsti][srci] = weight; // 添加从目标顶点到源顶点的边
}
}
void AddEdge(const V& src, const V& dst, const W& w) // 添加边
{
size_t srci = GetVertexIndex(src); // 获取源顶点和目标顶点的下标
size_t dsti = GetVertexIndex(dst);
_AddEdge(srci, dsti, weight);
}
typedef Graph<V, W, MAX_W, Direction> Self;
W Prim(Self& minTree, const W& src) // 普里姆算法
{
size_t srci = GetVertexIndex(src);
size_t n = _vertexs.size();
minTree._vertexs = _vertexs; // 设置最小生成树的顶点集合
minTree._vIndexMap = _vIndexMap; // 设置最小生成树顶点与下标的映射
minTree._matrix.resize(n, vector<W>(n, MAX_W)); // 开辟最小生成树的二维数组空间
vector<bool> X(n, false); // 已选边
vector<bool> Y(n, true); // 未选边
X[srci] = true;
Y[srci] = false;
// 从X->Y集合中连接的边里面选出最小的边
priority_queue<Edge, vector<Edge>, greater<Edge>> minq;
for (size_t i = 0; i < n; ++i) // 先把srci连接的边添加到队列中
{
if (_matrix[srci][i] != MAX_W)
{
minq.push(Edge(srci, i, _matrix[srci][i]));
}
}
cout << "Prim开始选边" << endl;
size_t size = 0; // 已选边数量
W totalW = W(); // 最小生成树的总权值
while (!minq.empty())
{
Edge min = minq.top();
minq.pop();
if (X[min._dsti]) // 最小边的目标点也在X集合,则构成环
{
//cout << "构成环:";
//cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
}
else
{
minTree._AddEdge(min._srci, min._dsti, min._w);
//cout << _vertexs[min._srci] << "->" << _vertexs[min._dsti] << ":" << min._w << endl;
X[min._dsti] = true;
Y[min._dsti] = false;
++size;
totalW += min._w;
if (size == n - 1)
break;
for (size_t i = 0; i < n; ++i)
{
if (_matrix[min._dsti][i] != MAX_W && Y[i])
{
minq.push(Edge(min._dsti, i, _matrix[min._dsti][i]));
}
}
}
}
if (size == n - 1)
{
cout << "构建最小生成树成功" << endl;
return totalW;
}
else
{
cout << "无法构成最小生成树" << endl;
return W();
}
}
}
void TestGraphMinTree()
{
const char str[] = "abcdefghi";
Graph<char, int> g(str, strlen(str));
g.AddEdge('a', 'b', 4);
g.AddEdge('a', 'h', 8);
//g.AddEdge('a', 'h', 9);
g.AddEdge('b', 'c', 8);
g.AddEdge('b', 'h', 11);
g.AddEdge('c', 'i', 2);
g.AddEdge('c', 'f', 4);
g.AddEdge('c', 'd', 7);
g.AddEdge('d', 'f', 14);
g.AddEdge('d', 'e', 9);
g.AddEdge('e', 'f', 10);
g.AddEdge('f', 'g', 2);
g.AddEdge('g', 'h', 1);
g.AddEdge('g', 'i', 6);
g.AddEdge('h', 'i', 7);
Graph<char, int> kminTree;
cout << "Kruskal:" << g.Kruskal(kminTree) << endl;
kminTree.Print();
cout << endl << endl;
Graph<char, int> pminTree;
cout << "Prim:" << g.Prim(pminTree, 'a') << endl;
pminTree.Print();
cout << endl;
for (size_t i = 0; i < strlen(str); ++i)
{
cout << "Prim:" << g.Prim(pminTree, str[i]) << endl;
}
}
}
本篇完。
下一篇是其它高阶数据结构③_图的最短路径(三种)。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











