









在本章中介绍了另一种排序算法:堆排序(heapsort)。与归排序一样,但不同于插入排序的是,堆排序的时间复杂度式(Onlgn)。而与插入排序相同,但不同于归并排序的是,堆排序同样具有空间原址性(我理解的意思是可以实现就地排序):任何时候都只需要常数个额外的元素空间存储临时数据。因此,堆排序是集合了归并排序和插入排序两种排序算法有点的一种排序算法。
堆的定义如下:堆是一个数组,它可以被看成一个近似的完全二叉树(图6-1)。完全二叉树中所有非终端结点的值均不大于(或不小于)其左右孩子结点的值。因此,若{k1, k2, ..., kn }是堆,则堆顶元素必为序列中n个元素的最小值(或最小值)。
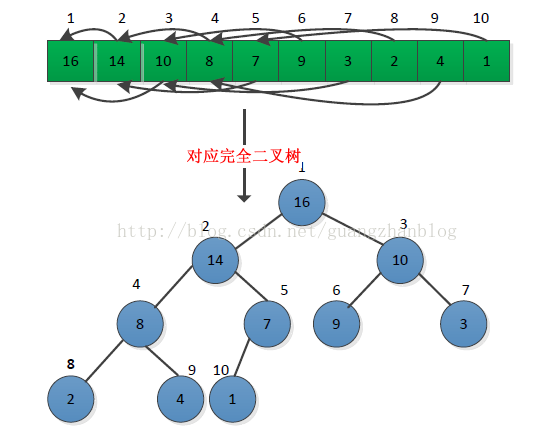
如果把堆看成是一颗树,定义一个堆中的结点的高度为该结点到页结点最长简单路径边上的数目,既然一个包含n个元素的堆可以看做一颗完全二叉树,那么该堆的高度是O(lgn)。因此,堆结构上的一些基本操作的运行时间与树的高度成正比,即时间复杂度为O(lgn)。下面将介绍对的一些基本过程:
- MAX-HEAPIFY过程:其时间复杂度为O(lgn),它是维护最大堆性质的关键。
- BUILD-MAX-HEAP过程: 具有线性时间复杂度,功能是从无序的输入数据数组中构造一个最大堆。
- HEAP-SORT过程:时间复杂度为O(nlgn),功能是对一个数组进行原址排序。
- MAX-HEAP-INSERT、HEAP-EXTRACT-MAX、HEAP-INCREASE-KEY和HEAP-MAXIMUM过程:时间复杂度为O(lgn),功能是利用堆实现一个优先队列。
6.2 维护堆的性质
MAX-HEAPIFY是用于维护最大堆性质的重要过程。它的输入一个数组A和一个下标i。调用MAX-HEAPIFY时,假定根结点LEFT(i)和RIGHT(i)的二叉树都是最大堆,但是A[i]有可能小于其孩子,这样就违背了最大堆的性质。MAX-HEAPIFY通过让A[i]的值在最大堆中“逐级下降”,从而使得下标i为根节点的子树重新遵循最大堆的性质。采用C语言编写的代码如下:
void maxHeapIFY(int *arr, int length, int i){
int l = LEFT(i);
int r = RIGHT(i);
int largest=0;
if (l<=length && arr[l]>a[i] )
largest = l;
else
largest = i;
if(r<=length && arr[r]>arr[largest])
largest = r;
if(largest != i){
int temp = arr[i];
arr[i] = largest;
largest = temp;
maxHeapIFY(arr, length, largest);
}
}
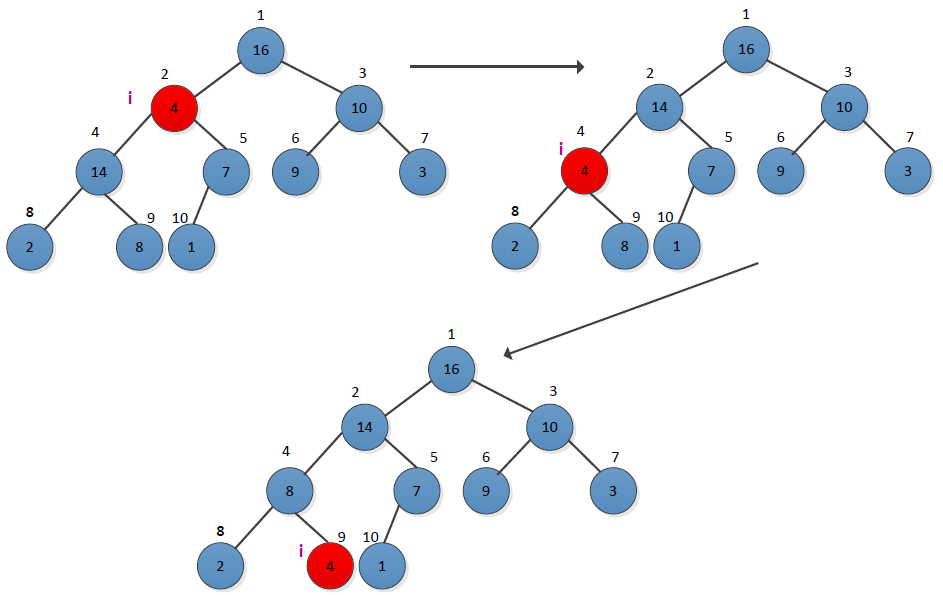
图6-2表示了MAX-HEAPIFY的执行过程。在程序的每一步中,从A[i]、A[LEFT(i)]和A[RIGHT(i)]中选出最大值,并将其下标存储在largest中。从图中可以看出,在节点i=2时,不满足最大堆的要求,需要进行调整,选择节点2的左右孩子中最大一个进行交换,然后检查交换后的节点i=4是否满足最大堆的要求,从图看出不满足,接着进行调整,直到没有交换为止。MAX-HEAPIFY的时间复杂度为O(h)。
6.3 建堆
从一个无需序列建堆的过程就是一个反复“筛选”的过程。若将此序列看成是一个完全二叉树,则最后一个非终端结点是第(n/2)向下取整,由此,从第n/2个元素开始,逐个调用MAX-HEAPIFY(A, i)过程。调整过程如下图所示:
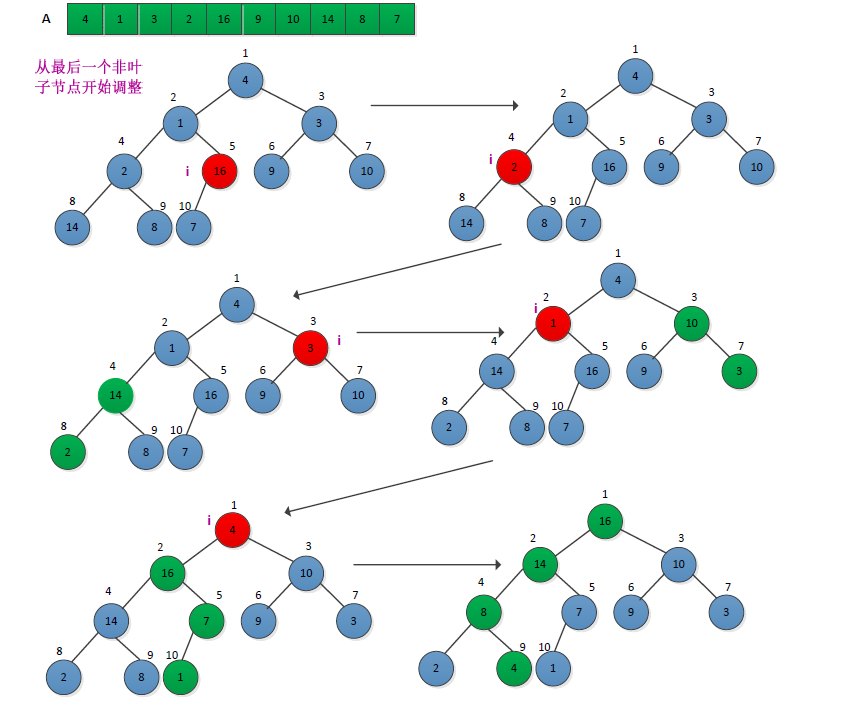
采用c语言实现的建堆的代码如下:
void bulidMaxHeap(int *arr, int length){
for int i = length/2; i>0; --i){
maxHeapIFY(arr, length, i);
}
}6.4 堆排序算法
初始时候,堆排序算法利用BUILD-MAX-HEAP将输入数组A[1.. n]建成最大堆,其中A=A.length。因为数组中的最大元素总在根结点A[1]中,首先交换A[1]与A[n],可以让该元素放到正确的位置。此时从堆中去掉结点n,剩余的结点中,原来的根的孩子结点仍然是最大堆,而新的根结点可能会违背最大堆的性质。为了维护最大堆的性质,我们要做的是调用MAX-HEAPIFY(A, 1),从而在A[1.. n-1]上重新构造一个最大堆。堆排序算法就是不断的重复这一过程,直到堆的大小从n-1降到2。下图给出了在HEAPSORT的第一行建立初始最大堆之后,堆排序操作的一个例子。
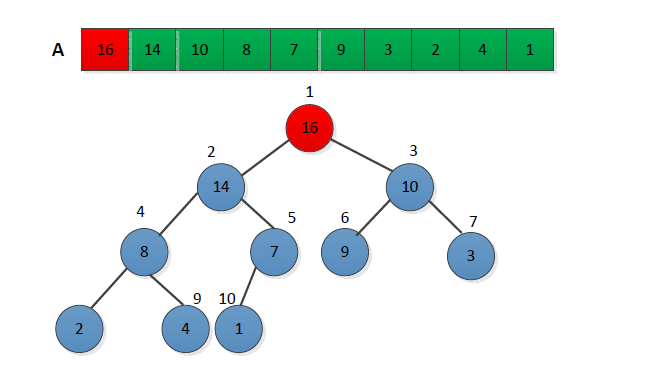
采用C语言实现的代码如下:
void heapSort(int *arr,int length)
{
int i,temp;
//bulid max heap
buildMaxHeap(arr,length);
i=length;
//exchange the first value to the last unitl i=1
while(i>1)
{
temp = arr[i];
arr[i] = arr[1];
arr[1] =temp;
i--;
//adjust max heap,make sure the fisrt value is the largest
buildMaxHeap(arr,i,1);
}
}写本博客的时候参考了Anker的博客,博客中所用到的图片也是取自这里。














 8302
8302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









