







Spark安装(需要先安装Scala)
1:解压spark
tar –zxvf spark-2.2.0-bin-hadoop2.7.tgz
2:配置环境变量
export SPARK_HOME=/usr/tmp/spark-2.2.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
3:使环境变量生效
#source /etc/profile
Spark配置
1:进入spark的conf目录
cd /usr/tmp/spark-2.2.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
cp log4j.properties.template log4j.properties
cp slaves.template slaves
2:编辑spark-env.sh
export SCALA_HOME=/usr/tmp/scala-2.11.11
export JAVA_HOME=/usr/tmp/jdk1.8.0_144
export SPARK_WORKER_MEMORY=1G
export HADOOP_CONF_DIR=/usr/tmp/hadoop-2.7.4/etc/hadoop
3:编辑slaves
master
slave1
slave2
4:将spark拷贝到子节点上然后配置环境变量并使其生效。
scp -r spark-2.2.0-bin-hadoop2.7 root@slave1:/usr/tmp
scp -r spark-2.2.0-bin-hadoop2.7 root@slave2:/usr/tmp
5:进入主节点的sbin目录
运行./start-all.sh
主节点上Master Worker两个进程,子节点上Worker一个进程
输入命令:#spark-shell --master spark://master:7077
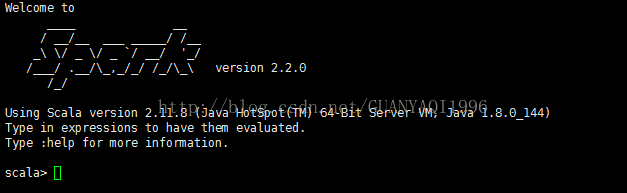
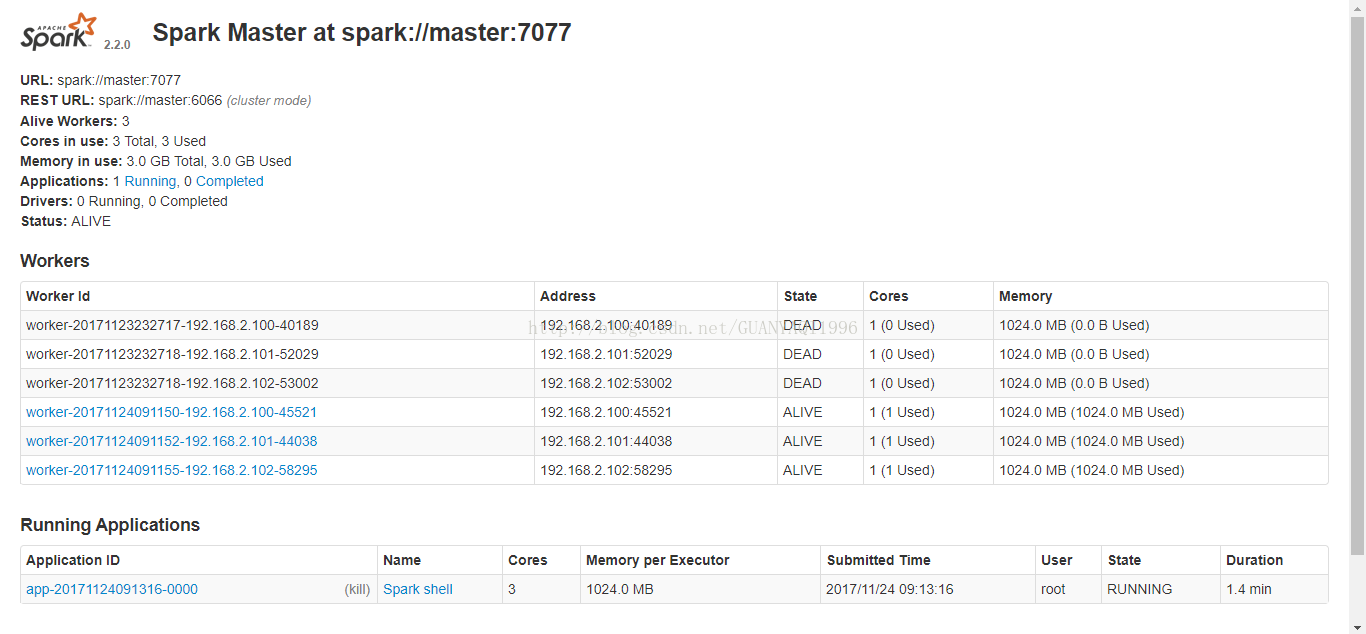
6:浏览器输入:

7:Spark-env.sh里面添加(spark standalone zookeeper HA部署方式)
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER-Dspark.deploy.zookeeper.url=master:2181,slave1:2181,slave2:2181 -Dspark.deploy.zookeeper.dir=/usr/hadoop/spark-2.0.1-bin-hadoop2.6/zookeeper"
















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









