



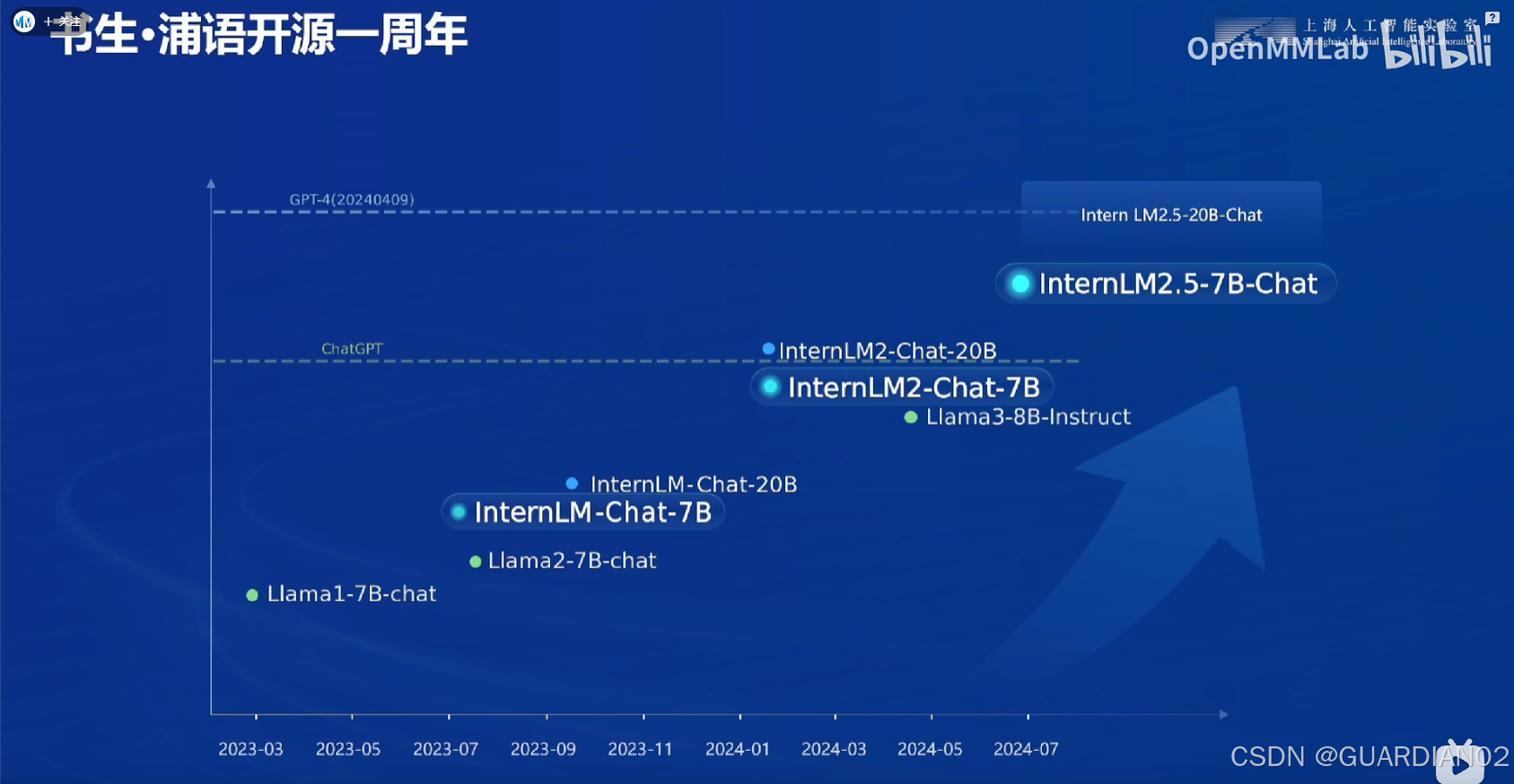
1.书生浦语的发展历程

2.书生大模型全链路开源体系为开发者提供了从数据集准备到模型训练、部署和应用的全套解决方案

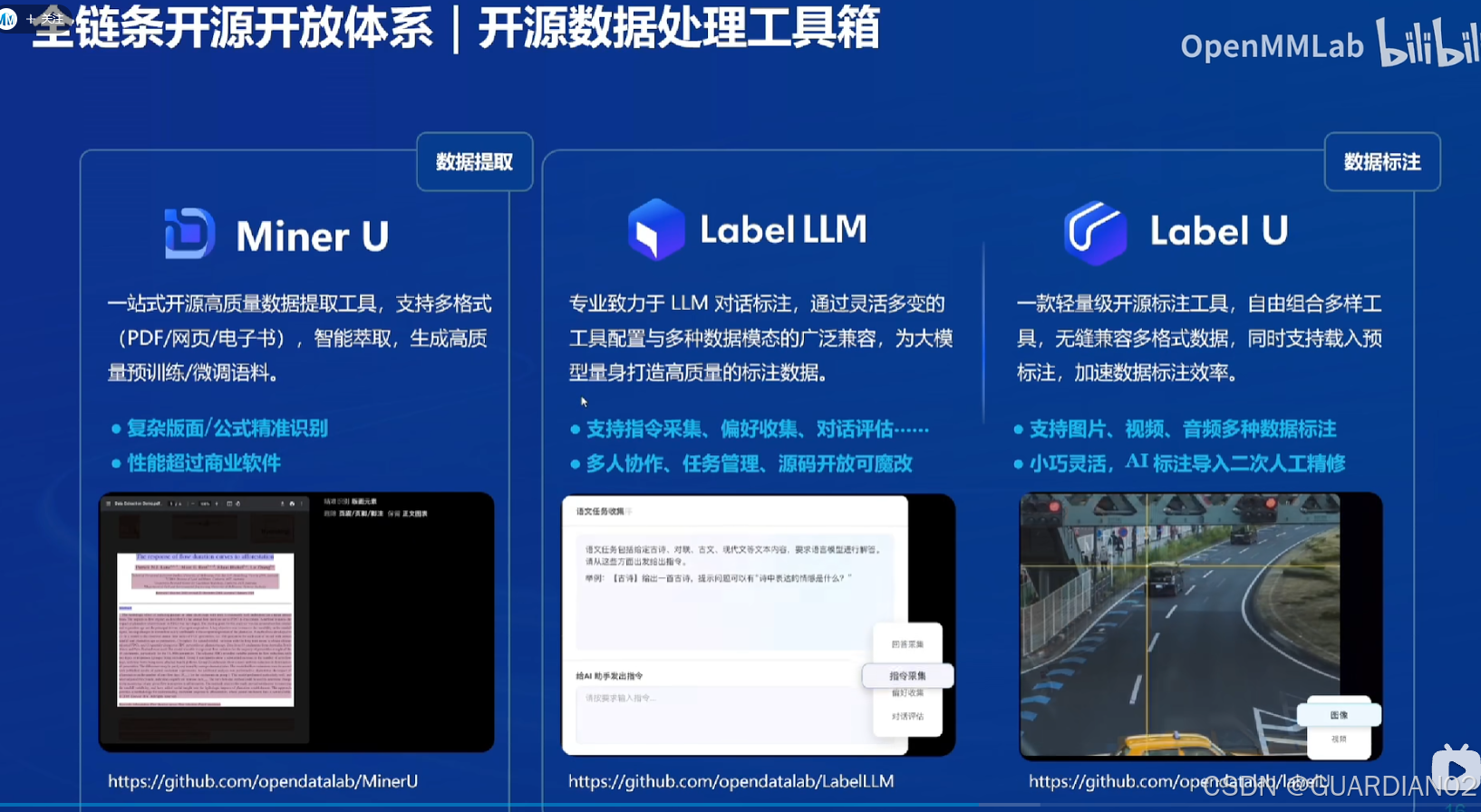
数据
- 数据集:拥有 “书生・万卷” 多模态语料库,包含 1.6 万亿 token 的多语种高质量数据,涵盖文本数据、图像 - 文本数据集、视频数据等多种类型 ,为模型训练提供丰富的语言信息和知识基础.
- 数据处理工具:有 MinerU 等工具,可用于数据准备阶段,支持大规模数据的预处理,包括自动化数据清洗、标注和增强,还能进行文本数据格式转换,确保数据的高质量输入.
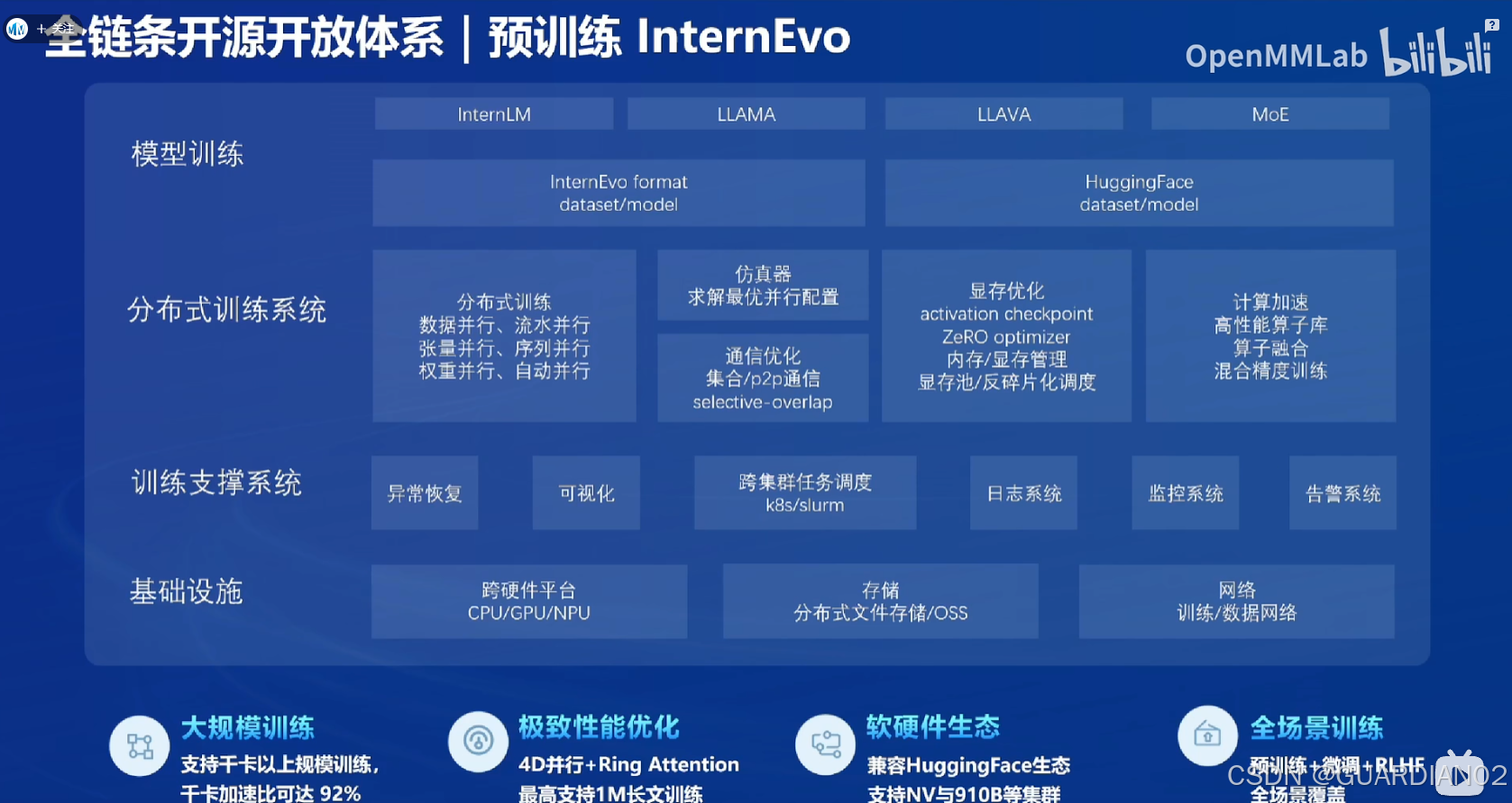
预训练
- InterLM采用并行训练的方式,主要进行了显存优化、分布式训练以及分布式训练之间通信的优化。通过极致优化实现了高效的预训练,降低了训练对于硬件的要求,为模型的通用性奠定基础。
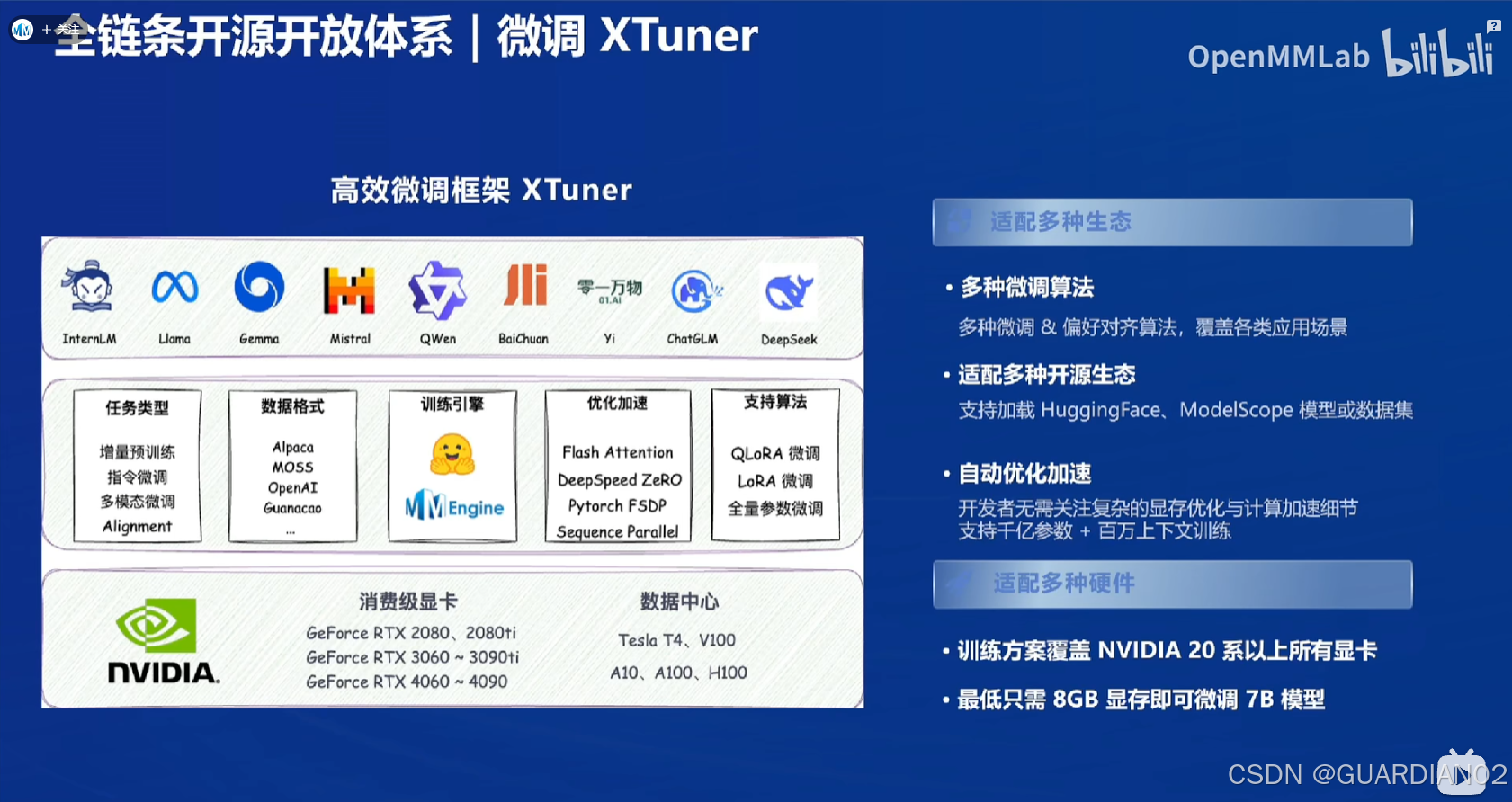
微调
借助 XTuner 微调框架,可根据不同任务需求对大模型进行微调,以提升模型在特定领域或任务上的性能,具有以下特点 :
- 支持多种任务类型:如增量预训练、指令微调、工具类指令微调等。
- 多种微调方式:支持全量参数、LoRA、QLoRA 等低成本微调,覆盖各类 SFT 场景。
- 适配多种模型和生态:支持多种大语言模型的微调,适配 Hugging Face、Model Scope 等开源生态。
- 自动优化加速:支持 Flash Attention、Deep Speed Zero 等技术,无需开发者关注复杂的显存优化与计算加速细节。
- 硬件适配性好:支持 NVIDIA 20 系以上所有显卡,最低只需 8GB 显存即可微调 7b 模型,还支持多种数据格式。
评测
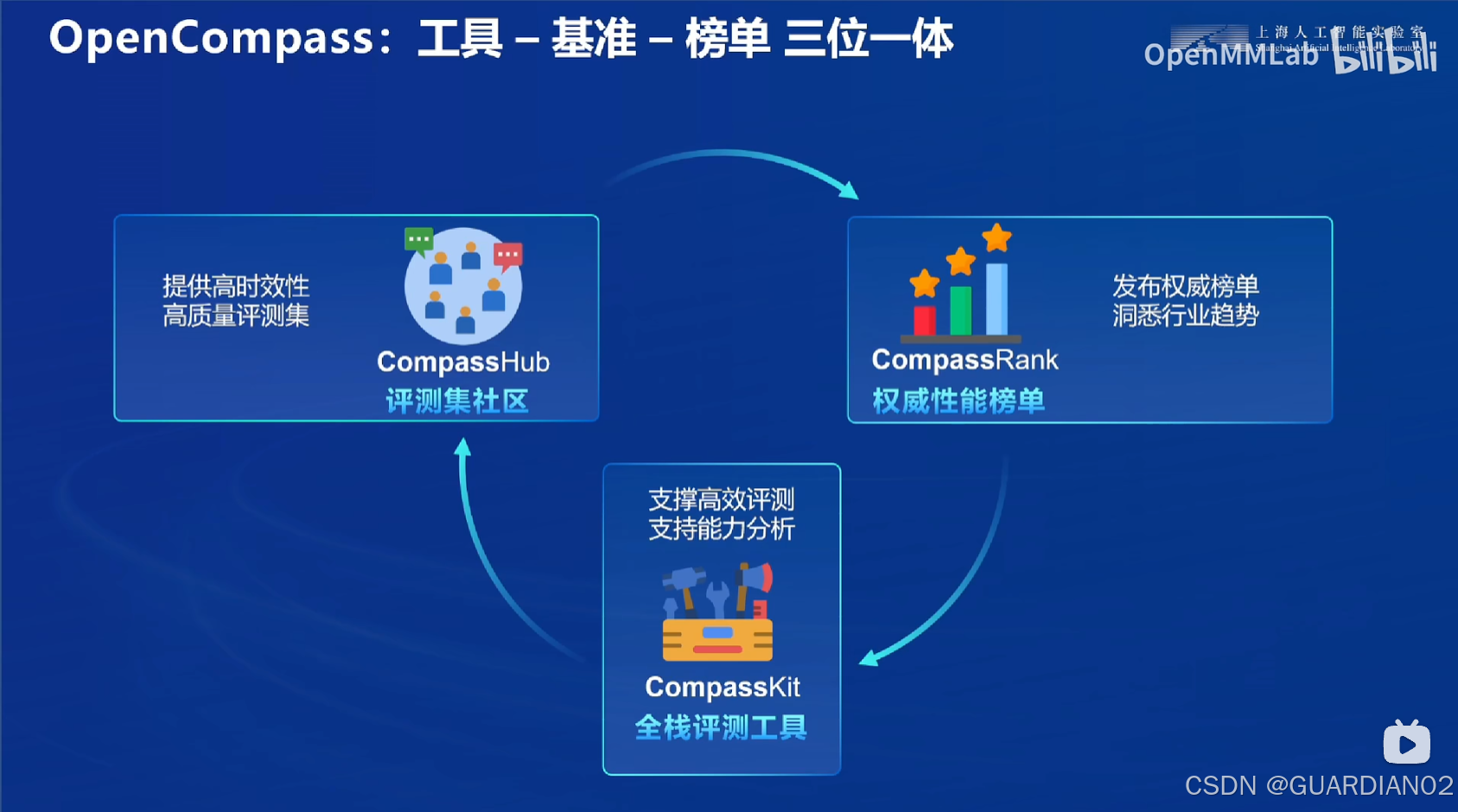
采用 OpenCompass 全方面评测工具,提供了科学严谨的评测体系,从多个维度对模型进行全面评估,确保模型在实际应用中的准确性和可靠性,支持基座模型和对话模型,覆盖了超过 100 个主流模型.
应用
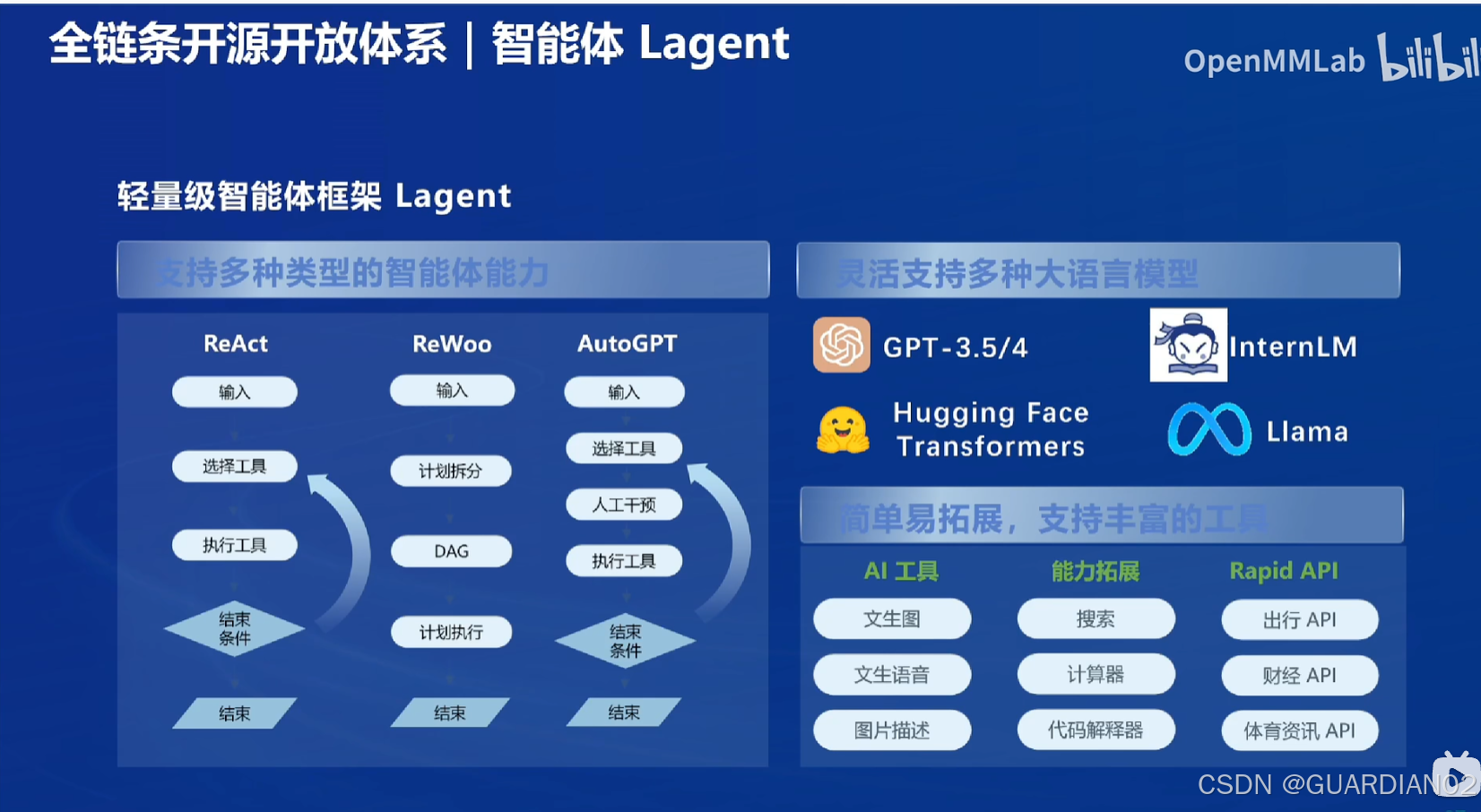
- 智能体框架:开源了 LAgent 框架,支持从语言模型到智能体的升级转换,能够帮助开发者构建智能体,使模型可以与环境进行交互,完成如调用外部 API、与已有数据库交互等复杂任务,从而更好地应用于实际业务场景.
总结:书生大模型全链路开源体系为大模型的发展提供了强大的支持。它不仅为开发者提供了丰富的工具和资源,降低了大模型技术的门槛,还促进了大模型在各个领域的创新应用,为人工智能的发展带来了新的机遇和挑战。

















 328
328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









