







若有收获,请记得分享和转发哦
前言
在高并发系统当中,分库分表是必不可少的技术手段之一,同时也是BAT等大厂面试时,经常考的热门考题。
你知道我们为什么要做分库分表吗?
这个问题要从两条线说起:垂直方向 和 水平方向。
1 垂直方向
垂直方向主要针对的是业务,下面聊聊业务的发展跟分库分表有什么关系。
1.1 单库
在系统初期,业务功能相对来说比较简单,系统模块较少。
为了快速满足迭代需求,减少一些不必要的依赖。更重要的是减少系统的复杂度,保证开发速度,我们通常会使用单库来保存数据。
系统初期的数据库架构如下: 此时,使用的数据库方案是:
此时,使用的数据库方案是:一个数据库包含多张业务表。用户读数据请求和写数据请求,都是操作的同一个数据库。
1.2 分表
系统上线之后,随着业务的发展,不断的添加新功能。导致单表中的字段越来越多,开始变得有点不太好维护了。
一个用户表就包含了几十甚至上百个字段,管理起来有点混乱。
这时候该怎么办呢?
答:分表。
将用户表拆分为:用户基本信息表 和 用户扩展表。
 用户基本信息表中存的是用户最主要的信息,比如:用户名、密码、别名、手机号、邮箱、年龄、性别等核心数据。
用户基本信息表中存的是用户最主要的信息,比如:用户名、密码、别名、手机号、邮箱、年龄、性别等核心数据。
这些信息跟用户息息相关,查询的频次非常高。
而用户扩展表中存的是用户的扩展信息,比如:所属单位、户口所在地、所在城市等等,非核心数据。
这些信息只有在特定的业务场景才需要查询,而绝大数业务场景是不需要的。
所以通过分表把核心数据和非核心数据分开,让表的结构更清晰,职责更单一,更便于维护。
除了按实际业务分表之外,我们还有一个常用的分表原则是:把调用频次高的放在一张表,调用频次低的放在另一张表。
有个非常经典的例子就是:订单表和订单详情表。
1.3 分库







上图中我列的是一主两从,如果master挂了,可以选择从库1或从库2中的一个,升级为新master。假如我们在这里升级从库1为新master,则原来的从库2就变成了新master的的slave了。
调整之后的架构图如下:


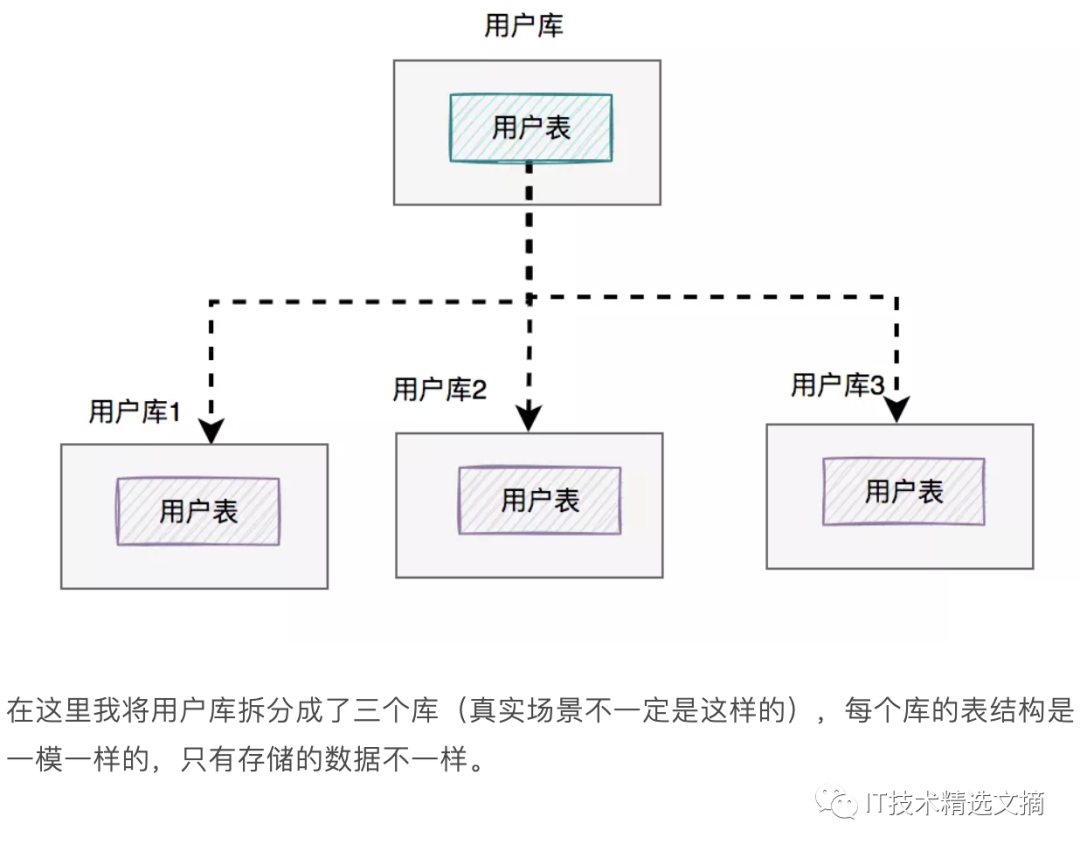




图中将用户库拆分成了三个库,每个库都包含了四张用户表。
如果有用户请求过来的时候,先根据用户id路由到其中一个用户库,然后再定位到某张表。
路由的算法挺多的:
根据id取模,比如:id=7,有4张表,则7%4=3,模为3,路由到用户表3。给id指定一个区间范围,比如:id的值是0-10万,则数据存在用户表0,id的值是10-20万,则数据存在用户表1。一致性hash算法
这篇文章就不过多介绍了,后面会有文章专门介绍这些路由算法的。




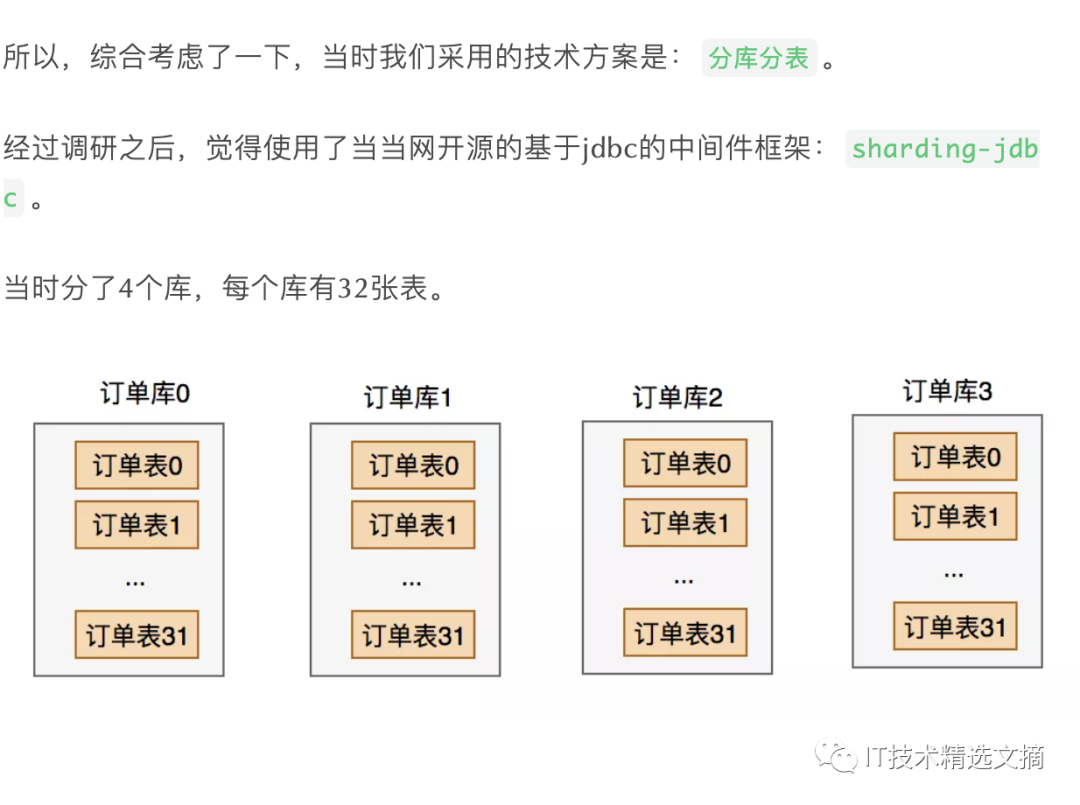
4 总结
上面主要从:垂直和水平,两个方向介绍了我们的系统为什么要分库分表。
说实话垂直方向(即业务方向)更简单。
在水平方向(即数据方向)上,分库和分表的作用,其实是有区别的,不能混为一谈。
分库:是为了解决数据库连接资源不足问题,和磁盘IO的性能瓶颈问题。分表:是为了解决单表数据量太大,sql语句查询数据时,即使走了索引也非常耗时问题。此外还可以解决消耗cpu资源问题。分库分表:可以解决 数据库连接资源不足、磁盘IO的性能瓶颈、检索数据耗时 和 消耗cpu资源等问题。
如果在有些业务场景中,用户并发量很大,但是需要保存的数据量很少,这时可以只分库,不分表。
如果在有些业务场景中,用户并发量不大,但是需要保存的数量很多,这时可以只分表,不分库。
如果在有些业务场景中,用户并发量大,并且需要保存的数量也很多时,可以分库分表。

烧脑?放松一下,听下音乐吧

点击下方















 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









