







摘要
- 在AES领域,预训练的语言模型没有被很适合地应用,来超过比如LSTM之类的深度学习方法。
- 本文介绍了一个新的基于BERT的多规模的文本表示模型,它能够被联合学习。我们也应用了多损失和来自其他领域文章的迁移学习来进一步提升性能。
- 本文的方法在ASAP数据集上取得了state-of-the-art的结果,并且提出的多规模文本表示在CRP数据集上的泛化结果也很好。
研究动机
- 当老师对一篇文章进行打分时,分数会受到多粒度级别的信号的影响,比如词级、句级和段落级等。


- 本文主要贡献如下:

方法
任务公式
- AES任务被定义如下:
给出一个有 n n n 个词的文本,我们需要输出一个分数 y y y 作为衡量这篇文章等级的结果。QWK指标通常被用来评估AES系统,它衡量了两个打分者之间的认同度。
多规模文本表示
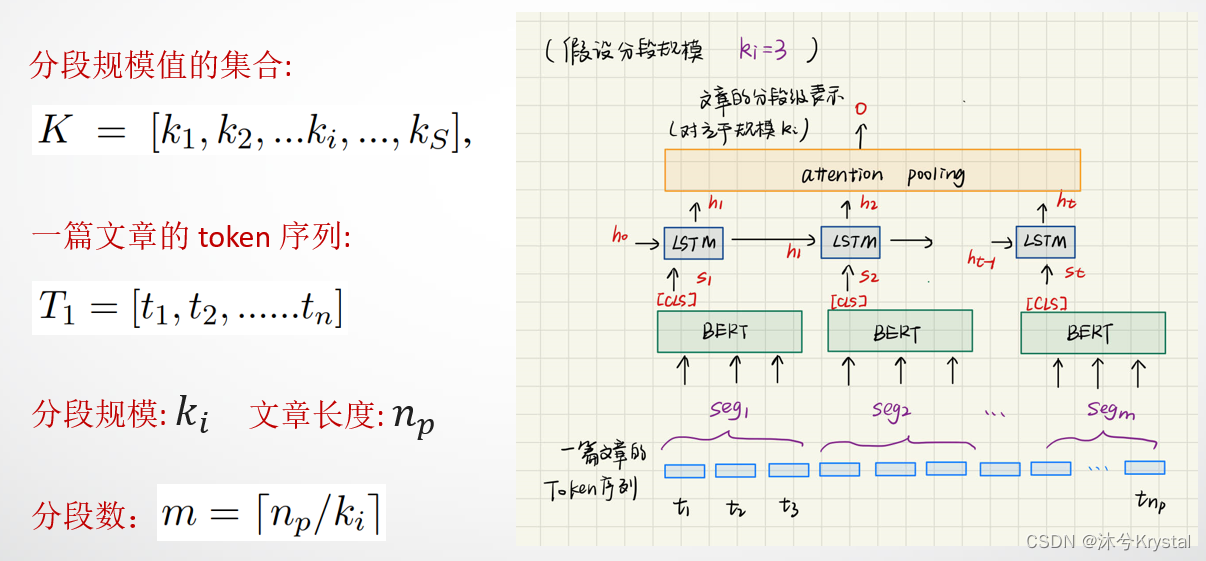
- 我们从三个规模获得多规模的文本表示:token规模,分段规模(segment)和文档规模。
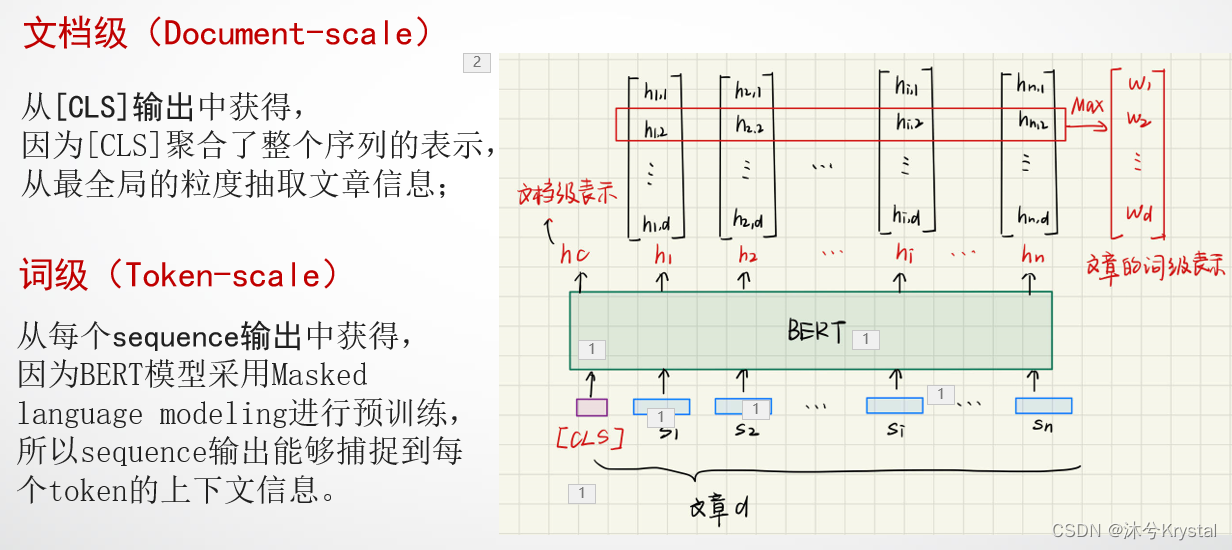
- Token规模和文档规模的输入:应用了一个预训练的BERT模型来得到token-scale和document-scale的文本表示。BERT标注器被用来将一篇文章分割成token序列
T
1
=
[
t
1
,
t
2
,
.
.
.
.
.
.
,
t
n
]
T_1=[t_1,t_2,......,t_n]
T1=[t1,t2,......,tn],token都指的是词片(WordPiece),它是由BERT使用的一个子词标注算法来获得的。我们从序列
T
1
T_1
T1构建了一个新的序列
T
2
T_2
T2:

最终的输入表示是以下3个嵌入的和:token嵌入,segmentation嵌入,position嵌入。 - Token级别和文档级别的表示:
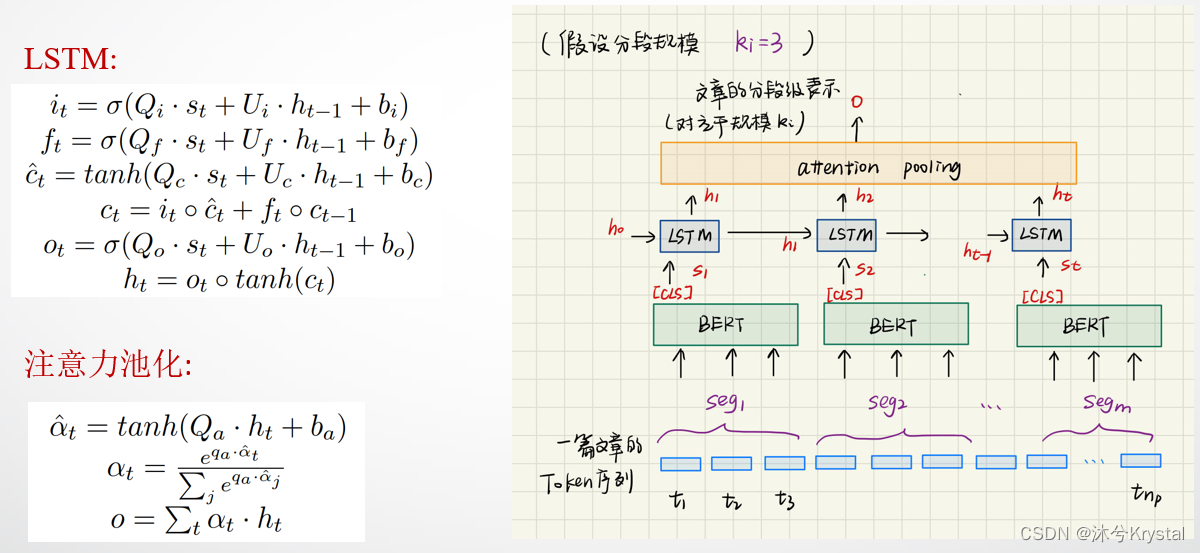
- 分段级别的表示:
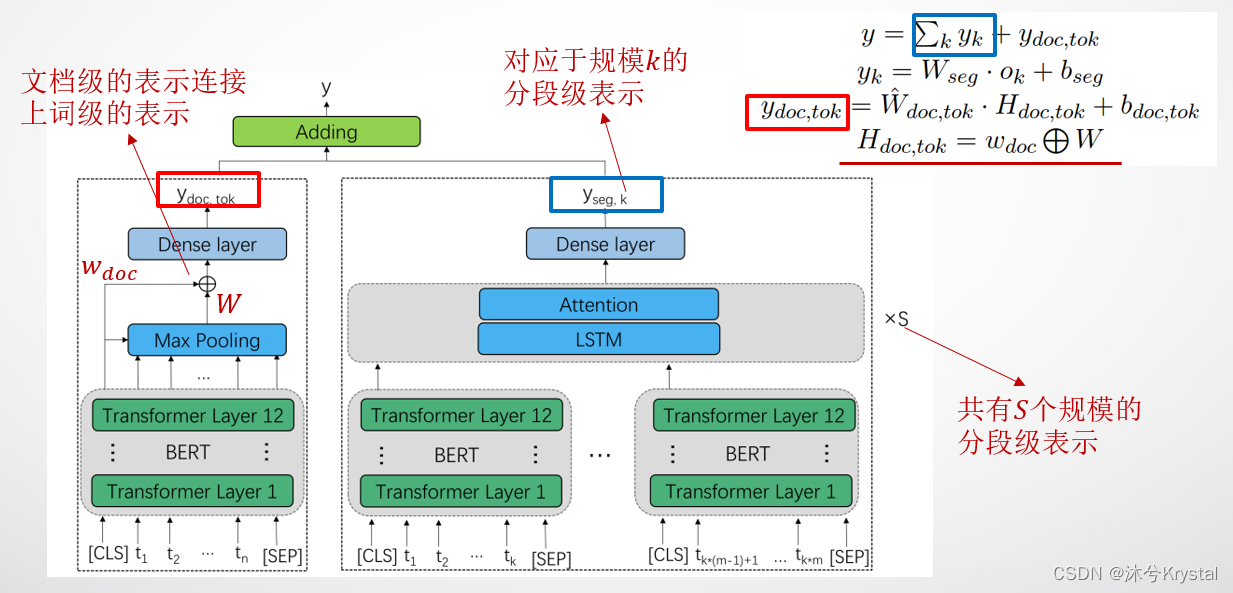
模型整体架构
损失函数
- 一个老师在打分时,考虑到所有学生的整体水平的分布。根据这一直觉,本文引入 SIM 损失到 AES 任务中。
- 在每个训练步骤中,我们将batch中的文章被预测的分数作为一个预测向量
y
y
y,SIM 损失奖励相似的向量对,来使得模型考虑到文章batch之间的相互关系。
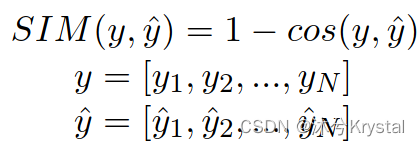
- MR度量了batch中每个文章对的排序顺序。我们直觉上引入MR损失,因为文章之间的排序属性是一个打分的关键因素。
- 对于文章的每个batch,我们首先枚举了所有的文章对,之后计算MR向下面这样计算MR损失,ME损失尝试使得模型惩罚错误的顺序。















 3135
3135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









