








1、安装环境
系统:centos6.5
hadoop2.2.0
eclipse:mars.1Release(4.5.1)
2、插件的安装
下载hadoop2.2.0的eclipse插件,解压之后放到eclipse的plugin目录下,重启eclipse。
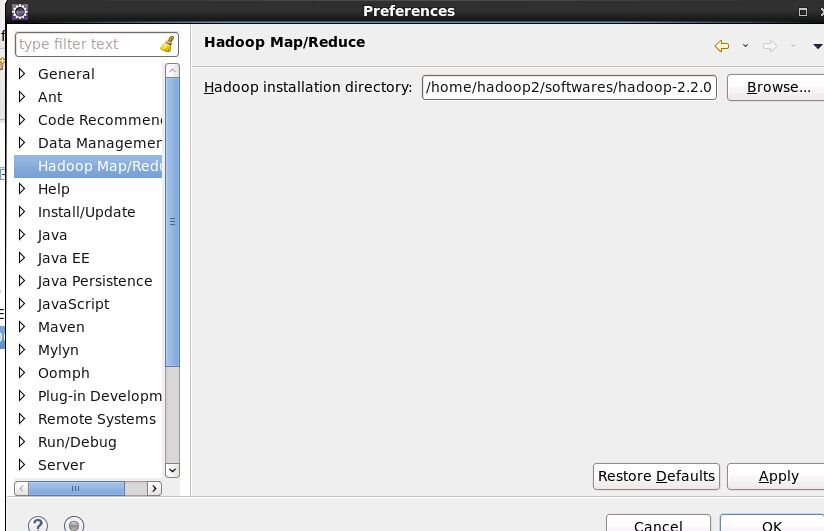
3、配置hadoop installation directory
如果安装插件成功,打开Window–>Preferens,你会发现Hadoop Map/Reduce选项,在这个选项里你需要配置Hadoop installation
directory。配置完成后退出。
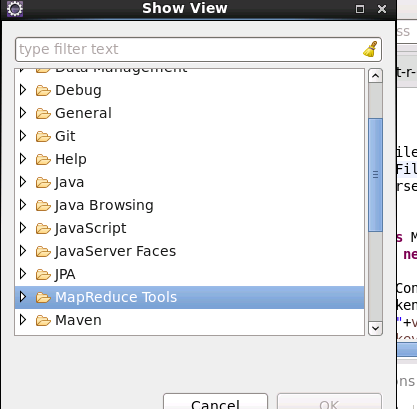
4、配置Map/Reduce Locations。
在Window–>Show View->other…,在MapReduce Tools中选择Map/Reduce Locations。
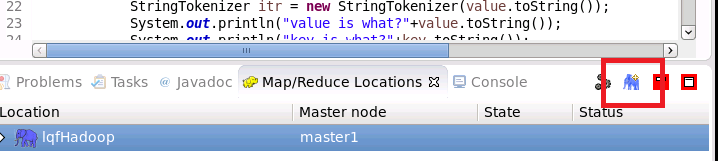
在Map/Reduce Locations(Eclipse界面的正下方)中新建一个Hadoop Location。在这个View中,点击鼠标右键–>New Hadoop Location。在弹出的对话框中你需要配置Location name,可任意填,如Hadoop,以及Map/Reduce Master和DFS Master。这里面的Host、Port分别为你在mapred-site.xml、core-site.xml中配置的地址及端口。
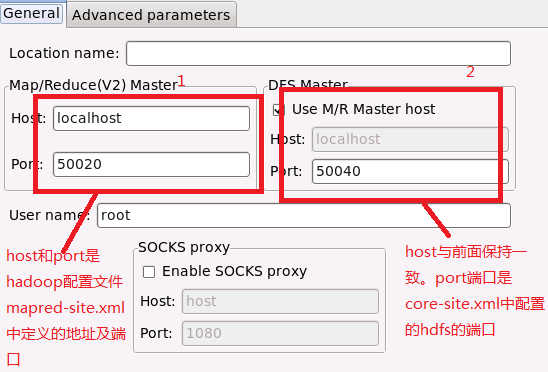
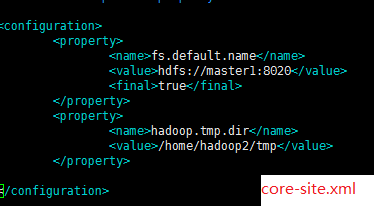
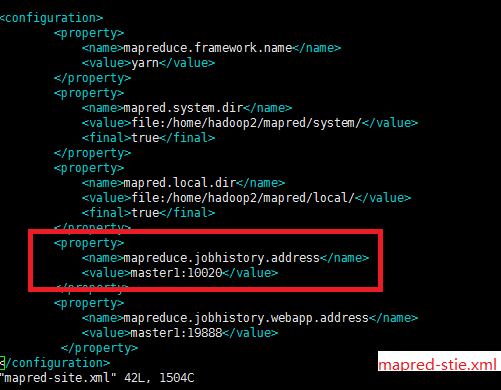
完成后可以看到对应的文件。我的这两个文件中配置如下:
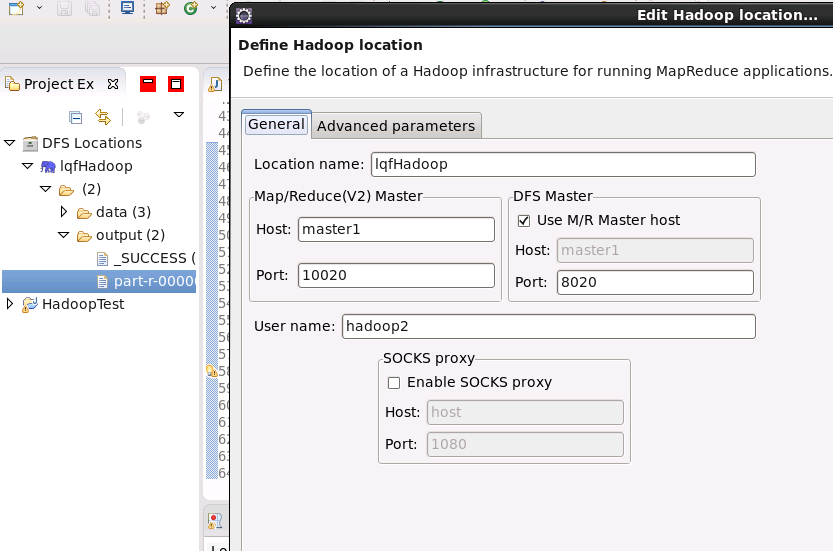
在左边就可以看到hdfs中的文件了。
5、运行一个wordcount项目测试
package edu.njupt.lqf;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public static class TokenizerMapper extends Mapper<Object,Text,Text,IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
StringTokenizer itr = new StringTokenizer(value.toString());
System.out.println("value is what?"+value.toString());
System.out.println("key is what?"+key.toString());
while(itr.hasMoreElements()){
word.set(itr.nextToken());
context.write(word, one);
System.out.println(one);
}
}
}
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException, InterruptedException{
int sum = 0;
for(IntWritable val:values){
sum +=val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
String[] dir= new String[2];
dir[0] = "hdfs://master1:8020/data/test";
dir[1] = "hdfs://master1:8020/output";
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,dir).getRemainingArgs();
for(String s:otherArgs){
System.out.println(s);
}
if(otherArgs.length !=2){
System.out.println("error");
System.exit(2);
}
Job job = new Job(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class); //
job.setCombinerClass(IntSumReducer.class); //
job.setReducerClass(IntSumReducer.class); //
job.setOutputKeyClass(Text.class); //
job.setOutputValueClass(IntWritable.class);//
FileInputFormat.addInputPath(job, new Path(otherArgs[0])); //
FileOutputFormat.setOutputPath(job,new Path(otherArgs[1]));
System.out.println(job.waitForCompletion(true)?0:1);
}
}
右键选择run ->java application ,如果执行成功刷新下hdfs的目录会出现 /output目录 结果就在part-r-00000文件















 67
67

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









