




 本文详细介绍使用SSD模型在Ubuntu16.04+CUDA8.0+CUDNN+Python2.7+caffe环境下进行目标检测的具体步骤,包括数据预处理、文件夹组织结构、文本生成脚本等内容。
本文详细介绍使用SSD模型在Ubuntu16.04+CUDA8.0+CUDNN+Python2.7+caffe环境下进行目标检测的具体步骤,包括数据预处理、文件夹组织结构、文本生成脚本等内容。
简介
为了加深对Caffe的理解,首先用ssd模型实现目标检测,基于上篇blog进行的caffe环境搭建基础,本篇框架依然用Ubantu16.04+CUDA8.0+CUDNN+Python2.7+caffe环境下搭建模型。具体过程如下:
一、数据准备
图像数据用的是车图像(cars_train),拿到车的图像时首先对图像进行预处理,因为我拿到的数据已经是加标好的数据,且加标都是纯手工的过程,所以此篇暂不解释如何加标(加标工具可以是labelimag,加标过程会在以后的blog中单篇列出来)
(坑:在做数据准备时,请一定一定先将caffe下的Makefile.config中的USE_OPENCV=1,否则你会在做的过程中入坑太深!!!) 如图所示:
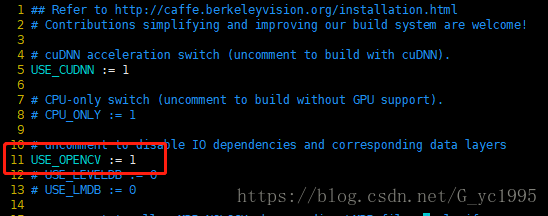
首先在caffe下一定要建立一个VOC_cars的文件夹存放在caffe的data文件下,在VOC_cars的文件夹下建立一个名为cars_train的文件,其中包含4个文件夹:
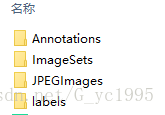 注意:四个文件夹是自己建的,可以通过 mkdir 新建
注意:四个文件夹是自己建的,可以通过 mkdir 新建
存放说明:
其中Annotations文件夹中存放labelimage导出的.xml文件,JPEGImages文件夹中存放.jpg格式的原始图像(用的图像如果是.png格式,可以命名为PNGImages),原始图像分两份进行存放,第一份就直接存放在JPEDImages文件夹下,第二份是在JPEGImages文件夹下新建两个名为test和trainval的空文件夹,将原始图像按照比例分别存放在两个文件夹中,我是按照1:4的比例存放在test和trainval中

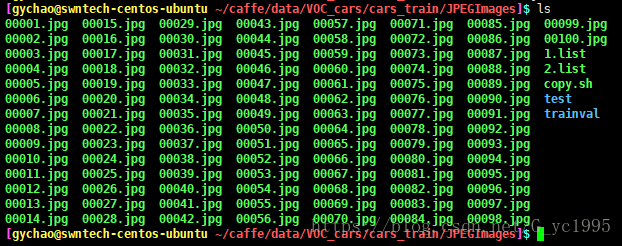
ImageSets文件夹用来存放用.sh和.py程序生成的.txt的文档,必须包含四个文档(我是把最后生成的lmdb也存放在了这个文件夹)分别是手打的labelmap_cars.prototxt文件,test.py生成的text.txt和trainval.txt和.sh脚本语言生成的test_name_size.txt文档,.txt四个文档必不可少,可以先用vim终端命令保存空文档,也可以直接在脚本和python编辑时自动生成(我时直接生成的)

labels文件夹存放图像的.txt格式的标注信息

代码:在caffe的data下新建一个main的文件夹,专门存放用于生成.txt文档的代码
.txt文档生成过程:
>>首先通过test.py文件生成test.txt和trainval.txt,特别注意,一定要仔细修改存放目录和地址
>>其次通过test_name_size.py文件生成test_name_size.txt
>>最后通过lmdb.sh文件将VOC_cars整个文件转为lmdb文件存放在指定的路径中
切记切记!一定要注意存放路径的问题!(程序中一定要根据自己存放路径进行修改)
#!/bin/bash
#!/usr/bin/evn python
# coding=utf-8
import os,sys
import glob
#jpg数据读入和输出地址
trainval_dir = "/home/gychao/caffe/data"
trainval_add = "/VOC_cars/cars_train/JPEGImages/trainval"
test_dir = "/home/gychao/caffe/data"
test_add = "/VOC_cars/cars_train/JPEGImages/test"
trainval_img_lists = glob.glob(trainval_dir + trainval_add + '/*.jpg')
trainval_img_names = []
for item in trainval_img_lists:
temp1, temp2 = os.path.splitext(os.path.basename(item) )
# trainval_img_names.append(" ")
trainval_img_names.append(temp1)
test_img_lists = glob.glob(test_dir + test_add + '/*.jpg')
test_img_names = []
for item in test_img_lists:
temp1, temp2 = os.path.splitext(os.path.basename(item) )
# test_img_names.append(" ")
test_img_names.append(temp1)
#xml数据读入和输出地址
dist_img_dir = "/home/gychao/caffe/data"
dist_img_add = "/VOC_cars/cars_train/JPEGImages"
dist_anno_dir = "/home/gychao/caffe/data"
dist_anno_add = "/VOC_cars/cars_train/Annotations"
trainval_fd = open("/home/gychao/caffe/data/VOC_cars/cars_train/ImageSets/trainval.txt","w+")
test_fd = open("/home/gychao/caffe/data/VOC_cars/cars_train/ImageSets/test.txt","w+")
for item in trainval_img_names:
trainval_fd.write(dist_img_add + '/' + str(item) + '.jpg' + ' ' + dist_anno_add + '/' + str(item) + '.xml\n' )#
for item in test_img_names:
test_fd.write(dist_img_add + '/' + str(item) + '.jpg' + ' ' + dist_anno_add + '/' + str(item) + '.xml\n')#最终导出的数据格式
#!/bin/bash
#!/usr/bin/evn python
# -*- coding: UTF-8 -*-
import os,sys
import glob
from PIL import Image
img_dir = "/home/gychao/caffe/data/VOC_cars/cars_train/JPEGImages/test"
img_list = glob.glob(img_dir + '/*.jpg')
test_name_size = open('/home/gychao/caffe/data/VOC_cars/cars_train/ImageSets/test_name_size.txt','w')
for item in img_list:
img = Image.open(item)
width, height = img.size
temp1, temp2 = os.path.splitext(os.path.basename(item) )
test_name_size.write(temp1 + '' + str(height) + '' + str(width) + '\n' )
#!/bin/bash
set -x
set -e
#export PATH=/src/caffe/proto/caffe.proto:$PATH
export PYTHONPATH=/home/gychao/caffe/python
cur_dir=$(cd $(dirname ${BASH_SOURCE[0]}) &&pwd)
root_dir='/home/gychao/caffe'
cd ${root_dir}
redo=1
data_root_dir="$HOME/caffe/data"
dataset_name="VOC_cars/cars_train/ImageSets"
#dataset_name_add="VOC_cars"
mapfile="$HOME/caffe/data/VOC_cars/cars_train/ImageSets/labelmap_cars.prototxt"
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=0
width=0
height=0
#check_label=True
extra_cmd="--encode-type=jpg --encoded"
if [${redo}];then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
do
#echo "test is ${test}"
#echo "trainval is ${trainval}"
python ${root_dir}/scripts/create_annoset.py --anno-type=${anno_type} \
--label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim \
--resize-height=$height --resize-width=$width ${extra_cmd} \
${data_root_dir} \
${data_root_dir}/${dataset_name}/${subset}.txt \
${data_root_dir}/${dataset_name}/$db/$dataset_name"_"$subset"_"$db \
examples
#按照caffe/scrips下的create_annoset.py文件修改,且根据问题适当修改这个文件中相对应的内容
done


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









