









目录
pip install pandas
sklearn.preprocessing是scikit-learn中的一个模块,用于数据预处理,包括标准化、缺失值填充、特征提取、特征选择等。要安装该模块,可以使用以下命令:
pip install -U scikit-learn
建议大家在学习数据分析时sklearn-learn模块也一并安装好
后续的学习操作会方便很多哦~
可能直接pip install pandas 仍然会有部分pandas库内函数无法使用,大概率是因为版本的问题,只需要多执行一个命令将其更新即可解决;
pip install pandas --upgrade
——这样就是更新完成了
数据读取
一般是 .csv文件 .xlsx文件(excel文件) .json文件
import pandas as pd
# 读取csv文件
data = pd.read_csv('data.csv')
# 读取excel文件
data = pd.read_excel('data.xlsx')
# 读取json文件
data = pd.read_json('data.json')
数据清洗
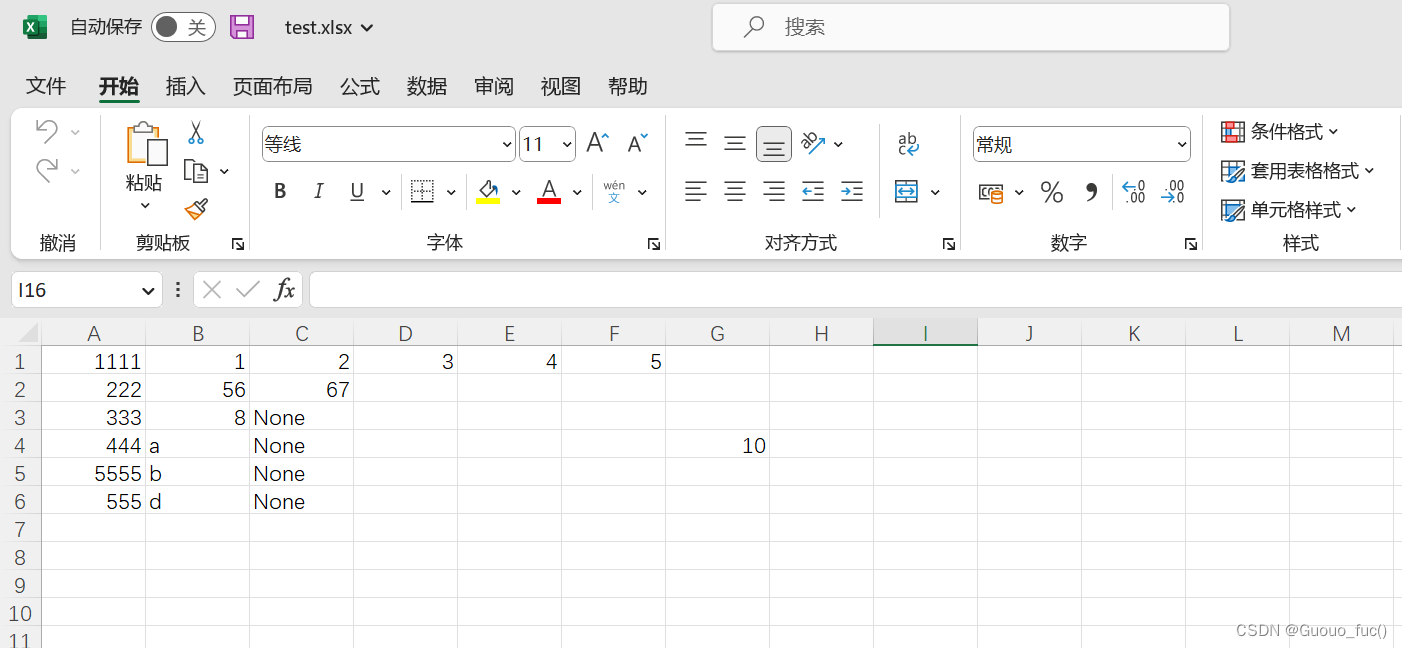
我的原始test.xlsx文件如下图:
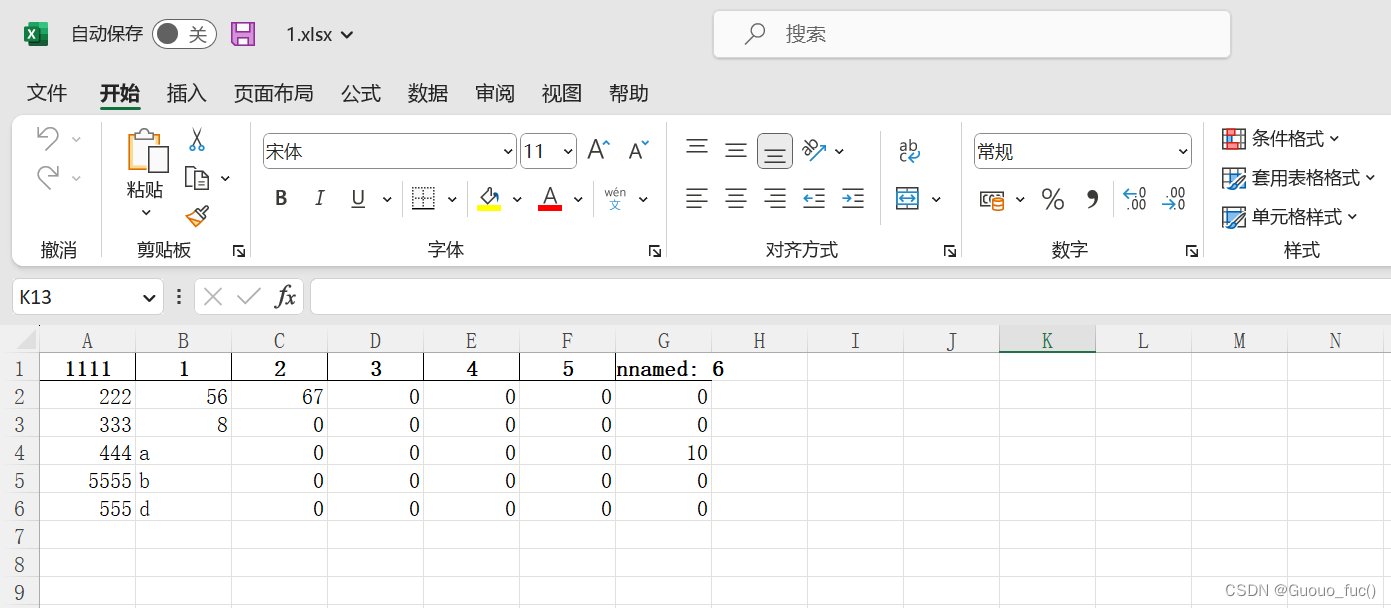
使用pandas库的fillna函数填充缺失值
其中函数会默认某些值为缺失值(如该列有值而该格为空的值,同时若表头无名也会补充名字unnamed:xx),其他缺失值可以由我们自己通过一个列表设定
import pandas as pd
# 可能会报错--缺少某个包 pip install openpyxl
in_FileName = input()
data = pd.read_excel(in_FileName,na_values=['None'])
# na_values参数可以设定我们自定义的缺失值
# 填充缺失值
data = data.fillna(0)
# pandas库中大多数操作是不会直接对原数据直接改动的,会返回一个新的对象
# 此处要看到效果的话可以另存一个新文件并打开
new_FileName = input() + '.xlsx'
data.to_excel(new_FileName,index=False)初步填充后效果图如下:
数据清洗中的其他用法:
import pandas as pd
# 可能会报错--缺少某个包 pip install openpyxl
in_FileName = input()
data = pd.read_excel(in_FileName,na_values=['None'])
# 进行xlsx替换/填充时,如果要显示非数字字符,要将原表中的单元格格式设置为文本模式,不然看不到替换/填充后的值
# data.dropna和data.fillna函数中都可以设置inplace=‘True’来对原表数据直接修改,而不需要用新对象接收
# 实际操作中建议先用一个对象接收避免不可预料的数据丢失和错误
new_FileName_ = input()
# 填充和删除时默认的axis=0,也就是默认删除/填充行,设置为axis=1则表示删除/填充列
# 填充缺失值
data_fill = data.fillna(0)
# pandas库中大多数操作是不会直接对原数据直接改动的,会返回一个新的对象
# 此处要看到效果的话可以另存一个新文件并打开
# data.to_excel(new_FileName_+'fill.xlsx',index=False)
# 删除缺失值
data_delete = data.dropna()
# data_delete.to_excel(new_FileName_+'delete.xlsx',index=False)
# 替换值
data_change = data.replace({'None': '*****'})
# data_change.to_excel(new_FileName_+'change.xlsx',index=False)
# 观看表前五行的数据
# print(data_change.head())
# 去重 用subset参数设置指定的列去重,若在该列上值相同,则涉及到重复的单元格所在的一整行都会被删除
# keep表示只保留重复的第一个值
# 为了准确指定subset列表中的的值(例如数字1和字符'1'的区分),可以用data.columns查看该表的列名
print(data.columns)
data_dup = data.drop_duplicates(subset =[1],keep='first')
# data_dup.to_excel(new_FileName_+'dup.xlsx',index=False)
数据分组
import pandas as pd
# 定义示例数据
data = {
'城市': ['北京', '北京', '上海', '上海', '广州', '广州'],
'日期': ['2021-01-01', '2021-01-02', '2021-01-01', '2021-01-02', '2021-01-01', '2021-01-02'],
'销售额': [100, 200, 300, 400, 500, 600]
}
df = pd.DataFrame(data)
# 查看原始数据
print(df)
# 城市 日期 销售额
# 0 北京 2021-01-01 100
# 1 北京 2021-01-02 200
# 2 上海 2021-01-01 300
# 3 上海 2021-01-02 400
# 4 广州 2021-01-01 500
# 5 广州 2021-01-02 600
# 按城市进行分组,并计算每个城市的销售额均值
df_grouped = df.groupby('城市')['销售额'].mean()
# 查看分组结果
print(df_grouped)
# 城市
# 上海 350.0
# 北京 150.0
# 广州 550.0
# Name: 销售额, dtype: float64通过groupby后的小括号设置分组标准,中括号设置分组后提取的数据,同时调用了sum()函数对数据求和
import pandas as pd
data = {
'name':['Xiaolin','Xiaoqie','Xiaoming','Xiaolin'],
'time':['4.10','4.11','4.12','4.13'],
'pay':[100,110,120,90]
}
# 将自己定义的数据变为pandas中的表格
data = pd.DataFrame(data)
result_1 = data.groupby('name')['pay'].sum()
print(result_1)
# name
# Xiaolin 190
# Xiaoming 120
# Xiaoqie 110
# Name: pay, dtype: int64
# 如按多个列分组则需传入列表
result_2 = data.groupby(['name','time'])['pay'].sum()
print(result_2)
# name time
# Xiaolin 4.10 100
# 4.13 90
# Xiaoming 4.12 120
# Xiaoqie 4.11 110
# Name: pay, dtype: int64可以使用agg函数对每组数据进行统计分析,也可以使用apply函数对每组数据进行自定义的计算
对agg函数的具体补充:
字符串:使用字符串作为键名可以将要应用的聚合函数的名称直接传递给
agg()方法。例如,agg('mean')表示应用平均函数来聚合分组数据。可以使用的聚合函数名称包括'count'、'sum'、'mean'、'median'、'min'、'max'等。元组:使用元组作为键名可以将要应用的聚合函数和列重命名传递给
agg()方法。例如,agg(('mean','average_score'))表示应用平均函数来聚合分组数据,并将聚合结果列重命名为'average_score'。字典:使用字典作为键名可以对不同的列应用不同的聚合函数。例如,
agg({'score':'mean', 'age':'max'})表示对score列应用平均函数来聚合分组数据,并对age列应用最大函数来聚合分组数据。
import pandas as pd
# 创建一个字典,包含姓名、性别、年龄、城市和薪水
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Emma'],
'Gender': ['Female', 'Male', 'Male', 'Male', 'Female'],
'Age': [25, 30, 35, 40, 45],
'City': ['New York', 'San Francisco', 'Los Angeles', 'Chicago', 'Boston'],
'Salary': [50000, 60000, 70000, 80000, 90000]
}
# 将字典转换为数据框
df = pd.DataFrame(data)
# 按性别分组并计算平均年龄和平均薪水
grouped = df.groupby('Gender').agg({'Age': 'mean', 'Salary': 'mean'})
# 打印结果
print(grouped)
# Age Salary
# Gender
# Female 35.0 70000.0
# Male 35.0 70000.0数据排序
import pandas as pd
data = {
'name':['Alice','Bob','Charlie','David','Eva'],
'age':[25,19,32,42,28],
'score':[89,92,85,78,95]
}
data = pd.DataFrame(data)
# 默认升序
data.sort_values(by='age',inplace=True)
print(data)
# name age score
# 1 Bob 19 92
# 0 Alice 25 89
# 4 Eva 28 95
# 2 Charlie 32 85
# 3 David 42 78
# 设置为降序
data.sort_values(by='age',ascending=False,inplace=True,)
print(data)
# name age score
# 3 David 42 78
# 2 Charlie 32 85
# 4 Eva 28 95
# 0 Alice 25 89
# 1 Bob 19 92
# 设置按多个列排序,从左往右按列比,如果相等再继续往右比较下一列的数据,同时ascending参数也要对应设置为对应列的排序规则
data_plus = {
'name':['ali','bob','eric','jack','blck'],
'score':[34,35,36,37,38],
'age':[18,19,18,19,17],
}
data_plus = pd.DataFrame(data_plus)
data_plus.sort_values(by=['age','score'],ascending=[False,True],inplace=True)
print(data_plus)
# name score age
# 1 bob 35 19
# 3 jack 37 19
# 0 ali 34 18
# 2 eric 36 18
# 4 blck 38 17
# 可以使用 sort_index() 方法按照索引进行排序,例如按照索引降序排序,
data_plus.sort_index(ascending=False,inplace=True)
print(data_plus)
# name score age
# 4 blck 38 17
# 3 jack 37 19
# 2 eric 36 18
# 1 bob 35 19
# 0 ali 34 18
# 可以使用 nlargest() 和 nsmallest() 方法实现部分排序,例如查找分数最高的两个人
top2 = data_plus.nlargest(2,'score')
print(top2)
# name score age
# 4 blck 38 17
# 3 jack 37 19
# 可以自定义函数并返回要比较的值来进行自定义排序,需要传入key参数
# 创建一个列表字典,包含姓名、分数和年龄
data_plus_2 = {
'name': ['ali', 'bob', 'eric', 'jack', 'blck'],
'score': [34, 35, 36, 37, 38],
'age': [18, 19, 18, 19, 17],
}
# 将列表字典转换为数据框
data_plus_2 = pd.DataFrame(data_plus_2)
# 定义一个自定义函数
# key函数应该接受一个Series并返回一个与输入形状相同的Series
# 我的sort_values函数接收的Series是name列,它是一个由字符串组成的一维数组,每个字符串表示一个名字。
# 我的key函数应该返回一个与输入形状相同的Series,也就是说,也应该是一个由字符串组成的一维数组。
# 我的key函数的目的是对每个字符串进行处理,使得排序时按照你想要的规则进行。
def my_func(name):
return name.map(lambda y: len(y))
# lambda y:len(y)的意思是定义一个匿名函数,它接受一个参数y,返回y的长度。
# map函数的作用是对原数组中的每个元素应用这个函数,得到一个新的数组。
# 所以,name.map(lambda y: len(y))的意思是将原数组中的每个名字替换为它的长度。
# 按照加权平均值对数据框进行升序排序
data_plus_2.sort_values(by='name', key=my_func, ascending=True, inplace=True)
# 打印结果
print(data_plus_2)
# name score age
# 0 ali 34 18
# 1 bob 35 19
# 2 eric 36 18
# 3 jack 37 19
# 4 blck 38 17应用函数
使用apply()函数导入自定义函数,从而对原数据进行一系列的变换
- 数学函数:Pandas 中的
apply()方法可以使用数学函数来对数据进行处理。例如,可以使用 NumPy 中的np.exp()方法对某一列进行指数运算: - 自定义函数:除了使用内置函数,还可以使用自定义函数来进行数据处理。例如,可以定义一个函数来对某一列进行运算:
- Lambda 函数:如果只需要对某一列进行简单的运算,可以使用 Lambda 函数来进行处理:
import pandas as pd
import numpy as np
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
# 可以使用 NumPy 中的 np.exp() 方法对某一列进行指数运算:
df['A_exp'] = df['A'].apply(np.exp)
# 可以使用自定义函数来进行数据处理
def my_function(x):
return x**2 + 5
df['A_squared_plus_5'] = df['A'].apply(my_function)
# Lambda 函数:如果只需要对某一列进行简单的运算,可以使用 Lambda 函数来进行处理
df['A_squared'] = df['A'].apply(lambda x: x**2)
# 需要注意的是,.apply() 方法通常是针对整列进行操作的。
# 如果需要对单个元素进行操作,可以使用 .applymap() 或 .map() 方法。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









