







 本文介绍了如何对小鹤音形的输入法进行个性化调整,包括调整搜狗输入法的词序、快捷键设置,以及对词库进行增删和合并,以适应快节奏时代的输入需求。作者还分享了使用Python处理词库的方法和使用AHK脚本提高输入速度的技巧。
本文介绍了如何对小鹤音形的输入法进行个性化调整,包括调整搜狗输入法的词序、快捷键设置,以及对词库进行增删和合并,以适应快节奏时代的输入需求。作者还分享了使用Python处理词库的方法和使用AHK脚本提高输入速度的技巧。
小鹤音形在双拼输入法上的自定义挂接
前言
这几天研究输入法效率问题,发现小鹤双拼之上还有鹤形的辅助定位。但纯小鹤音形的词库十分的固定,不适合当前快节奏时代多变的潮流,于是萌生了修改小鹤词库后挂接到PC端搜狗输入法的想法。优点是借助小鹤音形的精准定位和大数据词库的整词整句输入达成输入效率和个性化程度的提升。
提示:下面所有案例可供参考,更好的选择是根据自己情况和喜好自定取舍
一、对搜狗输入法PC端的基本调整
1.关于自动调整词序
如果搜狗重新上架了关闭自动根据使用频次调整词序的功能,建议一定要关闭。但是目前官方把这个功能藏起来了😅 所以只能依靠搜狗自定义短语来定序。但是对于常见的短语,使用全拼效率太低,而对于生僻的短语,我认为调整词序的功能反倒很方便。于是,在借鉴百度贴吧郜罗老哥的词库后,采取其词库并入主词库以达到“三码三字词+常用二字词定词序”的效果。
2.快捷键
在搜狗输入法“更多设置”里面设置。我设置的是二选分号;上屏,三选引号‘上屏。翻页 上页/下页 是
, / . 或 [ / ]
3.Tab的用法,U/V的用法
Tab键用法见 U模式笔画输入 拆字辅助码
U/V键用法见 搜狗官网U/V模式
二、对小鹤词库的增删修改
1.删除词库中二字三字和四以上词条
小鹤词库在网盘里
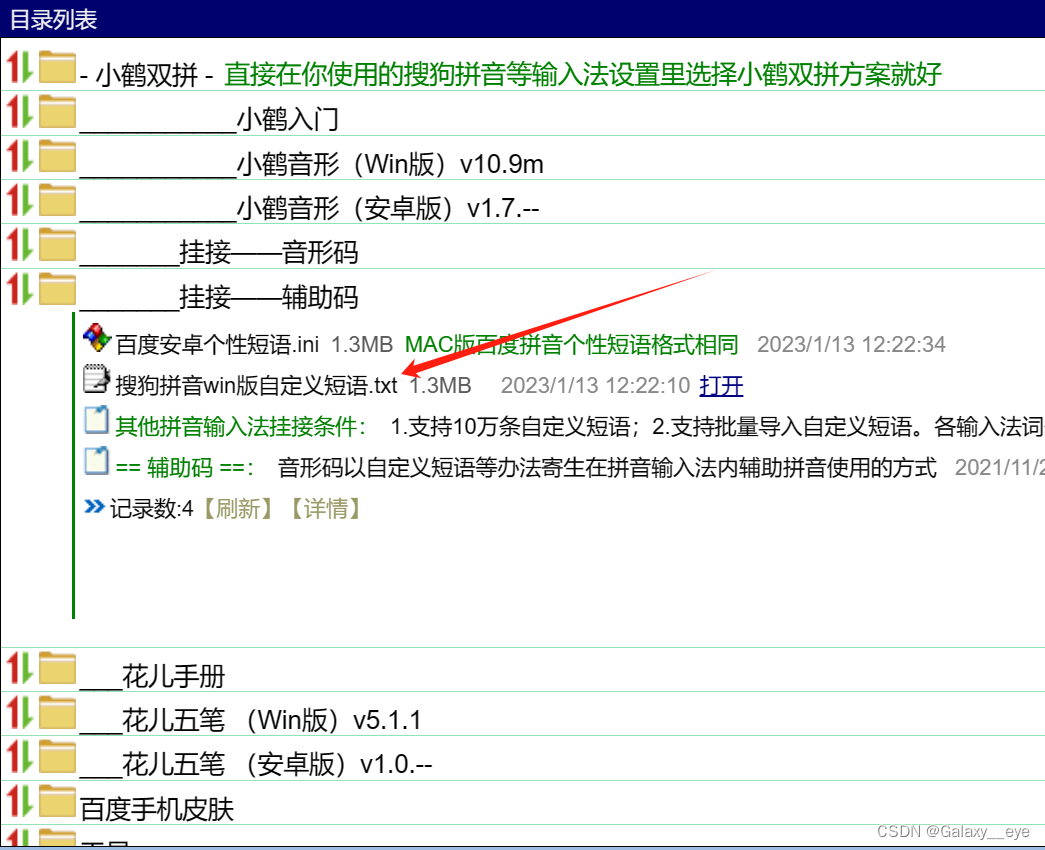
打开以后是
使用Python代码进行批量处理,代码如下(示例):
# -*- coding: utf-8 -*-
#!/usr/bin/env python
import re
def process_txt_file(file_path):
with open(file_path, 'r', encoding='utf-8', errors='ignore') as file:
content = file.read()
# 使用正则表达式找到等号后的中文词组
pattern = re.compile(r'.*?=(.*?)(?=\n|$)') # 匹配等号后的中文词组直到换行或文档结束
matches = re.finditer(pattern, content)
for match in matches:
chinese_phrase = match.group(1).strip()
chinese_length = len([c for c in chinese_phrase])
if chinese_length == 2 or chinese_length == 3 or chinese_length > 4:
content = content.replace(match.group(0), '', 1)
with open(file_path, 'w', encoding='utf-8') as file:
file.write(content)
# 替换下面的路径为你的txt文件路径
file_path = './PhraseEdit.txt'
process_txt_file(file_path)
如果是百度输入法的用户,下载上图箭头上一项ini文件,后缀改txt后用下面的Python文件处理:
# -*- coding: utf-8 -*-
#!/usr/bin/env python
import re
def remove_lines_with_two_chinese_chars(filename):
try:
# 打开文件并读取内容
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
# 过滤掉长度为2的中文行
lines = [line for line in lines if not contains_two_chinese_chars(line)]
# 将处理后的内容写回文件
with open(filename, 'w', encoding='utf-8') as file:
file.writelines(lines)
print(f'成功处理文件: {filename}')
except Exception as e:
print(f'处理文件时出现错误: {e}')
def contains_two_chinese_chars(line):
# 使用正则表达式检测是否包含长度为2的中文字符
chinese_chars = re.findall(r'[\\p{sc=Han}]', line)
return (len(chinese_chars) == 2 or len(chinese_chars) == 3 or len(chinese_chars) > 4)
# 替换成你的文件名
filename = 'SampleXiaoHe.txt'
# 调用函数
remove_lines_with_two_chinese_chars(filename)
如果不喜欢空行,用下面这个过一下删除空行:
# -*- coding: utf-8 -*-
#!/usr/bin/env python
def remove_empty_lines(filename):
try:
# 打开原文件并读取内容
with open(filename, 'r', encoding='utf-8') as file:
lines = file.readlines()
# 过滤掉空行
non_empty_lines = [line for line in lines if line.strip() != '']
# 打开新文件并将非空行写入
with open(filename, 'w', encoding='utf-8') as file:
file.writelines(non_empty_lines)
print(f'成功删除空行: {filename}')
except Exception as e:
print(f'处理文件时出现错误: {e}')
# 替换成你的文件名
filename = 'SampleXiaoHe.txt'
# 调用函数
remove_empty_lines(filename)
2.加入想要的符号和自定义短语
步骤
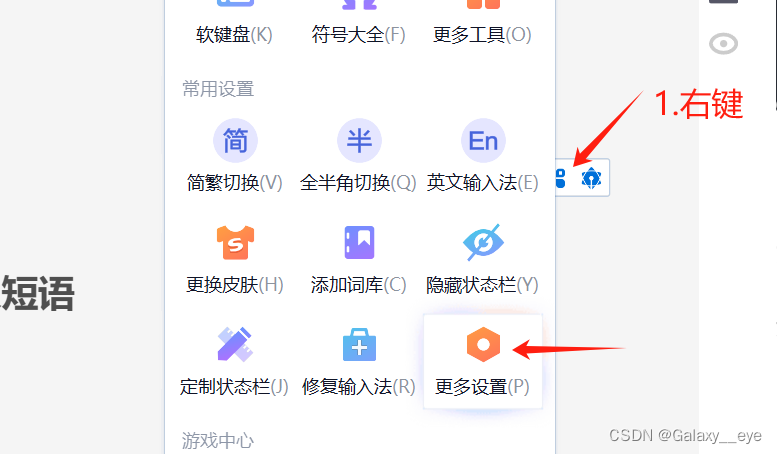
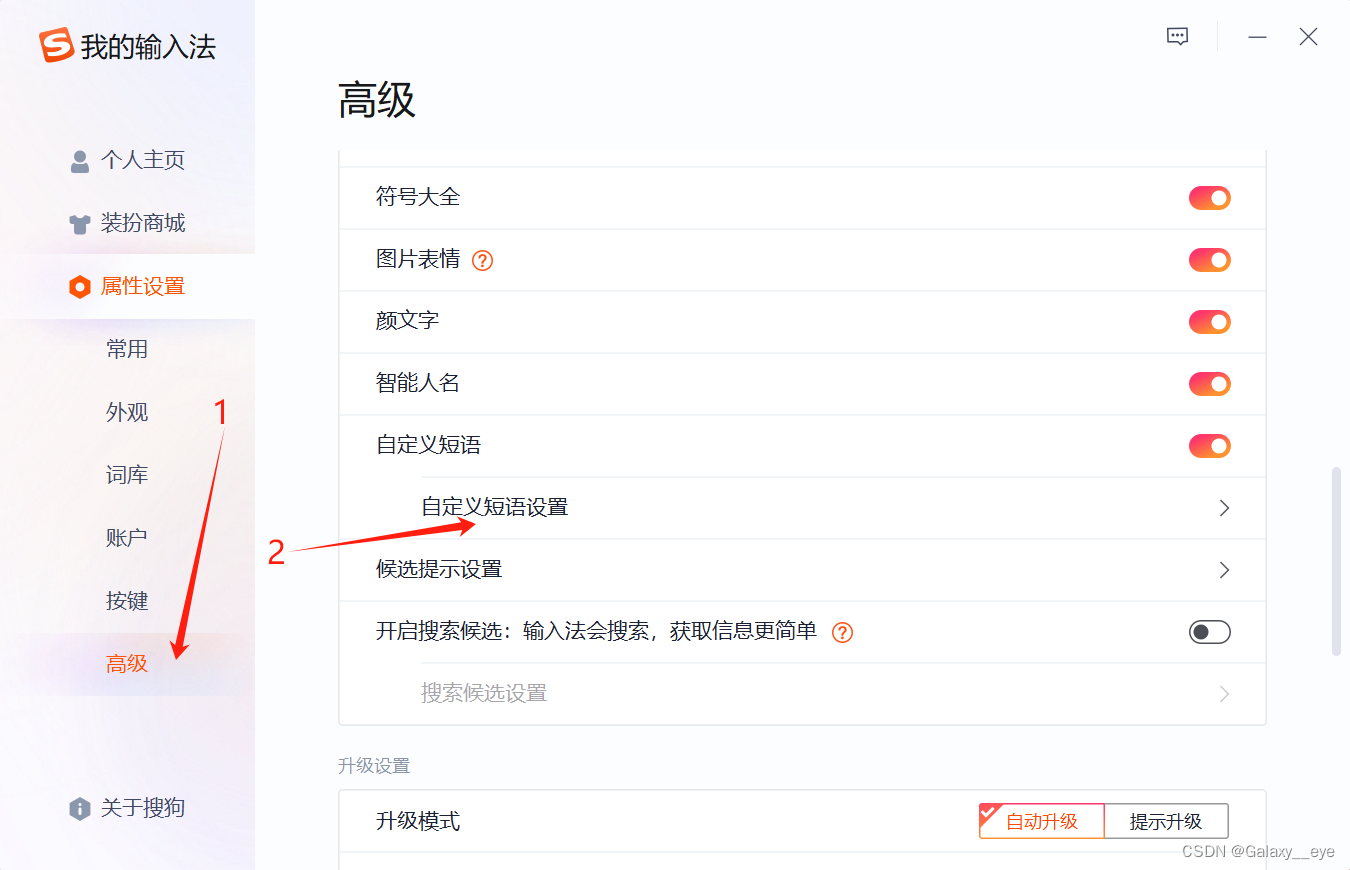
自定义添加示例如图
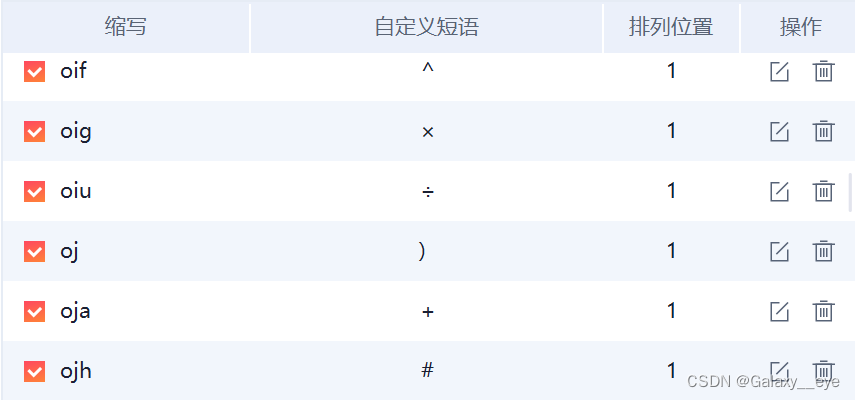
三、并入二三字词库
复制粘贴至配置文件PhraseEdit.txt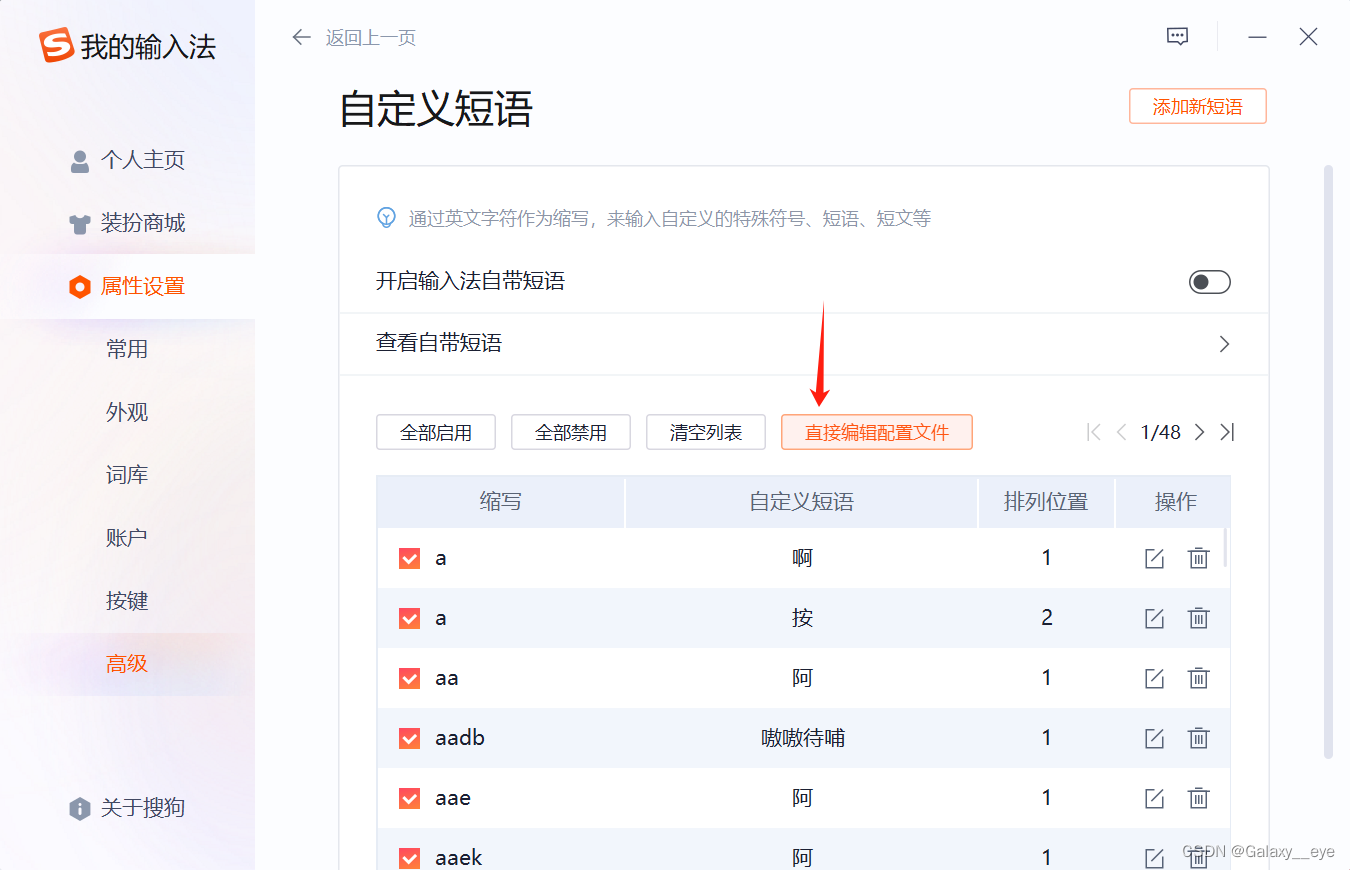
四*、删除部分英文词库
四字及以下的英文单词的提示会扰乱词序,如maid干扰蟆的全码。于是只保留四字以上的单词(现在我没时间,有时间再弄)。
五、最终效果


“窝锦天”的打法

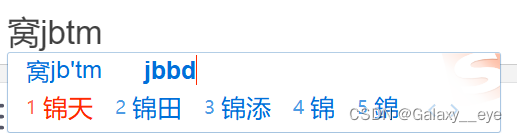

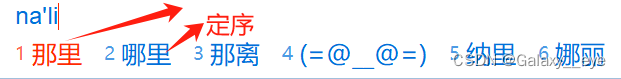
EX、还有一件事| AHK
有智能输入法的地方就有候选数字难按的问题。为了方便按3456789的候选,我采用了AutoHotKey脚本来增速。设置(CapsLock或分号)+esdf/wr为方向键/HomeEnd键,方便移动光标;设置Space+asdfghjkl为1-9。后缀为ahk的脚本代码如下:
#NoEnv ; Recommended for performance and compatibility with future AutoHotkey releases.
; #Warn ; Enable warnings to assist with detecting common errors.
SendMode Input ; Recommended for new scripts due to its superior speed and reliability.
SetWorkingDir %A_ScriptDir% ; Ensures a consistent starting directory.
CapsLock & e:: Up
CapsLock & s::Left
CapsLock & d::Down
CapsLock & f::Right
CapsLock & w::Home
CapsLock & r::End
`;:: Send {`;}
+`;:: Send {:}
`; & e:: Up
`; & s:: Left
`; & d:: Down
`; & f:: Right
`; & w:: Home
`; & r:: End
Space::Space
Space & a:: 1
Space & s:: 2
Space & d:: 3
Space & f:: 4
Space & g:: 5
Space & h:: 6
Space & j:: 7
Space & k:: 8
Space & l:: 9
建议写完后右键选Compile Script编译为exe文件方便使用和迁移。AHK快速入门
总结
这里总结一 下:这种杂合自用词库不知道有无版权,所以我暂时发一个自用DIY版,侵删请私聊。
附:
[小鹤音形入门及社区](https://flypy.com/)
[小鹤字形查询](http://react.xhup.club/search)
[AHK官网中文手册](https://ahkcn.sourceforge.net/docs/Tutorial.htm)
自用词库 提取码:wrnb

















 992
992

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









