







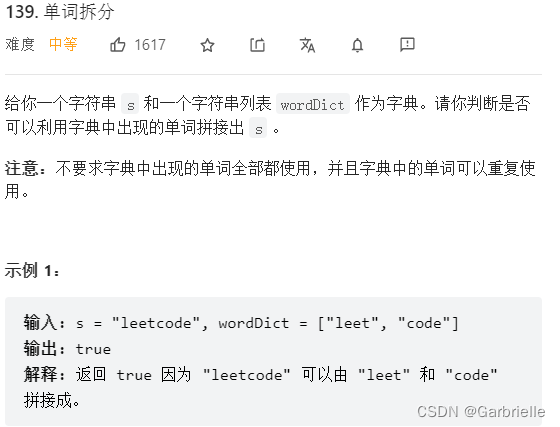
139. 单词拆分
动态规划
dp[i]代表的是能够实现str【0,i】的boolean值。
判断的是j(从【0,i】【j,i】的子字符串是否在字典中,且对应的dp[j]存在。即【0,j】子字符串可以实现,且【j,i】存在在字典中,那么当前dp[i]也可以实现,值为true。
var wordBreak = function(s, wordDict) {
const dp = Array(s.length+1).fill(false);
dp[0] = true;
const hash = {};
for(let k of wordDict) {
hash[k] = true;
}
for(let i = 1; i <= s.length; i++) {
for(let j = 0; j < i; j++) {
let str = s.substring(j, i);
if (dp[j] && hash[str]) {
dp[i] = true;
break;
}
}
}
console.log(dp)
return dp[s.length];
};
dfs + memory记录计算过的(dp)
深度优先的方案: 用memory存储子字符串是否能实现的bollean值(减少重复计算)。
memory[i]每一项代表的是从【i,str.length-1】的子字符串的bollean值。当start值到边界说明可以实现直接返回true。
所以每一个位置的判断都是从【start, i】在字典中,且递归start = i的情况也为真则返回true.
var wordBreak = function(s, wordDict) {
// memory(从start开始,组合成功的走到边界的dp[start]才=true)
const dp = Array(s.length);
const hashSet = new Set(wordDict);
var canBreak = function (start) {
// start移动到最后一个元素边界,成功找到结束递归
if (s.length === start) return true;
if (dp[start] !== undefined) return dp[start];
for(let i = start+1; i <= s.length; i++) {
let str = s.substring(start, i);
if (hashSet.has(str) && canBreak(i)) {
dp[start] = true;
return true;
}
}
dp[start] = false;
return false;
}
return canBreak(0);
console.log(dp);
};
bfs
广度优先的方案是: 维护一个元素为指针的队列,指针描述的是一个start下标对应的节点;
每次取队首元素,从start开始截取字符串【start, i】(i 【start+1, str.length】),如果当前子字符串存在在字典中,若i < len 即未到字符串边界,将当前(i下标)push进入队列中,否则说明可以实现。
var wordBreak = function(s, wordDict) {
// visited表示当前节点访问过
const visted = Array(s.length);
const hashSet = new Set(wordDict);
// 维护一个队列,依然用指针描述一个节点, start。
const queue = [0];
while(queue.length !== 0) {
// 取队首元素,为start开始下标
let start = queue.shift();
if (visted[start]) continue;
visted[start] = true;
for(let i = start+1; i <= s.length; i++) {
let str = s.substring(start, i);
if (hashSet.has(str)) {
if (i < s.length) {
queue.push(i);
} else {
return true;
}
}
}
}
return false;
};














 881
881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









