-- ------------------if语句----------------------------
select if(TRUE, 100, 200);
select if(FALSE, 100, 200);
select *,
if(sscore >= 60, '及格', '不及格') as flag
from score;
-- ------------------case语句----------------------------
/*
口径不统一:
A表:性别: m f
B表:性别:男,女
*/
select *,
case sex
when 'm' then '男'
when 'f' then '女'
end as gender
from test3;
select *,
case
when sscore >= 90 then '优秀'
when sscore >= 80 then '良好'
when sscore >= 60 then '及格'
when sscore < 60 then '不及格'
else '其他' end
from score;
select *,
case
when salary >= 100000 then '高薪'
where salary >= 5000 then '工薪'
when sscore < 3000 then '屌丝'
else '其他' end
from score;
-- 类型转换函数
select cast(12.95 as int);
select cast('20190607' as int);
select cast('2020-12-05' as date);
select cast(123 as string);
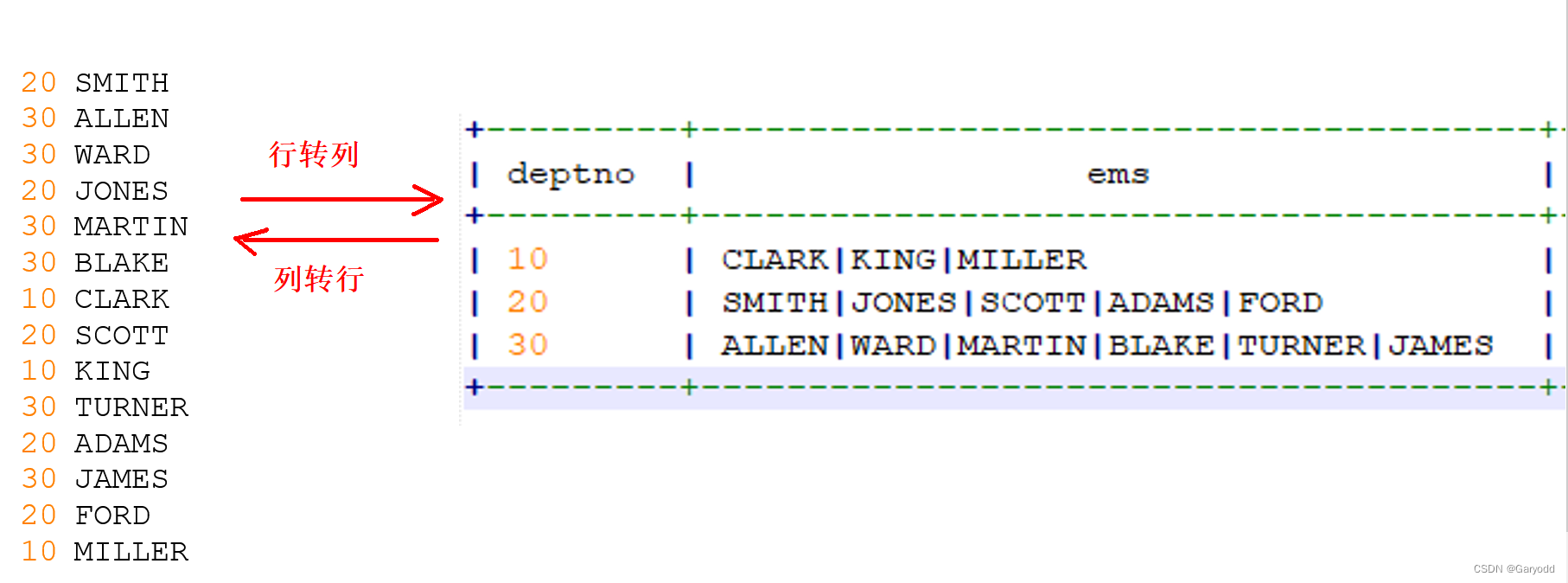
行转列和列转行函数
行转列和列转行函数
/*
20 SMITH
30 ALLEN
30 WARD
20 JONES
30 MARTIN
30 BLAKE
10 CLARK
20 SCOTT
10 KING
30 TURNER
20 ADAMS
30 JAMES
20 FORD
10 MILLER
*/
-- 1、建表
create table emp(
deptno int,
ename string
) row format delimited fields terminated by '\t';
-- 2、加载数据
load data local inpath '/root/test/test1.txt' into table emp;
-- 3、实现
select * from emp;
set hive.stats.column.autogather=false;
set hive.exec.mode.local.auto=true; --开启本地mr
-- collect_list可以将每一组的ename存入数组,不去重
select deptno,collect_list(ename) from emp group by deptno;
-- collect_list可以将每一组的ename存入数组,去重
select deptno,collect_set(ename) from emp group by deptno;
-- collect_list可以将每一组的ename存入数组,去重,concat_ws将数组中的每一个元素进行拼接
select deptno,concat_ws('|',collect_set(ename)) as enames from emp group by deptno;
列转行
-- 1、建表
create table emp2(
deptno int,
names array<string>
)
row format delimited fields terminated by '\t'
collection items terminated by '|';
-- 2、加载数据
load data local inpath '/root/test/test2.txt' into table emp2;
select * from emp2;
-- 3、SQL实现
select explode(names) from emp2; -- 此方法行不通
-- 将原来的表emp2和炸开之后的表进行内部的关联,判断炸开的每一行都来自哪个数组
select * from emp2 lateral view explode(names) t as name;
-- t是explode生成的函数的别名,name是explode列的别名
select deptno, name from emp2 lateral view explode(names) t as name
Hive的窗口函数
分组排序函数
/*
user1,2018-04-11,5
user2,2018-04-12,5
user2,2018-04-12,5
user1,2018-04-11,5
user2,2018-04-13,6
user2,2018-04-11,3
user2,2018-04-12,5
user1,2018-04-10,1
user2,2018-04-11,3
user1,2018-04-12,7
user2,2018-04-12,5
user1,2018-04-13,3
user2,2018-04-13,6
user1,2018-04-14,2
user1,2018-04-15,4
user1,2018-04-16,4
user2,2018-04-10,2
user2,2018-04-14,3
user1,2018-04-11,5
user2,2018-04-15,9
user2,2018-04-16,7
*/
-- 1、建表
CREATE TABLE test_window_func1(
userid string,
createtime string, --day
pv INT
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
-- 2、加载数据:
load data local inpath '/root/test/test3.txt' overwrite into table test_window_func1;
select * from test_window_func1;
-- 3、需求:按照用户进行分组,并且在每一组内部按照pv进行降序排序
-- row_number,rank,dense_rank
/*
partition by userid 按照哪个字段分组,等价于group by
order by pv desc 组内按照哪个字段排序
*/
select
*,
row_number() over (partition by userid order by pv desc) as rk_row_number, -- 1 2 3 4 5
rank() over (partition by userid order by pv desc) as rk_rank, -- 1 2 3 3 5
dense_rank() over (partition by userid order by pv desc) as rk_dense_rank -- 1 2 3 3 4
from test_window_func1;
-- 如果没有分组partition by 的情况
-- 将整整表看做是一组
select
*,
dense_rank() over (order by pv desc) as rk_dense_rank
from test_window_func1;
-- 如果没有分组order by 的情况
select
*,
row_number() over (partition by userid ) as rk_row_number, -- 1 2 3 4 5
rank() over (partition by userid ) as rk_rank, -- 1 1 1 1 1
dense_rank() over (partition by userid ) as rk_dense_rank -- 1 1 1 1 1
from test_window_func1;
-- 需求:求每一组的PV最多的前3个:每组的Top3
-- 方式1
select * from (
select
*,
dense_rank() over (partition by userid order by pv desc) as rk
from test_window_func1
) t
where rk <= 3;
-- 方式2
with t as (
select
*,
dense_rank() over (partition by userid order by pv desc) as rk
from test_window_func1
)
select * from t where rk <= 3;
聚合开窗函数
-- ----------------聚合开窗---------------
-- 默认是从开头累加到当前行
select userid,createtime,pv,
sum(pv) over(partition by userid order by createtime ) as pv1
from test_window_func1;
-- 作用同上
select userid,createtime,pv,
sum(pv) over(partition by userid order by createtime
rows between unbounded preceding and current row ) as pv1
from test_window_func1;
-- 指定从上一行加到当前行
select userid,createtime,pv,sum(pv) over(partition by userid order by createtime
rows between 1 preceding and current row ) as pv1
from test_window_func1;
-- 指定从上一行加到下一行
select userid,createtime,pv,sum(pv) over(partition by userid order by createtime
rows between 1 preceding and 1 following ) as pv1
from test_window_func1;
-- max
select userid,createtime,pv,
max(pv) over(partition by userid order by createtime ) as pv1
from test_window_func1;
-- min
select userid,createtime,pv,
min(pv) over(partition by userid order by createtime ) as pv1
from test_window_func1;
lag和lead函数
-- lag 和lead函数
-- 将pv列的上一行数据放在当前行
select *,
lag(pv,1,0) over(partition by userid order by createtime)
from test_window_func1;
-- 将pv列的下一行数据放在当前行
select *,
lead(pv,1,0) over(partition by userid order by createtime)
from test_window_func1;
-- ------------------模拟漏斗模型-----------------------------
/*
stage1 1000
stage2 800
stage3 50
stage4 2
*/
-- 1、创建表
create table demo( stage string, num int)
row format delimited fields terminated by '\t'
;
-- 2、加载数据
load data local inpath '/root/test/test4.txt' into table demo;
select * from demo;
-- 3、代码实现
with t as (
select *,
lag(num,1,-1) over (order by stage) as pre_num
from demo
)
select *, concat(floor((num / pre_num)*100),'%') as rate from t where stage > 'stage1';

























 2808
2808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









