







引言
我这篇博客主要是基于CSDN博主「z_ryan」的原创文章。原文链接:https://blog.csdn.net/z_ryan/article/details/79685072。做的一些笔记和自己的一些理解。如有侵权请联系我删除。
我们都知道二叉查找树的查找的时间复杂度是O(log N),其查找效率已经足够高了,那为什么还有B树和B+树的出现呢?难道它两的时间复杂度比二叉查找树还小吗?
答案当然不是,B树和B+树的出现是因为另外一个问题,那就是磁盘IO;众所周知,IO操作的效率很低,那么,当在大量数据存储中,查询时我们不能一下子将所有数据加载到内存中,只能逐一加载磁盘页,每个磁盘页对应树的节点。造成大量磁盘IO操作(最坏情况下为树的高度)。平衡二叉树由于树深度过大而造成磁盘IO读写过于频繁,进而导致效率低下。
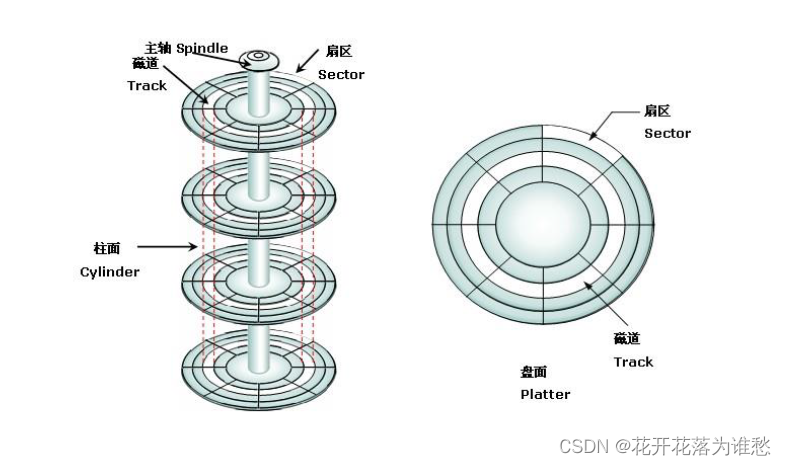
下面附上磁盘存取的图片,其实磁盘IO之所以慢,是因为磁盘转动和移动磁头花的时间比较多。 扇区——512字节,驱动器有大量的扇区组成。
很多文件系统一次读取或写入4KB(或者更多)。我们只能保证每个扇区是原子操作。
IO的过程主要是:寻道(耗时非常多),等待转动延迟,最后传输。
还涉及到操作系统磁盘调度的方案:最短寻道时间优先,电梯(SCAN,C-SCAN,就是磁头来回扫,放置防止一些任务饿死),最短定位时间优先(SPTF也称最短接入时间优先)
所以,我们为了减少磁盘IO的次数,就你必须降低树的深度,将“瘦高”的树变得“矮胖”。一个基本的想法就是:
(1)、每个节点存储多个元素
(2)、摒弃二叉树结构,采用多叉树
这样就引出来了一个新的查找树结构 ——多路查找树。 根据AVL给我们的启发,一颗平衡多路查找树(B~树)自然可以使得数据的查找效率保证在O(logN)这样的对数级别上。

B树
一个m阶的B树具有如下几个特征:B树中所有结点的孩子结点最大值称为B树的阶(我理解为每个节点的孩子),通常用m表示。一个结点有k个孩子时,必有k-1个key才能将子树中所有key划分为k个子集。
1.根结点至少有两个子女。
2.每个中间节点都包含k-1个元素和k个孩子,其中 ceil(m/2) ≤ k ≤ m
3.每一个叶子节点都包含k-1个元素,其中 ceil(m/2) ≤ k ≤ m
4.所有的叶子结点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
6.每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)
其中,Ki(1≤i≤n)为关键字,且Ki<Ki+1(1≤i≤n-1)。
Ai(0≤i≤n)为指向子树根结点的指针。且Ai所指子树所有结点中的关键字均小于Ki+1。
n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1。
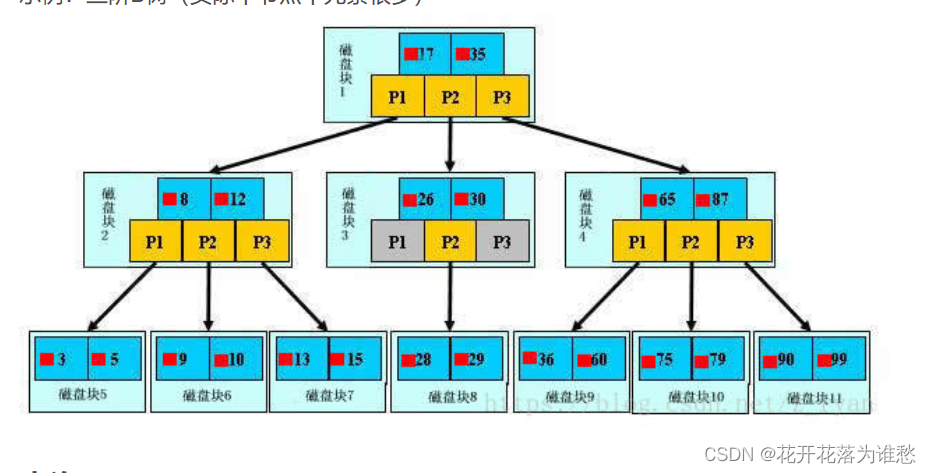
示例:三阶B树(实际中节点中元素很多)
 我自己输入了一遍,生成的是这样的
我自己输入了一遍,生成的是这样的
 我们代入B树的条件检查一下吧。
我们代入B树的条件检查一下吧。
1.根结点至少有两个子女。
2.每个中间节点都包含k-1个元素和k个孩子,其中 ceil(m/2) ≤ k ≤ m.即 1 ≤ k ≤ 3
3.每一个叶子节点都包含k-1个元素,其中 ceil(m/2) ≤ k ≤ m.即 1 ≤ k ≤ 3
4.所有的叶子结点都位于同一层。
5.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
6.每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An)
其中,Ki(1≤i≤n)为关键字,且Ki<Ki+1(1≤i≤n-1)。
Ai(0≤i≤n)为指向子树根结点的指针。且Ai所指子树所有结点中的关键字均小于Ki+1。
n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1。
查询
以上图为例:若查询的数值为5:
第一次磁盘IO:在内存中定位(与17、35比较),比17小,左子树;
第二次磁盘IO:在内存中定位(与8、12比较),比8小,左子树;
第三次磁盘IO:在内存中定位(与3、5比较),找到5,终止。
整个过程中,我们可以看出:比较的次数并不比二叉查找树少,尤其适当某一节点中的数据很多时,但是磁盘IO的次数却是大大减少。比较是在内存中进行的,相比于磁盘IO的速度,比较的耗时几乎可以忽略。所以当树的高度足够低的话,就可以极大的提高效率。相比之下,节点中的元素多点也没关系,仅仅是多了几次内存交互而已,只要不超过磁盘页的大小即可。
插入
对高度为k的m阶B树,新结点一般是插在叶子层。通过检索可以确定关键码应插入的结点位置。然后分两种情况讨论:
1、 若该结点中关键码个数小于m-1,则直接插入即可。
2、 若该结点中关键码个数等于m-1,则将引起结点的分裂。以中间关键码为界将结点一分为二,产生一个新结点,并把中间关键码插入到父结点(k-1层)中
重复上述工作,最坏情况一直分裂到根结点,建立一个新的根结点,整个B树增加一层。
示例如下:
1.插入16的情况
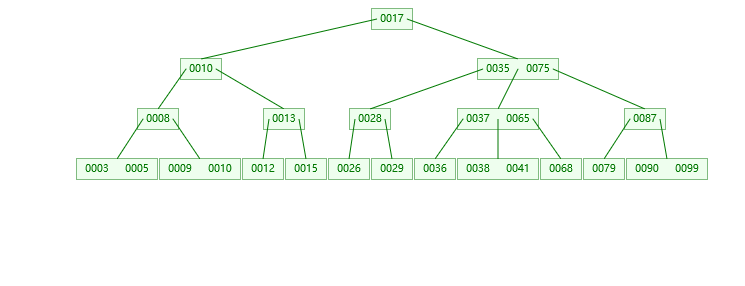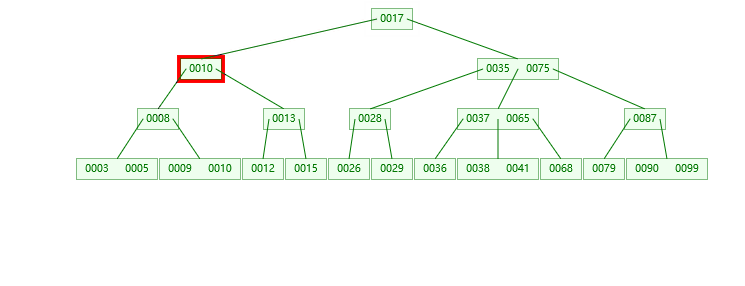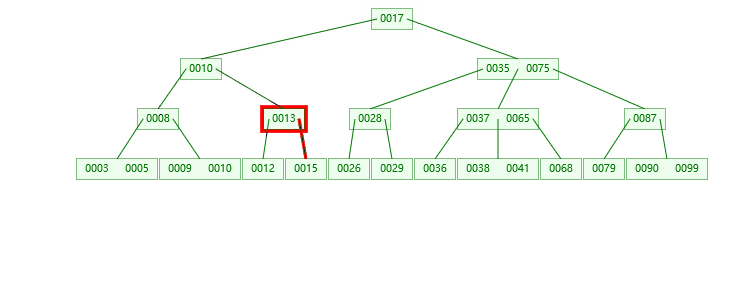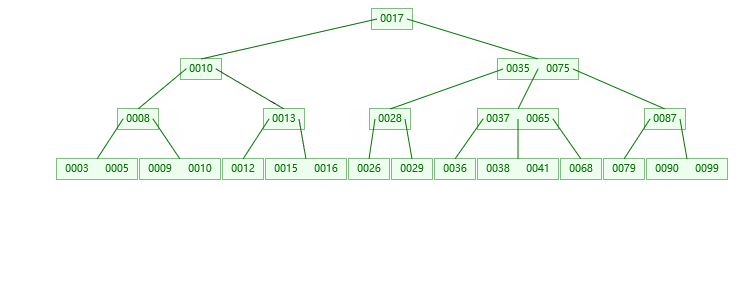
2.插入37的情况
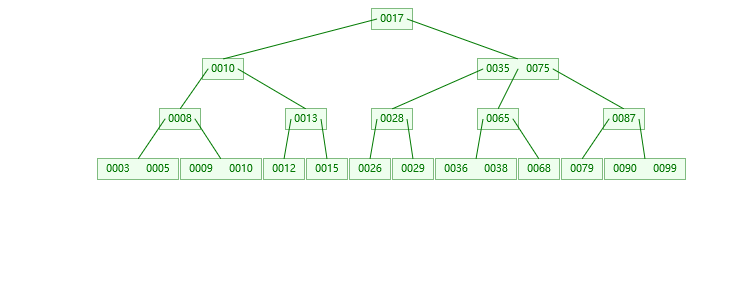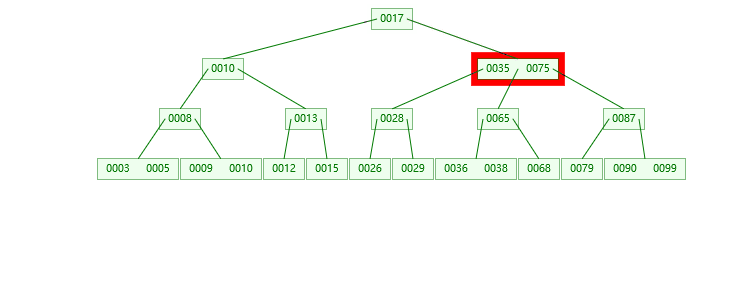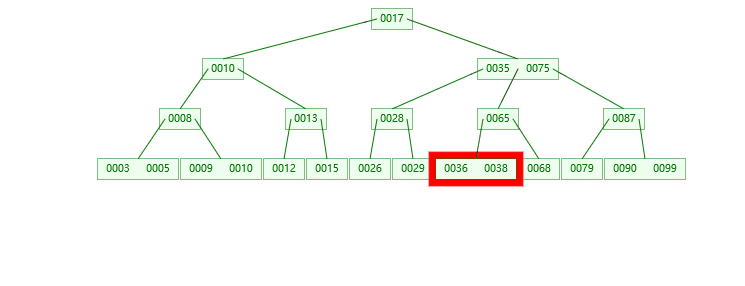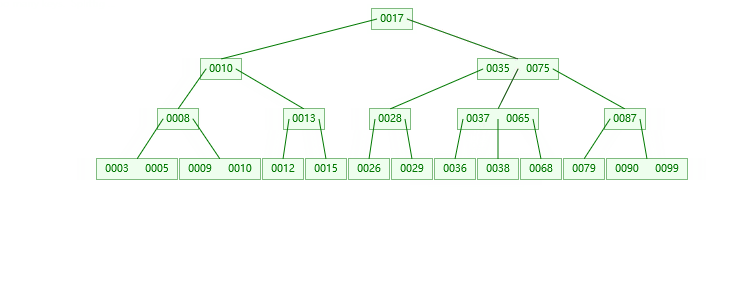
3.插入39的情况
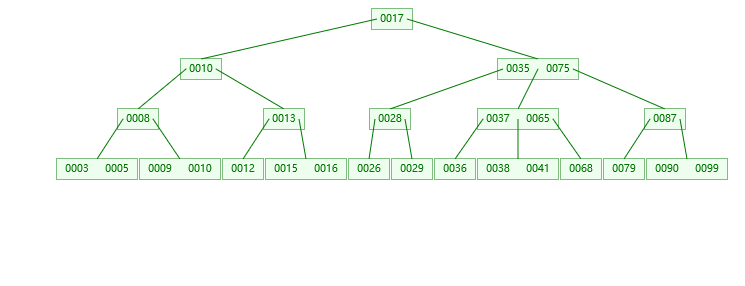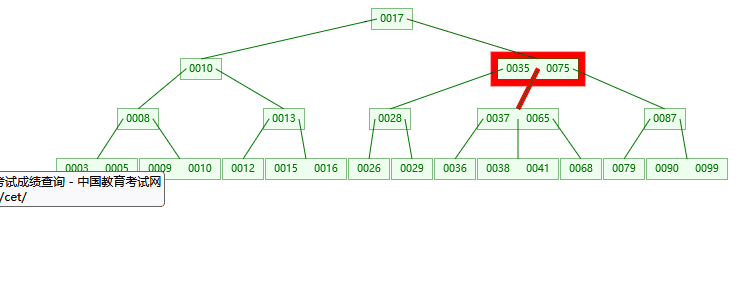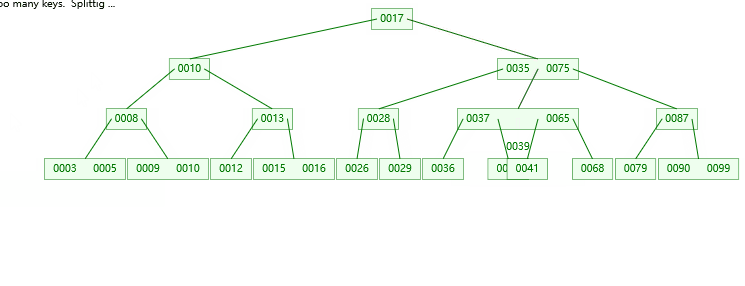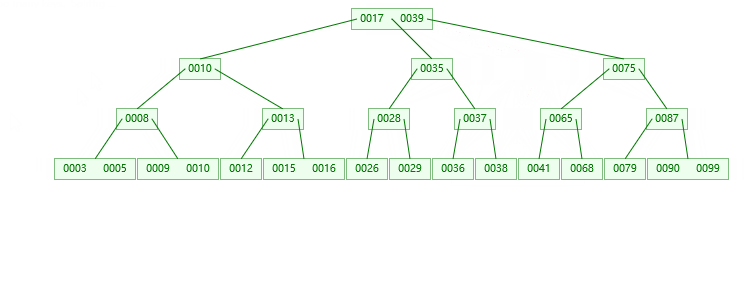
第一步:检索key插入的节点位置如上图所示
第二步:判断节点中的关键码个数:
第三步:结点分裂:
确保B树是一个自平衡的树
删除
树中关键字的删除比插入更复杂。在B树上删除关键字k的过程分两步完成:
(1)找出该关键字所在的结点。然后根据 k所在结点是否为叶子结点有不同的处理方法。
(2)若该结点为非叶结点,且被删关键字为该结点中第i个关键字key[i],则可从指针son[i]所指的子树中
找出最小关键字Y,代替key[i]的位置,然后在叶结点中删去Y。
因此,把在非叶结点删除关键字k的问题就变成了删除叶子结点中的关键字的问题了。
在B-树叶结点上删除一个关键字的方法:
首先将要删除的关键字 k直接从该叶子结点中删除。然后根据不同情况分别作相应的处理,共有三种可能情况:
(1)如果被删关键字所在结点的原关键字个数n>=ceil(m/2),说明删去该关键字后该结点仍满足B树的定义。
这种情况最为简单,只需从该结点中直接删去关键字即可。
(2)如果被删关键字所在结点的关键字个数n等于ceil(m/2)-1,说明删去该关键字后该结点将不满足B树的定义,
需要调整。
调整过程为:
如果其左右兄弟结点中有“多余”的关键字,即与该结点相邻的右(左)兄弟结点中的关键字数目大于
ceil(m/2)-1。则可将右(左)兄弟结点中最小(大)关键字上移至双亲结点。而将双亲结点中小(大)于该上
移关键字的关键字下移至被删关键字所在结点中。
如果左右兄弟结点中没有“多余”的关键字,即与该结点相邻的右(左)兄弟结点中的关键字数目均等于
ceil(m/2)-1。这种情况比较复杂。需把要删除关键字的结点与其左(或右)兄弟结点以及双亲结点中分割二者
的关键字合并成一个结点,即在删除关键字后,该结点中剩余的关键字加指针,加上双亲结点中的关键字Ki一起,
合并到Ai(是双亲结点指向该删除关键字结点的左(右)兄弟结点的指针)所指的兄弟结点中去。如果因此使双亲
结点中关键字个数小于ceil(m/2)-1,则对此双亲结点做同样处理。以致于可能直到对根结点做这样的处理而使
整个树减少一层。
是不是感觉有点晕乎乎的,我们直接看例子吧
- 叶子结点:删90节点

- 叶子结点:删12节点
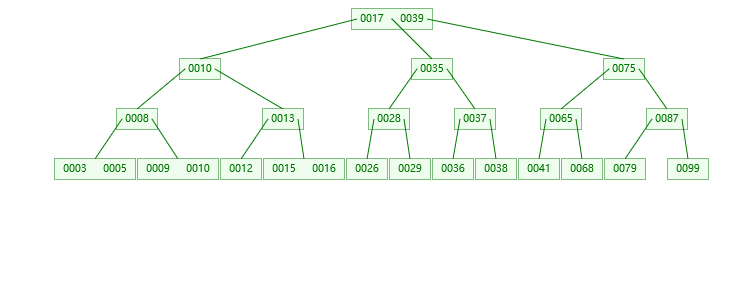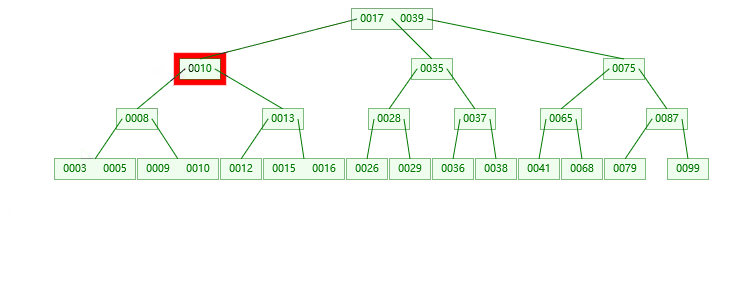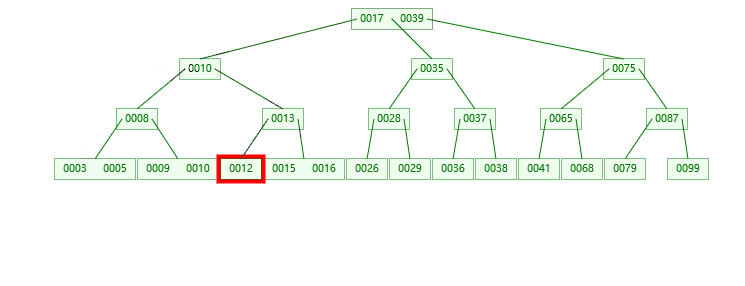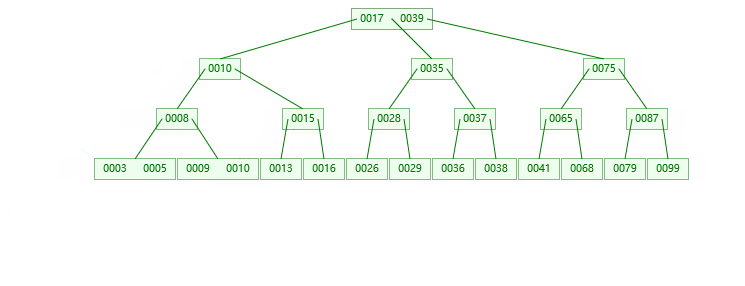
3. 叶子结点:删79节点

4. 非叶子节点:删17(找她左子树的最大值,或者有字数的最小值替代)

- 非叶子节点:删65(都是找替死鬼)

删39
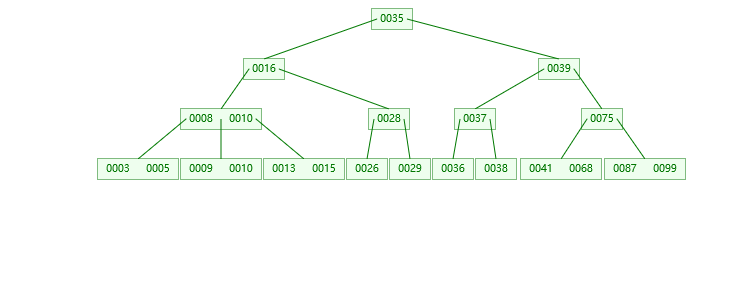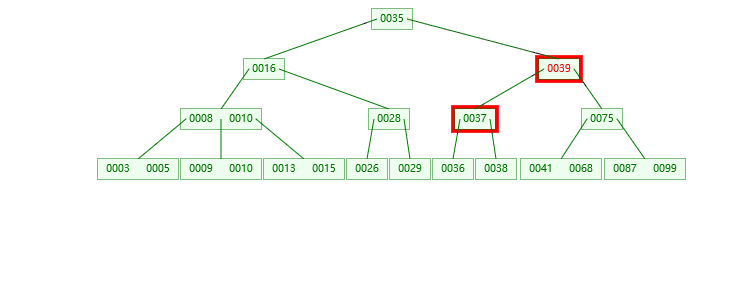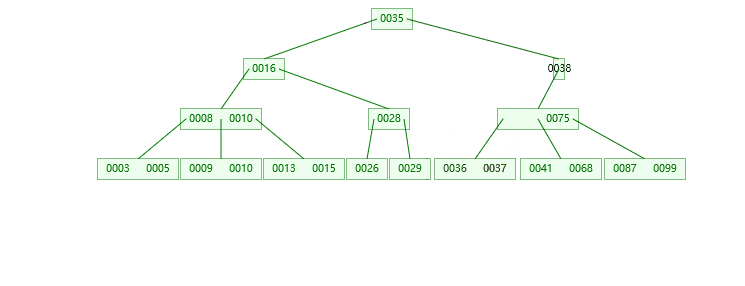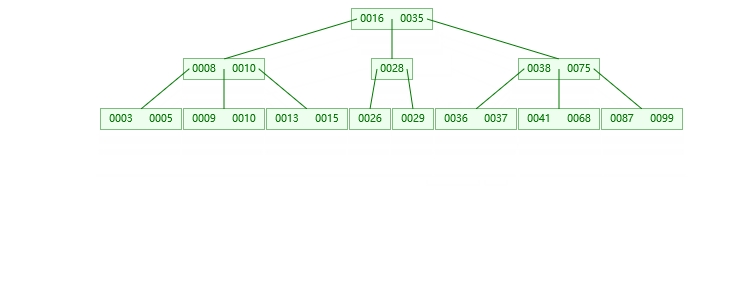
最后给大家演示一下插入和删除数据从1-30的四阶B树

B+ 树
B+树是B树的变种,有着比B树更高的查询效率。下面,我们就来看看B+树和B树有什么不同
特点
一个m阶的B+树具有如下几个特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据
都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小
自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。

查找
B+树的优势在于查找效率上,下面我们做一具体说明:
首先,B+树的查找和B树一样,类似于二叉查找树。起始于根节点,自顶向下遍历树,选择其分离值在要查找值的任意一边的子指针。在节点内部典型的使用是二分查找来确定这个位置。
(1)、不同的是,B+树中间节点没有数据(索引元素所指向的数据记录),只有索引,而B树每个结点中的每个关键字都有数据;这就意味着同样的大小的磁盘页可以容纳更多节点元素,在相同的数据量下,B+树更加“矮胖”,IO操作更少

需要补充的是,在数据库的聚集索引(Clustered Index)中,叶子节点直接包含一行的所有数据。在非聚集索引(NonClustered Index)中,叶子节点(他的key是该索引字段)带有指向卫星数据的指针。
注:该图片引自黑马程序员的mysql课件。
https://www.bilibili.com/video/BV1Kr4y1i7ru/?spm_id_from=333.999.0.0
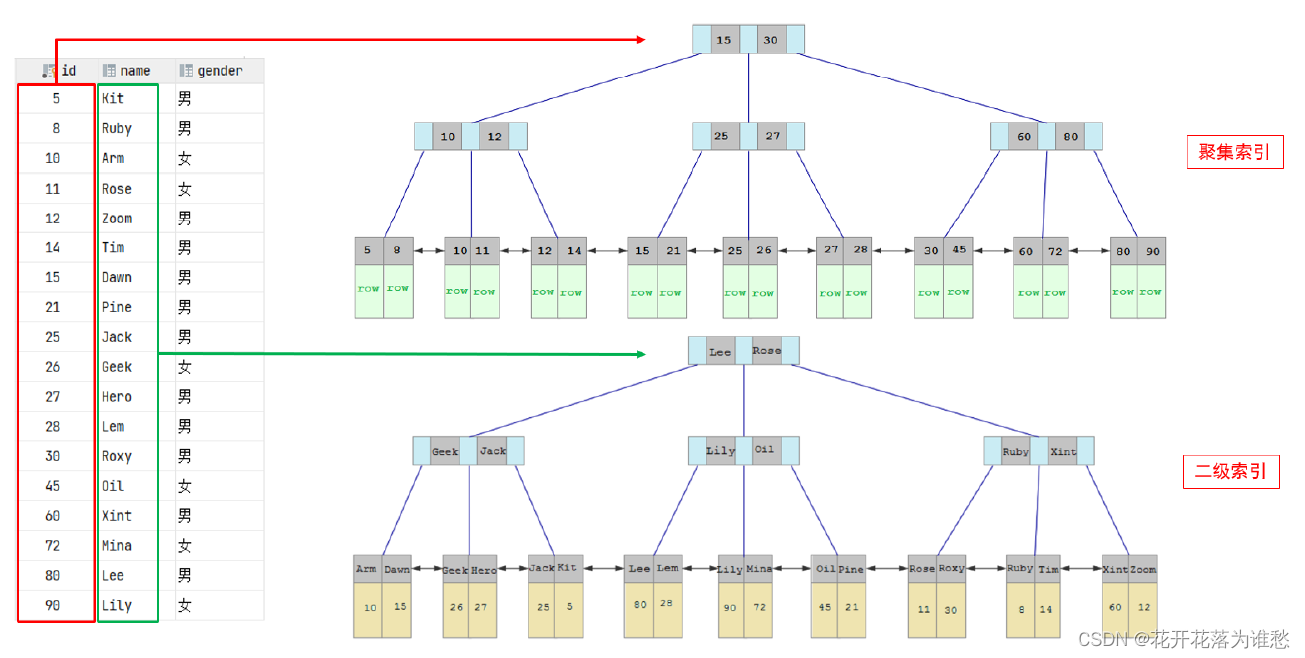
(2)、其次,因为卫星数据的不同,导致查询过程也不同;B树的查找只需找到匹配元素即可,最好情况下查找到根节点,最坏情况下查找到叶子结点,所说性能很不稳定,而B+树每次必须查找到叶子结点,性能稳定
(3)、在范围查询方面,B+树的优势更加明显
B树的范围查找需要不断依赖中序遍历。首先二分查找到范围下限,在不断通过中序遍历,知道查找到范围的上限即可。整个过程比较耗时。
而B+树的范围查找则简单了许多。首先通过二分查找,找到范围下限,然后同过叶子结点的链表顺序遍历,直至找到上限即可,整个过程简单许多,效率也比较高。
例如:同样查找范围[3-11],两者的查询过程如下:
B树的查找过程:


插入
B+树的插入与B树的插入过程类似。不同的是B+树在叶结点上进行,如果叶结点中的关键码个数超过m,就必须分裂成关键码数目大致相同的两个结点,并保证上层结点中有这两个结点的最大关键码。
删除
B+树中的关键码在叶结点层删除后,其在上层的复本可以保留,作为一个”分解关键码”存在,如果因为删除而造成结点中关键码数小于ceil(m/2),其处理过程与B-树的处理一样。在此,我就不多做介绍了。
面试题:b树如何保证线程中数据的安全
1.B+树的方案:锁子树,如果要 锁a到b的数据,以a和b一层一层往下走最后锁到链表中[a,b]中的数据。
1.B树的方案:锁子树,因为他不是叶子结点存储数据,所以最好锁住他的子树或者节点,效率比B+树小很多。
总结
B+树相比B树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少;
2.所有查询都要查找到叶子节点,查询性能稳定;
3.所有叶子节点形成有序链表,便于范围查询。
补充:B树的范围查找用的是中序遍历,而B+树用的是在链表上遍历。















 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









