







Tesseract-OCR是一个文本识别的开源项目。本人使用下来。感觉英文识别很高。中文识别不是很高。需要进行中文训练。识别率会有所提升
使用环境 mac os 10.11.6
1、首先安装 tesseract(已经安装,跳过此步骤)
brew install --with-training-tools tesseract
2、下载chi_sim中文简体语言库
Tesseract-OCR默认是识别英文的。如果需要识别中文需要。需要网上下载一个中文语言库chi_sim.traineddata
3、识别文本图片
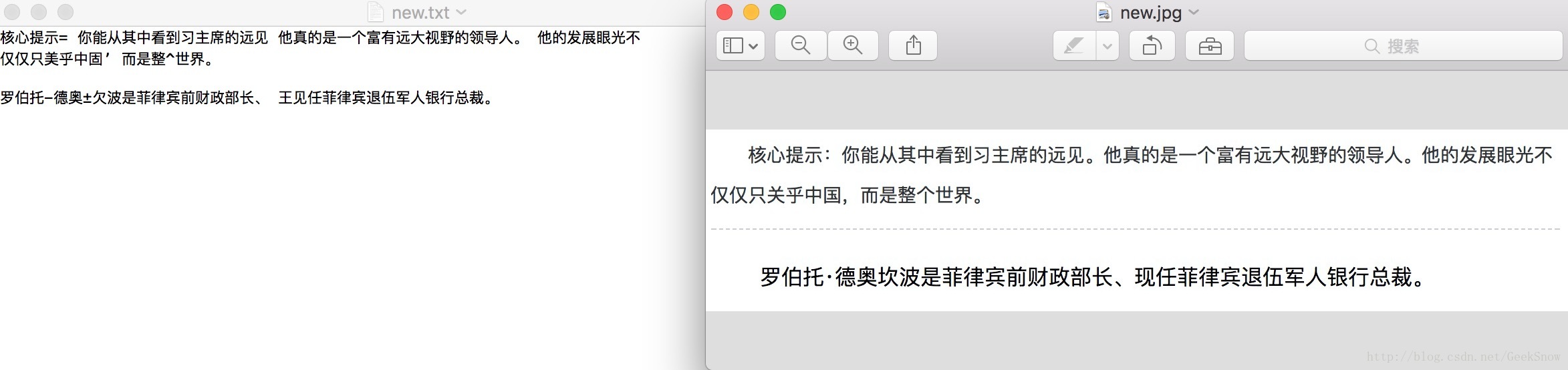
网上随便截取一张图片保存到本地jpg格式。进入目录执行
tesseract new.jpg -l chi_sim new会在当前目录生成一个new.text文件。那么此文件就是图片识别出来的文本内容。其中有些文字会识别不出来。则需要进行中文训练
如图:















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









