




 本文详细介绍了ASCII编码,包括基本ASCII码和扩展ASCII码,以及它们的二进制表示。接着讨论了Unicode编码,特别是UTF-8编码方式,强调其变长编码特性。还提供了Python和Golang中判断Unicode字符是否为汉字的方法。
本文详细介绍了ASCII编码,包括基本ASCII码和扩展ASCII码,以及它们的二进制表示。接着讨论了Unicode编码,特别是UTF-8编码方式,强调其变长编码特性。还提供了Python和Golang中判断Unicode字符是否为汉字的方法。
目录
ASCII编码
- 将0000 0000 ~ 0111 1111编码成英文与一些控制字符,
- ASCII 码使用指定的 7 位或 8 位二进制数组合来表示 128 或 256 种可能的字符。标准 ASCII 码也叫基础ASCII码,使用 7 位二进制数来表示所有的大写和小写字母,数字 0 到 9、标点符号, 以及在美式英语中使用的特殊控制字符。
- 在标准ASCII中,其最高位用作奇偶校验位。
- 所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。奇校验规定:正确的代码一个字节中 1 的个数必须是奇数,若非奇数,则在最高位 添1;偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位添1。
- 后128个称为扩展ASCII码,目前许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展 ASCII 码允许将每个字符的第 8 位用于确定附加的 128 个特殊符号字符、外来语字母和图形符号。
ASCII码表
| ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | ” | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | / | 124 | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ~ |
| 31 | US | 63 | ? | 95 | — | 127 | DEL |
扩展
| 十进制 | 十六进制 | 字符 | 十进制 | 十六进制 | 字符 |
| 128 | 80 | Ç | 192 | C0 | └ |
| 129 | 81 | ü | 193 | C1 | ┴ |
| 130 | 82 | é | 194 | C2 | ┬ |
| 131 | 83 | â | 195 | C3 | ├ |
| 132 | 84 | ä | 196 | C4 | ─ |
| 133 | 85 | à | 197 | C5 | ┼ |
| 134 | 86 | å | 198 | C6 | ╞ |
| 135 | 87 | ç | 199 | C7 | ╟ |
| 136 | 88 | ê | 200 | C8 | ╚ |
| 137 | 89 | ë | 201 | C9 | ╔ |
| 138 | 8A | è | 202 | CA | ╩ |
| 139 | 8B | ï | 203 | CB | ╦ |
| 140 | 8C | î | 204 | CC | ╠ |
| 141 | 8D | ì | 205 | CD | ═ |
| 142 | 8E | Ä | 206 | CE | ╬ |
| 143 | 8F | Å | 207 | CF | ╧ |
| 144 | 90 | É | 208 | D0 | ╨ |
| 145 | 91 | æ | 209 | D1 | ╤ |
| 146 | 92 | Æ | 210 | D2 | ╥ |
| 147 | 93 | ô | 211 | D3 | ╙ |
| 148 | 94 | ö | 212 | D4 | Ô |
| 149 | 95 | ò | 213 | D5 | ╒ |
| 150 | 96 | û | 214 | D6 | ╓ |
| 151 | 97 | ù | 215 | D7 | ╫ |
| 152 | 98 | ÿ | 216 | D8 | ╪ |
| 153 | 99 | Ö | 217 | D9 | ┘ |
| 154 | 9A | Ü | 218 | DA | ┌ |
| 155 | 9B | ¢ | 219 | DB | █ |
| 156 | 9C | £ | 220 | DC | ▄ |
| 157 | 9D | ¥ | 221 | DD | ▌ |
| 158 | 9E | ? | 222 | DE | ? |
| 159 | 9F | ƒ | 223 | DF | ? |
| 160 | A0 | á | 224 | E0 | α |
| 161 | A1 | í | 225 | E1 | ß |
| 162 | A2 | ó | 226 | E2 | Γ |
| 163 | A3 | ú | 227 | E3 | π |
| 164 | A4 | ñ | 228 | E4 | Σ |
| 165 | A5 | Ñ | 229 | E5 | σ |
| 166 | A6 | ª | 230 | E6 | µ |
| 167 | A7 | º | 231 | E7 | τ |
| 168 | A8 | ¿ | 232 | E8 | Φ |
| 169 | A9 | ? | 233 | E9 | Θ |
| 170 | AA | ¬ | 234 | EA | Ω |
| 171 | AB | ½ | 235 | EB | δ |
| 172 | AC | ¼ | 236 | EC | ∞ |
| 173 | AD | ¡ | 237 | ED | φ |
| 174 | AE | « | 238 | EE | ε |
| 175 | AF | » | 239 | EF | ∩ |
| 176 | B0 | ? | 240 | F0 | ≡ |
| 177 | B1 | ? | 241 | F1 | ± |
| 178 | B2 | ▓ | 242 | F2 | ≥ |
| 179 | B3 | │ | 243 | F3 | ≤ |
| 180 | B4 | ┤ | 244 | F4 | ? |
| 181 | B5 | ╡ | 245 | F5 | ? |
| 182 | B6 | ╢ | 246 | F6 | ÷ |
| 183 | B7 | ╖ | 247 | F7 | ≈ |
| 184 | B8 | ╕ | 248 | F8 | ≈ |
| 185 | B9 | ╣ | 249 | F9 | ? |
| 186 | BA | ║ | 250 | FA | · |
| 187 | BB | ╗ | 251 | FB | √ |
| 188 | BC | ╝ | 252 | FC | ? |
| 189 | BD | ╜ | 253 | FD | ² |
| 190 | BE | ╛ | 254 | FE | ■ |
| 191 | BF | ┐ | 255 | FF | ÿ |
unicode
-
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
-
UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
-
其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。
-
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8编码
由于ASCII编码表示的字符太少了,所以各个国家都有一套自己的编码标准,比如中国的GB2312、GBK编码等。但是如果每个国家都用自己的标准,那么交流起来就很复杂,所以ISO组织就发明了UNICODE编码,UTF-8(每次传输8位)是UNICODE的一种,向下可兼容ASCII编码。
# 序列0开头表示兼容ASCII编码
00 - 7F:0xxxxxxx
# 序列110开头表示是两个字节编码的
80 - 7FF:110xxxxx 10xxxxx
# 序列1110开头表示是三个字节编码的
800 - FFFF:1110xxxx 10xxxxxx 10xxxxxx
# 序列11110开头表示是四个字节编码的
10000 - 10FFFF:11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
序列10开头表示是编码字节的组成部分
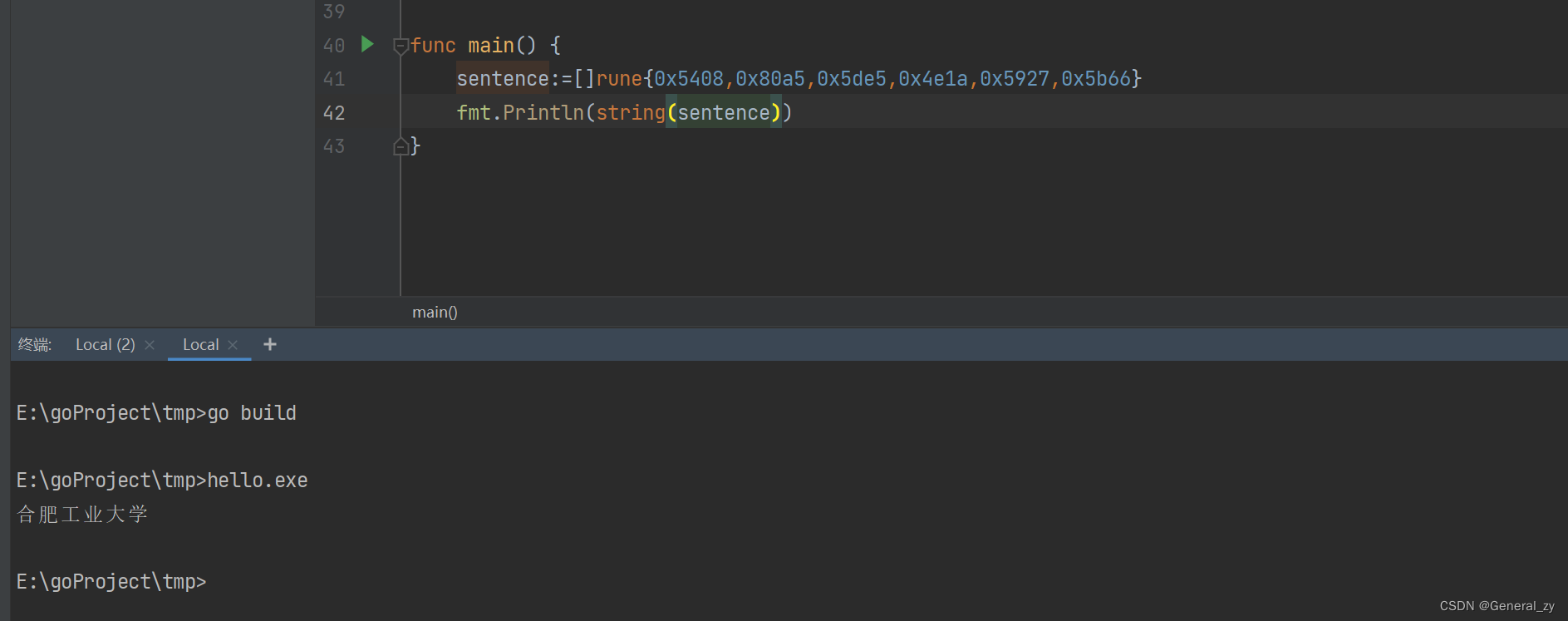
实例:utf8转中文
# 给出字节序列如下
11100101 10010000 10001000 11101000 10000010
10100101 11100101 10110111 10100101 11100100
10111000 10011010 11100101 10100100 10100111
11100101 10101101 10100110
# 由于开头都是1110组成,所以都是由三个字节编码的
0101 010000 001000
1000 000010 100101
0101 110111 100101
0100 111000 011010
0101 100100 100111
0101 101101 100110
# 16进制
0101 0100 0000 1000 -> 0x5408
1000 0000 1010 0101 -> 0x80a5
0101 1101 1110 0101 -> 0x5de5
0100 1110 0001 1010 -> 0x4e1a
0101 1001 0010 0111 -> 0x5927
0101 1011 0110 0110 -> 0x5b66
对应utf8表即可(utf8表过长,不再展示)
python 2.7 如何判断 Unicode 编码字符是否为汉字,如何判断unicode编码句子中是否含有汉字
对于计算机来说,一切都是 0 1 组成的数字,汉字也不例外。因此对于 python 来说,汉字也是可以比较大小的,所以,判断一个 unicode字符是否汉字,只需要判断该字符是否在第一个汉字和最后一个汉字之间即可。
查阅资料,发现对于Unicode编码的汉字,最小为\u4e00,最大为 \u9fa5,所以,自然的,python 判断一个Unicode字符是否为汉字的代码可以如下写:
def IsChineseChar(uchar):
if uchar >= u'\u4e00' and uchar<=u'\u9fa5':
return True
return False
测试:
print IsChineseChar(u'A'), IsChineseChar(u'我')
发现符合预期:
# python t.py
False True
进一步的,如果想用python判断一句unicode编码的话中是否含有中文,代码可以如下写:
def IsChineseCharInside(sentence):
for uchar in sentence:
if uchar >= u'\u4e00' and uchar<=u'\u9fa5':
return True
return False
Golang中对是否是中文字符的判断方法
方法一
首先是用到的两个函数(截图来自 - Go语言中文网 https://studygolang.com/pkgdoc)

接下来是代码:
package main
import (
"fmt"
"regexp"
)
//注释解释的是上一行的代码
func main() {
str := "!@#中国123"
//设定一个含有中文的字符串
var a = regexp.MustCompile("^[\u4e00-\u9fa5]$")
//接受正则表达式的范围
for i, v := range str {
//golang中string的底层是byte类型,所以单纯的for输出中文会出现乱码,这里选择for-range来输出
if a.MatchString(string(v)) {
//判断是否为中文,如果是返回一个true,不是返回false。这俩面MatchString的参数要求是string
//但是 for-range 返回的 value 是 rune 类型,所以需要做一个 string() 转换
fmt.Printf("str 字符串第 %v 个字符是中文。是“%v”字\n", i+1, string(v))
}
}
}
方法二
go的unicode编码库里面已经内置了判断方法:
func IsContains(str string) bool {
for _, v := range str {
// 判断当前字符是否是Han
if unicode.Is(unicode.Han, v) {
return True
}
}
return False
}


















 2258
2258

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











