







Hadoop 2.x部署
*local Mode
*Distributed Mode
*伪分布式
一台机器,运行所有的守护进程
从节点DataNode、NodeManager
*完全分布式
有多个从节点
DataNodes
NodeManagers
配置文件
$HADOOP_HOME/etc/hadoop/slaves
1. 基于伪分布式安装
三台机器
192.168.113.132
Hadoop-senior01
1.5G
1CPU
192.168.113.133
Hadoop-senior02
1G
1CPU
192.168.113.134
Hadoop-senior03
1G
1CPU
Hadoop克隆之后应做的步骤:

vi /etc/udev/rules.d/70-persistent-net.rules
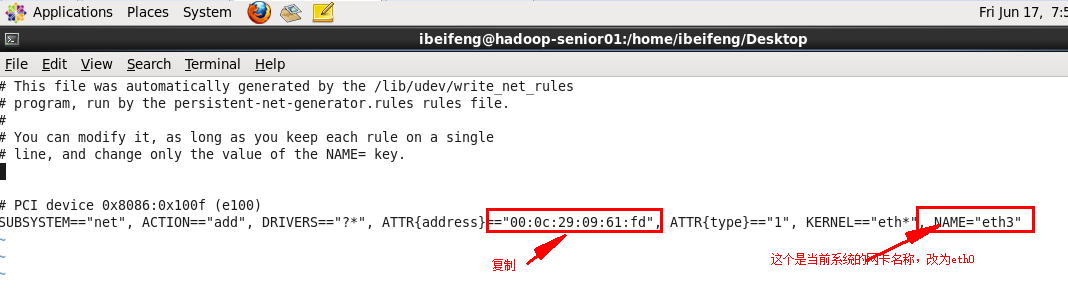
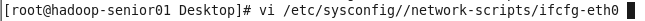
vi /etc/sysconfig/network-scripts/ifcfg-eth0
重新启动虚拟机,然后从桌面修改静态IP地址

sudo vi /etc/resolv.conf
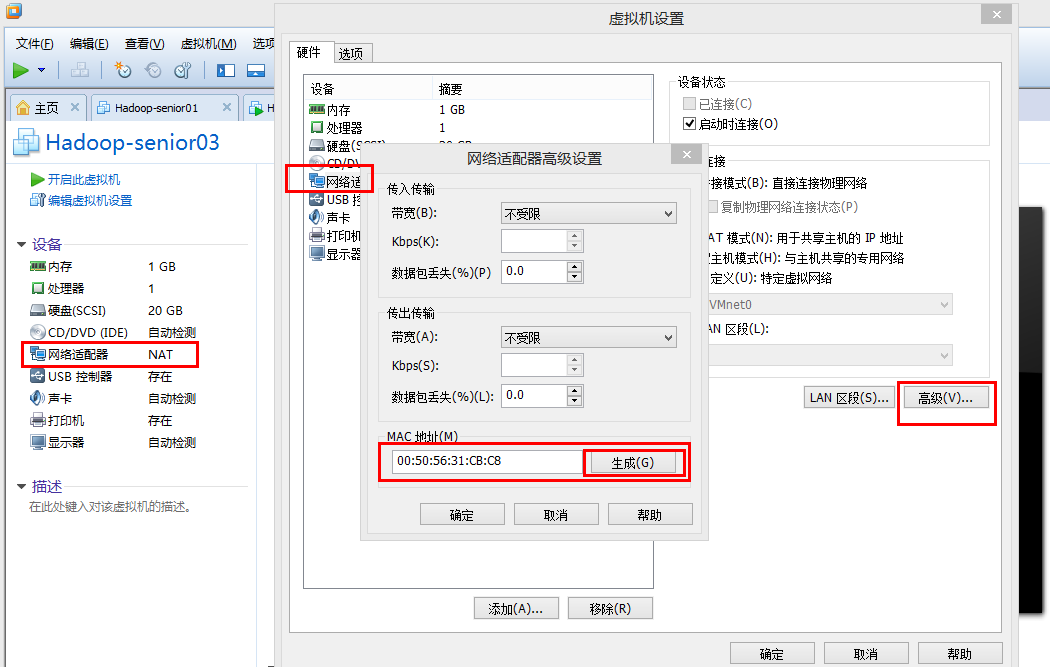
如果是复制而非克隆虚拟机需要:
重新生成Make码
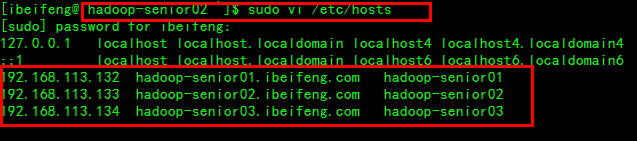
每个虚拟机都要写这三个
192.168.113.132 hadoop-senior01.ibeifeng.com hadoop-senior01
192.168.113.133 hadoop-senior02.ibeifeng.com hadoop-senior02
192.168.113.134 hadoop-senior03.ibeifeng.com hadoop-senior03
* 建议:*
如下两个地方进行配置映射
1)集群的各个机器
2)所有的客户端机器
hosts
创建用户:
ibeifeng
创建目录
软件安装
基本设置
关闭防火墙
禁用SELINUX=disable
卸载OpenJDK
时间同步
各个机器的时间一致
方式很多种:
1、联网情况下:
与网络标准时间进行同步
2、内网情况下
至少我可以保证集群的所有时间是同步的
集群时间同步
>> 找一台机器作为时间服务器
hadoop-senior01.ibeifeng.com
具体步骤如下:
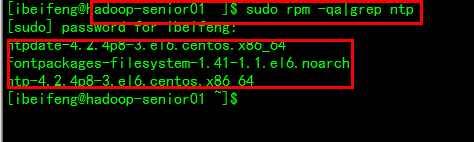
1) 查看时间服务器是否安装
sudo rpm -qa|grep ntp
2) 启动时间服务器
sudo service ntpd status
sudo service ntpd start
永久启动
sudo chkconfig ntpd on
3)配置:
$sudo vi /etc/ntp.conf
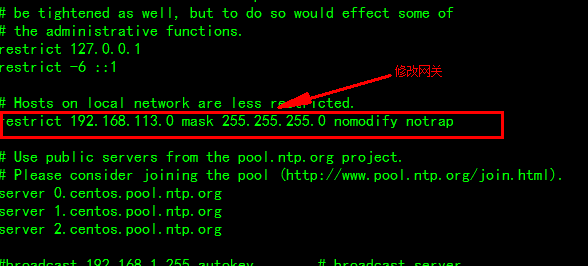
修改如下:
第一处:去掉注释,修改网段
第二处:增加注释
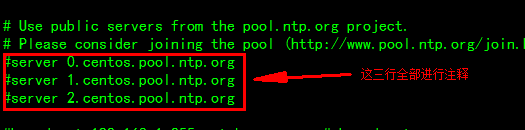
第三处:去掉注释

4)设置系统时间与bois时间一致
打开配置文件,首行加入


》》》集群中其他机器,定时与时间服务器进行同步时间
定时任务crontab
每台机器,每十分钟与机器进行同步
0-59/10 * * * * /usr/sbin/ntpdate ntpdate hadoop-senior01.ibeifeng.com
对第三台机器同样进行设置
调整与第一台时间的同步

建立crontab定时任务


2、规划机器与服务
在分布式环境下,所有的安装目录要相同
Hadoop-senior01 Hadoop-senior02 Hadoop-senior03
HDFS
NameNode
DataNodes DataNodes DataNode
SecondaryNode
YARN
ResourceManager
NodeManager NodeManager NodeManager
MapReduce
JobHistoryServer
3、修改配置文件,设置服务运行机器节点
*hdfs
NameNode
DataNode
SNN
*hadoop-env.sh
*core-site.xml
*hdfs-site.xml
*slaves
*yarn
ResourceManager
NodeManager
*yarn-env.sh
*yarn-site.xml
*slaves
*mapreduce
JobHistoryServer
*mapred-env.sh
*mapred-site.xml
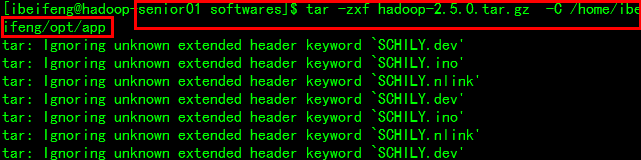
配置Hadoop文件Hadoop-senior01
解压Hadoop文件到固定目录下(三台机器的目录相同)
将原来Hadoop-senior01中配置好的Hadoop文件拷贝到新的etc/hadoop目录下

配置hdfs文件
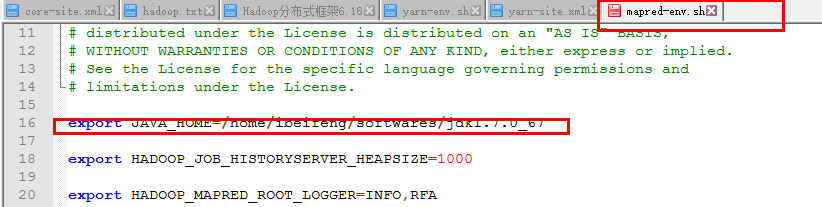
1)在Hadoop-env.sh中配置JDK
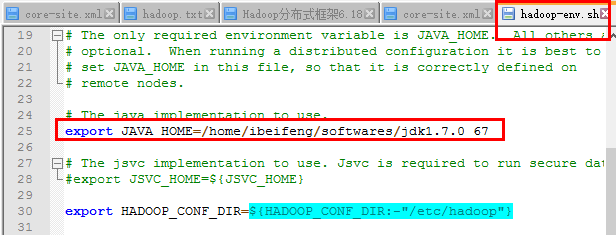
2)在core-site.xml中配置
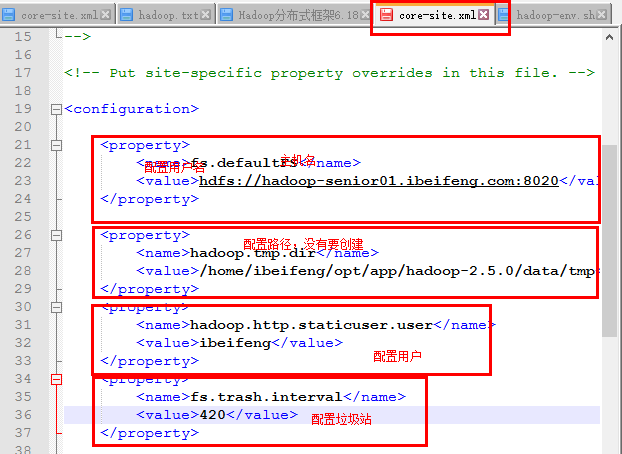
3)在hdfs-site.xml上配置
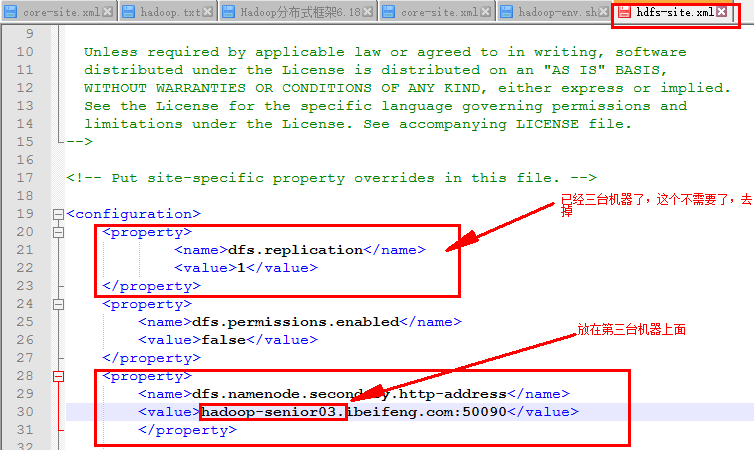
4)在slaves上配置

配置yarn文件
1)在yarn-env.sh配置环境变量
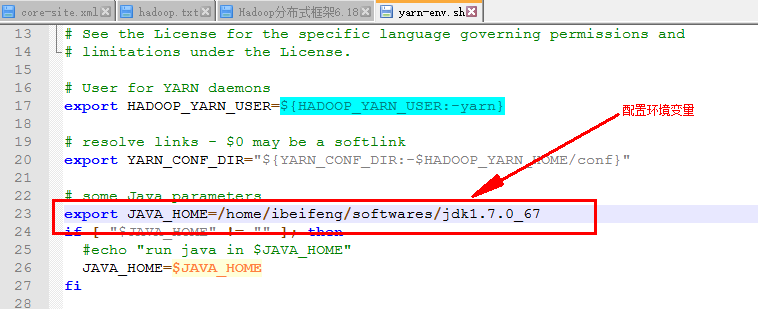
2)在yarn-site.xml上配置
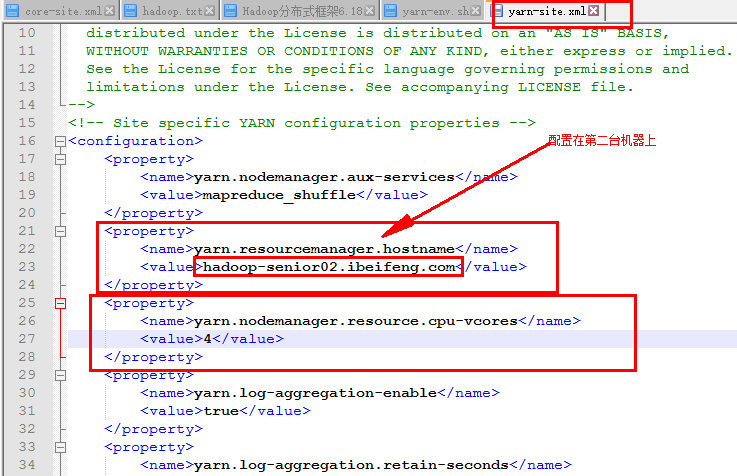
配置mapreduce文件
1)在mapred-env.sh上配置文件
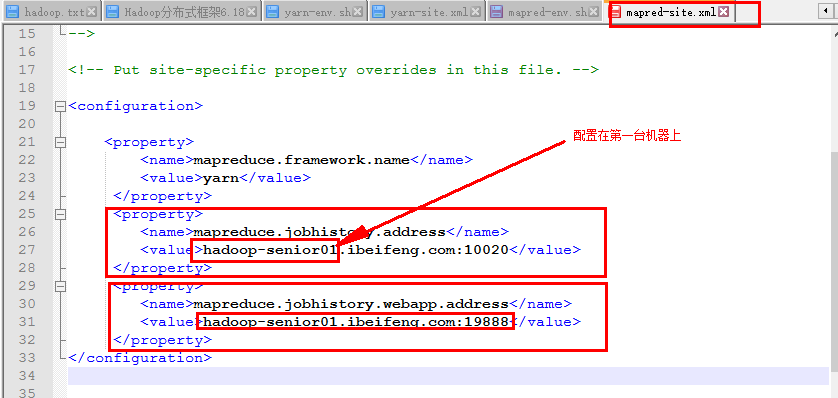
2)在mapred-site.xml上配置
4、分发HADOOP安装包至各个机器节点
ssh无密码登录配置

把密钥拷贝到另外两台机器上
远程连接成功

分发:

scp -r hadoop-2.5.0/ hadoop-senior02.ibeifeng.com:/home/ibeifeng/opt/app
SSH无密码登录总结:
HDFS
start-dfs.sh
主节点上NameNode
SSH无密钥登录
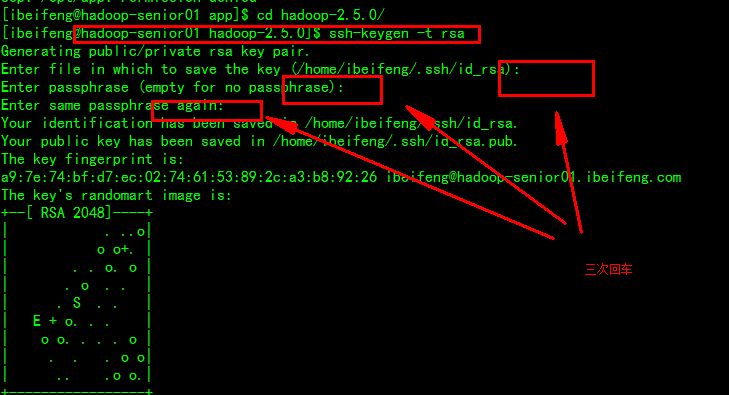
》》生成一对公钥和私钥
$ssh-keygen -t rsa
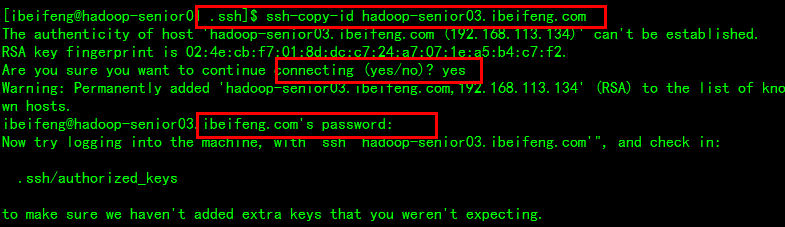
》》拷贝公钥到各个机器上
$ssh-copy-id hadoop-senior01.ibeifeng.com
$ssh-copy-id hadoop-senior02.ibeifeng.com
$ssh-copy-id hadoop-senior03.ibeifeng.com
》》ssh连接测试
$ssh hadoop-senior01.ibeifeng.com
$ssh hadoop-senior02.ibeifeng.com
$ssh hadoop-senior03.ibeifeng.com
YARN
start-yarn.sh
主节点:resourcemanager
5、启动服务组件进行测试
*启动
>>HDFS
1、HDFS的格式化
在NameNode所在的机器上进行格式

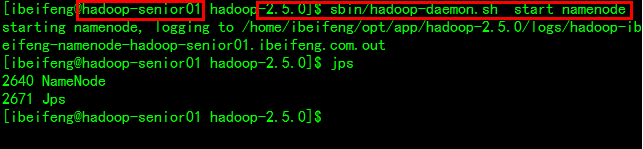
启动namenode
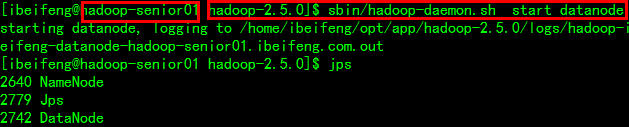
启动datanode


测试
创建用户主目录
bin/hdfs dfs -mkdir -p mapreduce/wordcount/input
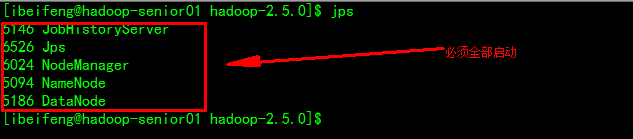
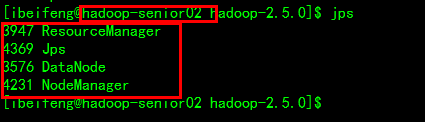
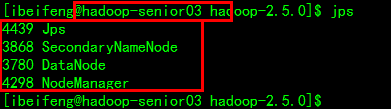
*测试
$ sbin/hadoop-daemon.sh start namenode
$ sbin/hadoop-daemon.sh start datanode
$ sbin/yarn-daemon.sh start resourcemanager
$ sbin/yarn-daemon.sh start nodemanager
$ sbin/mr-jobhistory-daemon.sh start historyserver















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









