






还是先从API文档的介绍看起:

Map:
1、一次添加一对元素,Collection一次添加一个元素
2、存储键(可理解为关键字)值对
3、每个键是唯一的
因为Map集合和Collection存储的数据形式是不同的,所以Map集合相应操作元素的方法和Collection集合会有所不同,接下来会列出来Map与Collection集合不同的而值得注意的方法。
Map集合
添加方法是:V put(Key, Value)
返回以前与 key 关联的值,如果没有返回null。
删除:V remove(Key)
如果存在一个键的映射关系,则将其从此映射中移除,返回以前与 key 关联的值;
如果没有 key 的映射关系,则返回 null。
判断: boolean containsKey(Key)
Boolean containsValue(Value)
获取:
Value get(Key):通过键获取值,如果没有则返回null。
这个方法可以与List集合E get(index)做个比较,
List集合是通过角标(索引)来确定元素所在位置后,
然后将该位置的元素取出,Map集合有点类似但有着本质的区别,
Map集合先将找到对应的键值,然后获取这个键所映射的值。
现在可以做个简单的应用。
定义一个MapTest类具体代码如下:
package com.java.map;
import java.util.HashMap;
import java.util.Map;
public class MapTest {
@SuppressWarnings({ "rawtypes", "unchecked" })
public static void main(String[] args) {
Map map = new HashMap();
//put方法返回以前与Key关联的值,第一次键"1"对应"张三",没有以前的值所以返回为空。
System.out.println(map.put("1", "张三"));
//第二次键"1"对应"赵六",返回以前的值是第一次的"张三",所以输出"张三"
System.out.println(map.put("1", "赵六"));
map.put("2", "李四");
map.put("3", "王五");
System.out.println(map);
for(int i = 1; i < map.size()+1; i++){
System.out.println(map.get(""+i));
}
System.out.println("删除:" + map.remove("1"));
System.out.println(map);
}
}测试结果:
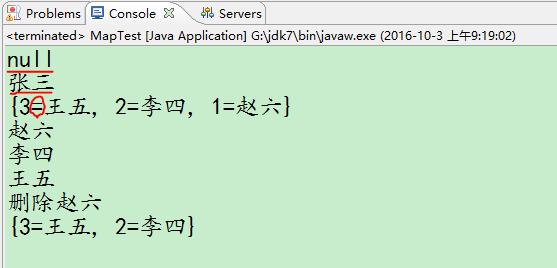
Map集合的输出和Collection集合不同,它是以 {Key=Value,...}形式输出。
上个例子,之所以能够用for循环取值,是因为键值有规律可循,若是,键值没有规律呢,由该如何获取?
接下来开始重点介绍如何获取map中的元素。
第一种方法:通过keySet方法获取map中所有的键所在的集合,
再通过Set的迭代器获取到一个键,再由键获取值。
依然在MapTest中测试,具体代码如下:
Map map = new HashMap();
map.put("1", "张三");
map.put("2", "李四");
map.put("3", "王五");
Set keySet = map.keySet();
Iterator it = keySet.iterator();
while(it.hasNext()){
String key = (String) it.next();
String value = (String) map.get(key);
System.out.println(key + "=" + value);
}测试结果如下:

第二种方法:Map集合的另外一个方法entrySet
该方法将键和值的映射关系作为对象存储到了Set集合中,而其这个映射关系的类型就是Map.Entry类型。
依然在MapTest里做测试,将之前的keySet方法替换为entrySet,具体代码如下:
Set<Map.Entry<String, String>> entrySet = map.entrySet();
Iterator<Map.Entry<String, String>> it = entrySet.iterator();
while(it.hasNext()){
//迭代键值关系对象
Map.Entry<String, String> mapEntry = it.next();
//从键值关系对象获取键
String key = mapEntry.getKey();
//获取值
String value = mapEntry.getValue();
System.out.println(key + "=" + value);
}Map集合常用方法都介绍完了,接下来开始介绍其子类。
HashMap:

HashMap简单测试就不写了,将上面例子
Map map = new HashMap();改为
HashMap hasMap = new HashMap();即可。
TreeMap:

根据定义知道
TreeMap有两种排序:
1、根据键的自然顺序排序
2、根据TreeMap自身的比较器来排序
发现和TreeSet排序方式是一致的。接下来做个简单测试,同样用上Student类。具体代码如下:
package com.java.map;
import java.util.Iterator;
import java.util.Map;
import java.util.TreeMap;
import com.java.entity.Student;
public class TreeMapTest {
public static void main(String[] args) {
TreeMap<Student, String> treeMap = new TreeMap<Student, String>();
treeMap.put(new Student(3, "张三"), "上海");
treeMap.put(new Student(1, "李四"), "北京");
treeMap.put(new Student(2, "王五"), "广州");
Iterator<Map.Entry<Student, String>> it = treeMap.entrySet().iterator();
while(it.hasNext()){
Map.Entry<Student, String> mapEntry = it.next();
Student student = mapEntry.getKey();
String address = mapEntry.getValue();
System.out.println(student + "=" + address);
}
}
}测试结果:
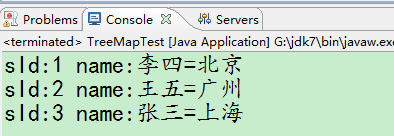
从结果图看出来,是符合要求的,Student类在之前实现了Comparable接口,具备了自然顺序,在compareTo中方法是按照先sId排序后姓名排序,而结果是按照sId排序,所以是正确的。
接下来我们应用比较器,还是用之前定义好的ComparatorByName比较器。
在TreeMap构造方法中添加ComparatorByName对象。
即将
TreeMap<Student, String> treeMap = new TreeMap<Student, String>();改为
TreeMap<Student, String> treeMap = new TreeMap<Student, String>(new ComparatorByName());测试结果如下:

发现TreeMap存储元素是按照Student类的name属性。
至此Java中的集合框架常用的接口和实现类都介绍完。















 8123
8123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









