







300万条记录 count(*) 和 count(字段名)比较
环境:sql2005
数据量:300万
机器环境
P4 3.0双核 1G内存
1. 执行语句
select count(*) from testing
select count(id) from testing
select count(name) from testing
2. 没有 索引的情况下
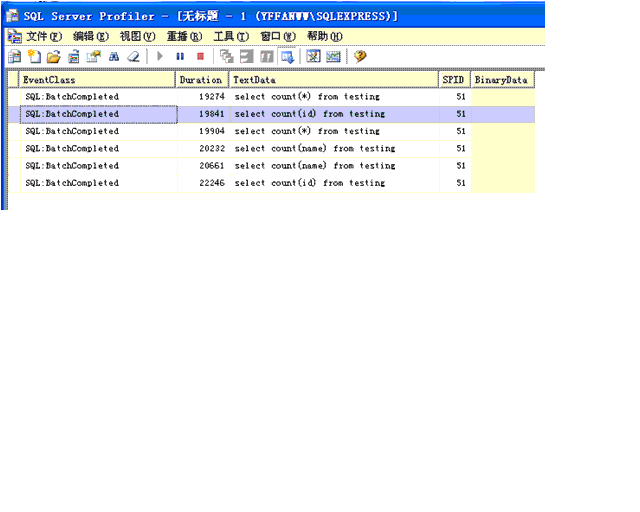
传说中的count(1)性能最差这里没有列出来。
Sql2005中count(*) 性能最高,它会自动的寻找最快的索引。这里给大家一个参考
在数据量过百万时尽量不要使用没有做索引的COUNT()函数来检索数据总数,性能消耗分成大,我将3条语句执行了2遍数据库内存用到300多M。
解决方案:添加索引
3. 为表主键id创建索引后的执行效果如下:
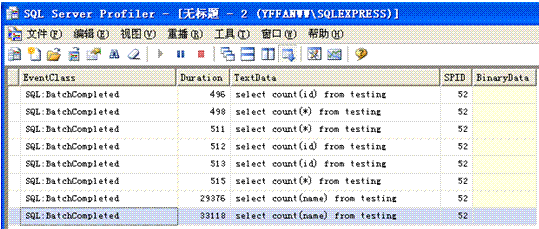
从以上数据可以看出 count(*) 比count(id)扫满一点基本上可以忽略这个就是我上面所讲到的count(*)会自动搜索最开的索引区查询,我们在不知道最快索引时可以使用它是最佳方案,反观count(name)由于name没有加索引所以检索的时间依然很长。
从数据中我们发现第一次执行的时间稍比第二次长点那是因为SQL2005缓存在作怪,如果数据没有任何变动sql会自己到缓存中夺取数据。
总结:
a) 大数据量是使用count函数时需要使用索引来提高性能
b) 在不清楚表中数据最快的索引时什么的时候使用count(*)比较好
c) 在检索的数据没有变更时数据库默认检索缓存中的数据。















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









