







本篇是 LR和GBDT模型训练【放链接】 的附属篇
一、常用库
# -*- coding: UTF-8 -*-
import numpy as np
from numpy import median
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import ray.dataframe as pd_new
%matplotlib inline
sns.set()
二、加载数据
data_feature = ['label','click', .......]
data = pd.read_table('../../data', names=data_feature)
三、数据概览
data.head()
data.info()
data.describe()
data.label.value_counts() #标签每个类别的个数
data.label[data.label.notnull()].count() #不为空的数量
原始数据35列

数据量:3000000
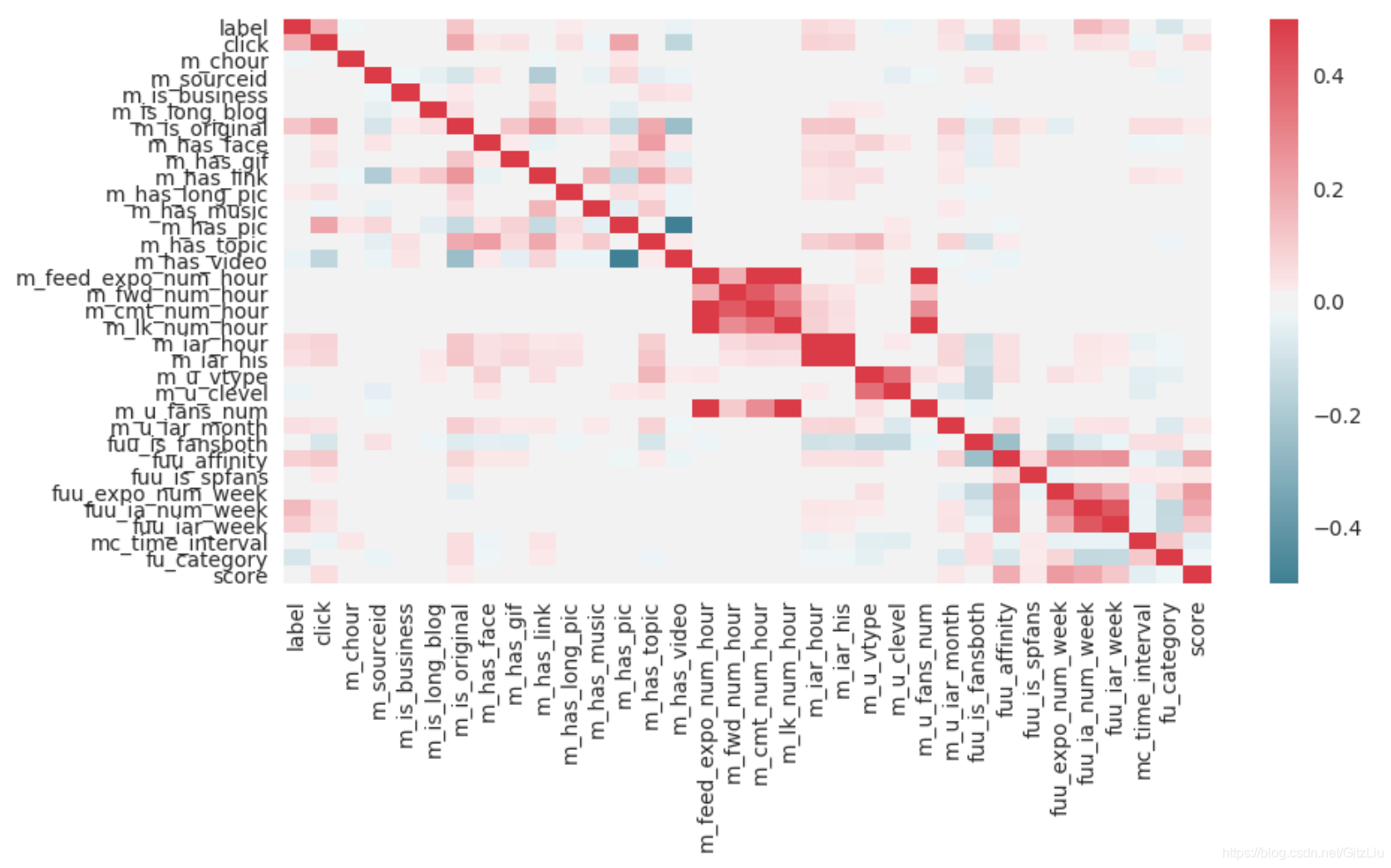
皮尔逊分析
关于皮尔逊分析:【TODO解释】
#皮尔逊分析
fu_feature_corr = data.corr()
plt.figure(figsize=(10,5),dpi=100)
sns.heatmap(fu_feature_corr,
xticklabels=fu_feature_corr.columns,
yticklabels=fu_feature_corr.columns,
cmap=sns.diverging_palette(220, 10, as_cmap=True),
#annot=True,
vmax=0.5, vmin=-0.5
)
四、举例
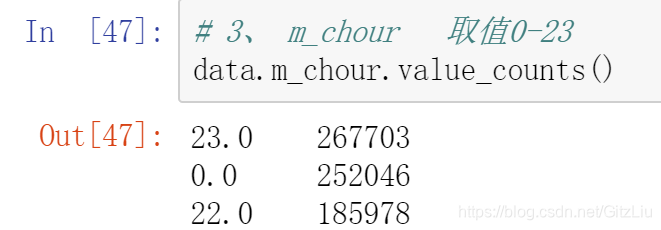
1、m_chour特征
data.m_chour.value_counts() #各个取值的取值数量
data.m_chour[data.m_chour.notnull()].count() #非空行数量

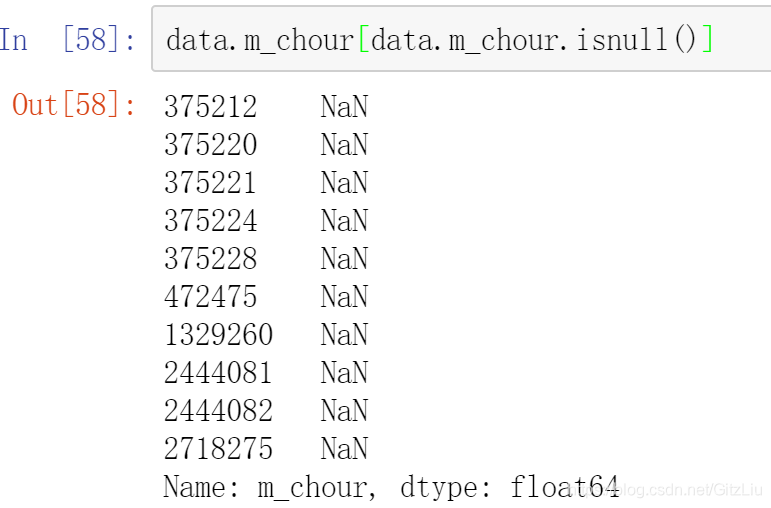
len(data.m_chour[data.m_chour.isnull()].values) # 缺失值数量

data.m_chour[data.m_chour.isnull()] #具体缺失行
data.m_chour.describe() #min 和 max

评价:# m_chour:取值0-23 10个缺失值 # 关于 m_chour缺失值,由于只有10个 建议删除
2、m_u_vtype
这个比较典型:一般对一个特征,要看下面几个方面,得出结论
print (data.m_u_vtype[data.m_u_vtype.notnull()].count()) #非空行数量
print (data.m_u_vtype.value_counts()) #取值情况
data.m_u_vtype[data.m_u_vtype.isnull()] # 缺失值具体行
print(len(data.m_u_vtype[data.m_u_vtype.isnull()].values)) #缺失值行数
data.m_u_vtype.describe() #看最大值和最小值,为什么?
在看完上面几个方面后,如需要,可做图
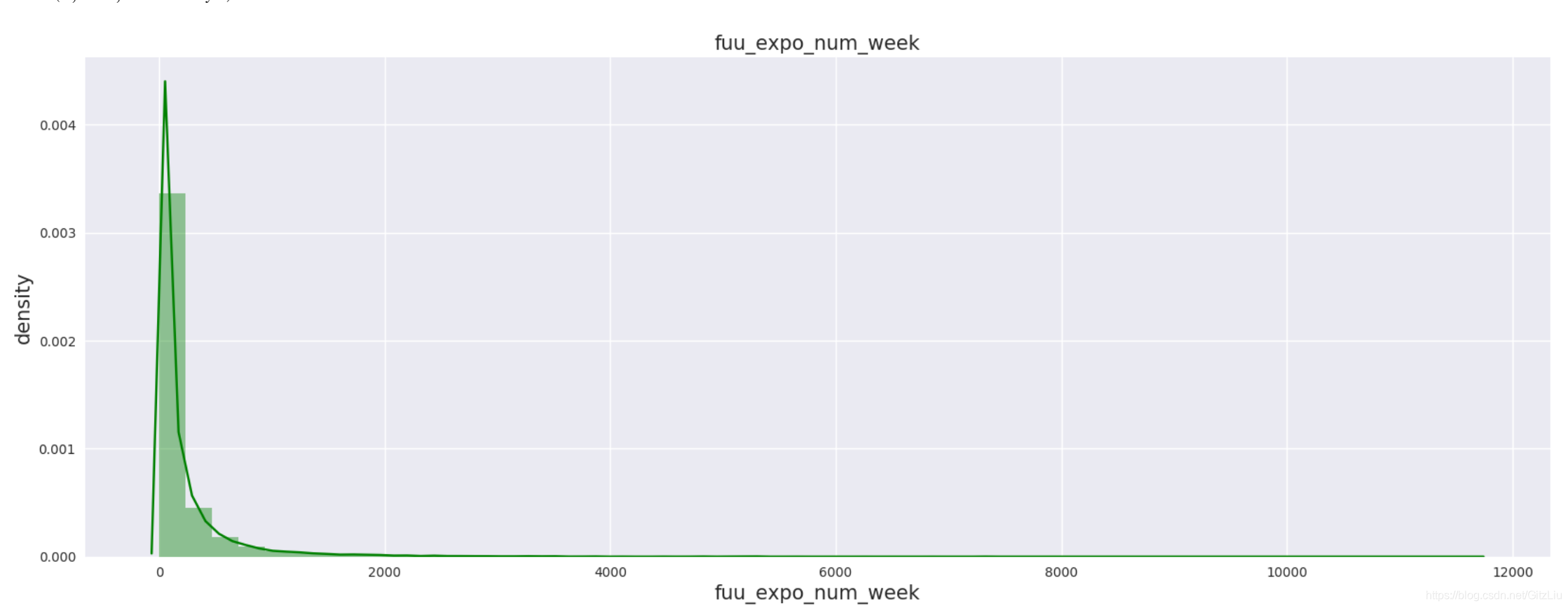
以下面这个特征举例:
(1)从上图可以看到该fuu_expo_num_week 特征,的取值分布情况
#1.5 fuu_expo_num_week
#fuu_data.fuu_expo_num_week.value_counts() #离散值0---n
plt.figure(figsize=(20,7),dpi=100)
p1 = plt.subplot(111)
p1.set_title(u"fuu_expo_num_week", fontsize=15)
#tmp_data = fuu_data[fuu_data[fuu_data['score_count'].notnull()]<=200]
%time ax1=sns.distplot(fuu_data.loc[(fuu_data.fuu_expo_num_week.notnull()),'fuu_expo_num_week'],kde=True,color='g')
ax1.set_xlabel('fuu_expo_num_week',fontsize=15)
ax1.set_ylabel('density',fontsize=15)
(2)从下图可以标签 与 该特征取值的关系
plt.figure(figsize=(20,7),dpi=100)
p1 = plt.subplot(111)
plt.scatter(fuu_data.label, fuu_data.fuu_expo_num_week)
plt.xlabel(u"label")
plt.ylabel(u"fuu_expo_num_week") # 设定纵坐标名称
plt.grid(b=True, which='major', axis='y')
plt.title(u"through fuu_expo_num_week see")
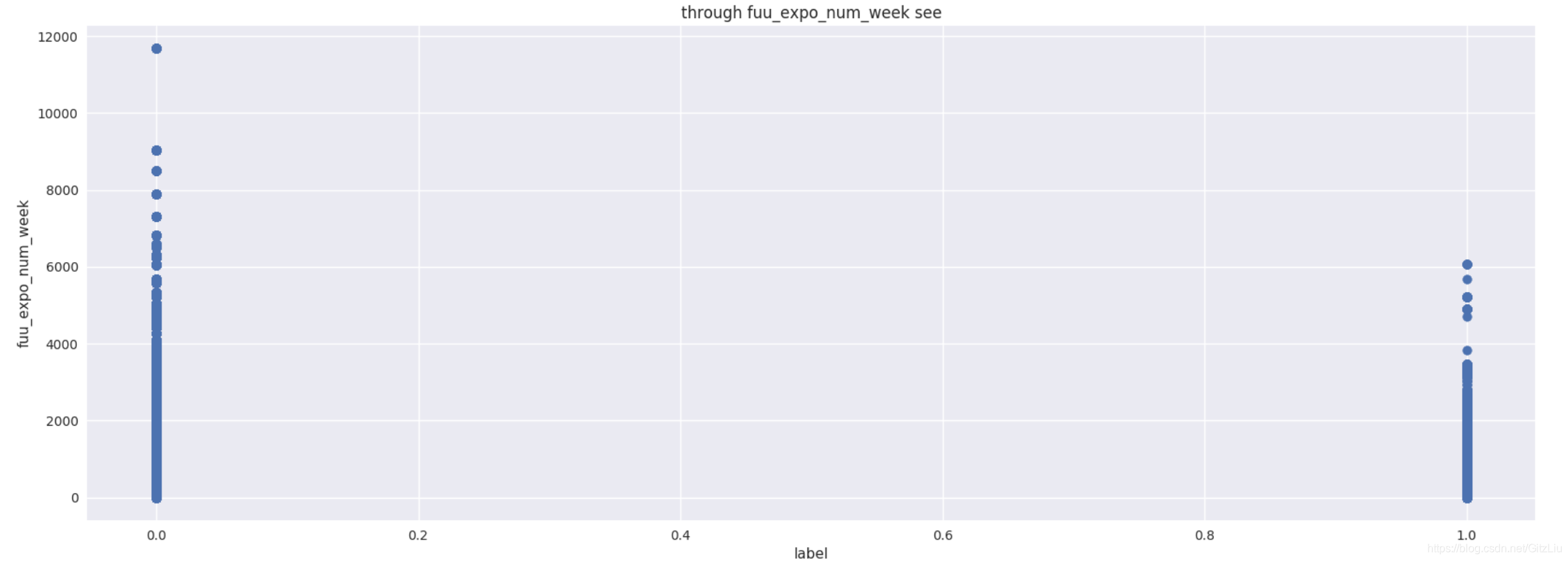
可以看到到该特征取值大于6000时,样本标签全部为1;
对35个特征,每个进行分析,并记录结论,(这是因为后面的数据处理,具体对数据进行怎样的整理【分组、归一化、onehot等】,是依据这些数据分析的结论来决定)
比如
======对每个特征进行处理=========================
4、16-21、22-25 27 29 30-34
1、label:0、1值
2、click:0、1值 无缺失值
3、m_chour:取值0-23 10个缺失值 # 缺失值10个,个 建议删除
4、m_sourceid: 取值分散且数值大部分数值较大,建议scaling 0-1 缺失10个 行号与m_chour相同 建议删除【】省略
5、m_is_business: 0、1取值 缺失10个 行号与m_chour相同 建议删除
6、m_is_long_blog: 0、1取值 缺失10个 行号与m_chour相同 建议删除
7、m_is_original: 0、1取值 缺失10个 行号与m_chour相同 建议删除
8、m_has_face: 0、1取值 缺失10个 行号与m_chour相同 建议删除
....
15、m_has_video: 0、1取值 缺失10个 行号与m_chour相同 建议删除
####
16、m_feed_expo_num_hour:0--32w左右,取值分散,建议scaler0-1 46个缺失值,建议删除;[0,05,1,1.5, 2, 2,5, 3,3.5,4, 4.5 ,5]
17、m_fwd_num_hour:0--20w左右,取0最多,取值分散,建议scaler0-1 46个缺失值,建议删除
18、m_cmt_num_hour:0-2w左右,取0最多,取值分散,建议scaler0-1 46个缺失值,建议删除
19、m_lk_num_hour:0-8w左右,取0最多,取值分散,建议scaler0-1 46个缺失值,建议删除
20、m_iar_hour:取值分散且数字较小 [0,1),这个怎么处理? 无缺失值 【分区间处理】
21、m_iar_his::取值分散且数字较小 [0,1),这个怎么处理? 无缺失值
#####
22、m_u_vtype:取值0、1、2、3;其中0、1取值明显较多,2、3取值只有个位数,有1400个缺失值 #问下这个字段的含义,看看是否拿众数添上?? 0
23、m_u_clevel:取值012345类,比较均匀、有1400个缺失值。0 阅读量==c等级 c1最高
24、m_u_fans_num:取值较分散:0到千万,1383个缺失值 ,scaler还是删除,这个scaler不合适,粉丝数多,互动机会大(是阅读者,阅读者关注的人的微博,历史互动高,则现在互动概率大)0,log分段 属于哪个区间,然后区间onehot
25、m_u_iar_month:互动率,取值0-1之间 无缺失值
#####
#26、'fuu_is_fansboth', 用户间关系,是否互关 :0、1取值,无缺失值【不处理】
#27、'fuu_affinity', 用户间亲密度:取值0-1之间,546427缺失值,不能用众数,这个怎么补?0
#28、'fuu_is_spfans', 用户间 是否是特别关注:0、1取值,无缺失值【不处理】
#29、'fuu_expo_num_week', 用户间,周曝光数:最小值1,最大值1w+,332219缺失值,这个按众数?0
#30、'fuu_ia_num_week', 用户间,周互动数:最小值0,最大值200+,332219缺失值,这个怎么处理好?0
#31\'fuu_iar_week', 用户间,周互动率,取值0-1之间,绝大数集中在0和1,无缺失值【不处理】
#32 fu_category: 1、2、3三类,70个缺失值,建议删除 1
######
#33、'mc_time_interval',: 最小值0,最大值2000+,10个缺失值,平均数或删除
#34 mobile_brand: get_dummies; 74905个缺失值,如何补? 未知类
取值:iphone 1509081
huawei 525568
oppo 274280
vivo 212669
xiaomi 184544
other_brand 74975
samsung 54300
meizu 32293
ipad 21017
oneplus 13987
smartisan 10180
meitu 6945
lenovo 3994
lemobile 1262
#35、score 打分情况:取值0-1000左右,无缺失值 【不处理】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









