







1、inode是什么?
已知linux上文件有两种数据:
1、元数据(metadata):用来描述一个文件的特征的系统数据
2、数据:泛指普通文件中的实际数据;
硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个则是inode区(inode table),用于储存文件元信息的区域。
inode与文件是一一对应的关系,每个文件都有自己的inode(inode: 中文译名为"索引节点")。根据 inode的编号,查询inode table,即可知道对应文件的元数据信息。
那元数据究竟是什么呢?
可通过stat命令可以显示文件的元数据
stat – display file or file system status(用于展示文件或文件系统的状态)
[root@ansible-client ~]# stat anaconda-ks.cfg
File: ‘anaconda-ks.cfg’
Size: 1293 Blocks: 8 IO Block: 4096 regular file
Device: fd00h/64768d Inode: 68407394 Links: 1
Access: (0600/-rw-------) Uid: ( 0/ root) Gid: ( 0/ root)
Access: 2019-07-08 17:32:32.260000000 +0800
Modify: 2019-07-08 17:32:32.261000000 +0800
Change: 2019-07-08 17:32:32.261000000 +0800
Birth: -
- 解释说明:
- File:文件名
- Size:文件大小(单位:B)
- Blocks:文件所占扇区个数,为8的倍数(通常的 Linux 的扇区大小为 512 B,连续八个扇区组成一个block)
- IO Block:每个数据块的大小(单位:B)
- regular file:普通文件(此处显示文件的类型)
- Inode:文件的Inode号*《参考链接:理解inode》*
- Links:硬链接次数
- Access:权限
- Uid:(属主id/属主名)
- Gid:(属组id/属组名)
- Access:最近访问时间
- Modify:数据改动时间
- Change:元数据改动时间
以上的参数均属于文件的元数据,元数据即用来描述数据的数据
到这里也可以类比一下,inode实际上就先当于我们的身份证号码,是文件的唯一标识。文件名称则是我们的姓名。文件的创建者、文件的创建日期、文件的大小等等都是保存在 inode表中,都需要通过文件的inode才能获取到。
2、inode table内容
inode table 包含文件系统所有文件列表
每个inode节点一般都会包含如下内容:
* 文件的字节数
* 文件拥有者的User ID
* 文件的Group ID
* 文件的读、写、执行权限
* 文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
* 链接数,即有多少文件名指向这个inode
* 文件数据block的位置,通过指针进行指定
3、inode表结构

每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
inode由上图中的左边区域组成,数据块由右边区域构成。不同的文件大小,通过多层级的间接指针协同完成。
直接块指针有12个,一个块大小为4KB,所以直接指针可以保存48KB的文件
间接块指针:每个指针占用4个字节,一个块是4KB,所以可以将一个块拆分成1024个指针,那么它的存储数据1024*4KB=4MB
双重间接块指针:同理可得它可以存储的数据为1024*4MB=4GB
三级指针可以储存文件数据大小为1024*4GB=4TB
4、查看inode
查看文件inode编号
[root@localhost ~]# ls -il
total 8
33574978 -rw-------. 1 root root 1525 Jan 29 21:03 anaconda-ks.cfg
33574982 -rw-r--r--. 1 root root 1573 Jan 30 14:56 initial-setup-ks.cfg
查看磁盘分区的inode使用情况
[root@localhost ~]# df -i
Filesystem Inodes IUsed IFree IUse% Mounted on
devtmpfs 120258 376 119882 1% /dev
tmpfs 124466 1 124465 1% /dev/shm
tmpfs 124466 883 123583 1% /run
tmpfs 124466 16 124450 1% /sys/fs/cgroup
/dev/mapper/centos-root 8910848 133204 8777644 2% /
/dev/sda1 524288 346 523942 1% /boot
tmpfs 124466 10 124456 1% /run/user/42
tmpfs 124466 1 124465 1% /run/user/0
5、linux读写文件的底层原理
假设我们想访问 A文件夹下的B文件,如下则为基本的查找流程图:
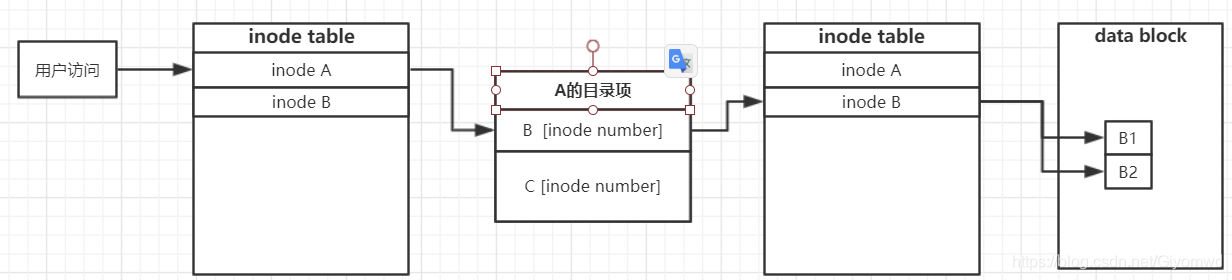
首先 系统会找到文件夹A的inode,再根据A的inode,到inode table中获取对应的inode信息,最后再根据inode信息,通过里面的指针指向文件夹数据所在的block。而A目录中有相应的目录项,目录项中有对应的文件名和inode号,根据B的inode号,再类似查找,即可获取到B的数据内容。
目录这种“特殊的文件”,可以简单地理解为是一张表,这张表里面存放了属于该目录的文件的文件名,以及所匹配的inode编号,它本身的数据也放在数据区中;读写一个文件时就这样来回的从inode和数据区之间切换。可以把文件比作一本书,inode相当于书的目录,数据区相当于书的内容,读书时得先查目录,这本书呢又放在读书馆的书架上,书架可以理解为是目录,看书前先查书架子的索引。
借鉴文章
http://www.ruanyifeng.com/blog/2011/12/inode.html
https://zhuanlan.zhihu.com/p/40604943














 1138
1138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









