







- 术语解释
| 术语 | 解释 |
|---|---|
| Application | 基于Spark的用户程序,包含了driver程序和集群上的executor |
| Driver Program | 运行main函数并且新建SparkContext的程序 |
| Cluster Manager | 在集群上获取资源的外部服务(例如:standalone,Mesos,Yarn) |
| Worker Node | 集群中任何可以运行应用代码的节点 |
| Executor | 是在一个worker node上为某应用启动的一个进程,该进程负责运行任务,并且将数据存在内存或者磁盘上。每个应用都有各自独立的executors |
| Task | 被送到某个executor上的工作单元 |
| Job | 包含很多任务的并行计算,可以看做和Spark的action对应 |
| Stage | 一个Job会被拆分很多组任务,每组任务被成为Stage(就像Mapreduce分map任务和reduce任务一样) |
首先,要分清楚Application和Job的区别,在Hadoop中,提交一个任务就为一个job,而在Spark中,启动一个Spark-shell(或者新建了一个SparkContext) 就为一个Application,Spark中的Job与Hadoop的Job概念不同。
第二,三个第三方调用框架:standalone,Mesos,Yarn,对于我们对Spark的理解没有任何的区别。
第三,不同的Application在一个节点上对应不同的executor,一个节点上可能有多个Application在运行,不同应用的executor相互隔离。而在executor内部,是通过多线程的方式运行的。
第四,对于一个SparkContext来说,什么样的Cluster Manager是无所谓的,只要通过Cluster Manager获取到executor,那么SparkContext就会把每个他上课分发到executor上,最终运行任务的是executor。当然,首先要把应用打成jar包分发到每个executor。
第五,对于一个stage的边界,可能是从外部取数据,或者到了shuffle阶段,或者是这个job结束了,这些都有可能是stage的边界。
- Cluster Overview
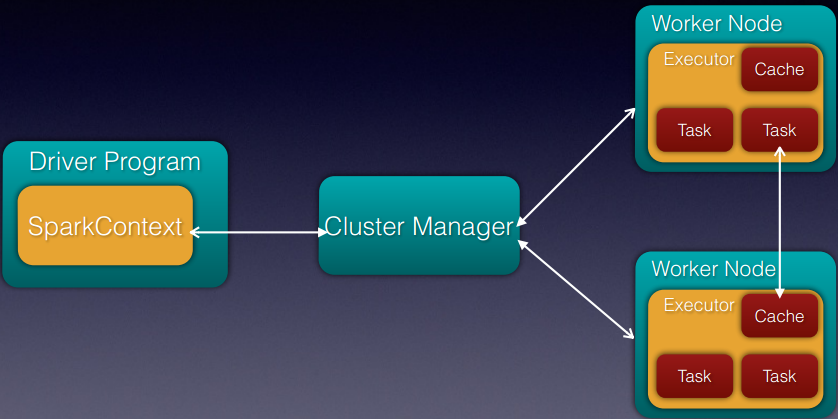
- 核心组件
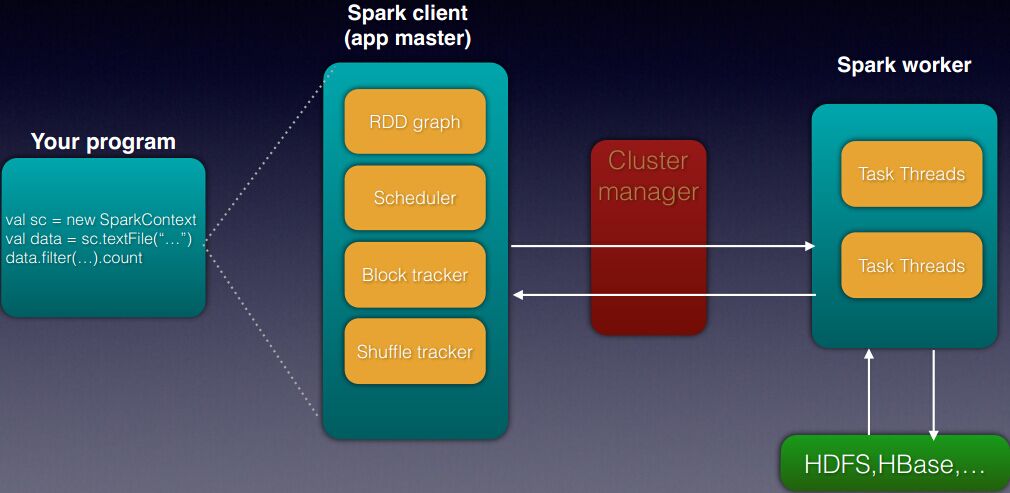
其中Block tracker是负责RDD的每个partition是怎样对应的。
Shuffle tracker负责分配建立shuffle所需要的资源。
另外,每个partition一定会分配一个task,因此partition的数量设置需要根据实际情况来选择。















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









