







Twitter公司去年在SIGMOD’15会议上发表了一篇名为Twitter Heron:Stream Processing at Scale 的论文,该文列出了Storm系统的几点不足之处,并重点介绍了Twitter公司最近开发并已经内部使用的的大数据流式计算系统Heron。最近有时间拜读了这篇论文,在这里结合我对Storm的理解来近距离一窥Heron的容貌。
Heron的中文意思为白鹭,轻盈灵活,为什么用白鹭作为新研的流式计算系统,个人想法Twitter公司认为Storm有点笨重,Nimbus主节点和Zookeeper集群负担过大,系统调试起来困难,出现问题时较难定位,于是乎,用Heron这个名字来从架构上重新设计Storm,实现一个灵活的,边界更加清晰,系统更容易调试的流式计算系统。Storm自从2011年开源之后,在工业界得到了非常广泛的使用,为流式计算的发展立下了汗马功劳。Storm的开源社区异常活跃,淘宝也在Storm的基础上开发了JStorm(核心代码用Java重新,故称为JStorm)。经过这几年的发展,Storm系统越来越成熟,但是Storm的核心架构却没有发生大的变化,Nimbus+Zookeeper+Supervisor的三层架构简单清晰,能很好的实现节点容错,但是当流式计算的规模太大时,也会给系统的性能带来一定的影响。
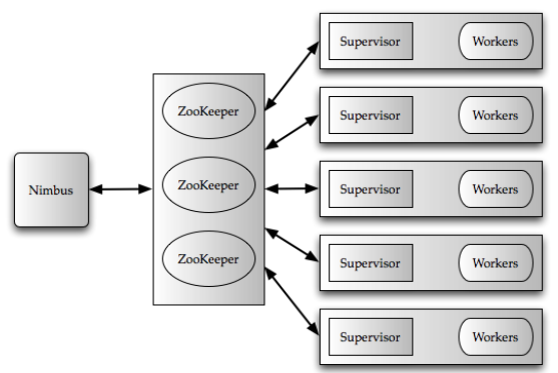
Twitter的这篇论文列举了Storm系统的几宗罪
- Worker进程:Storm中每个Worker进程有多个Executor线程组成,每个Executor线程又可以包含多个Task(Spout或者Bolt),这种复杂的多层的嵌套关系会让系统调试和资源高效分配变得比较困难。
问题一,Worker进程内部可以运行不同Task,由于这些Task在Worker进程内部并没有实现资源隔离,所以很难单独分析具体某一个Task的性能,而且如果Task在运行时发生异常导致Worker进程崩溃,则Worker进程内的其他Task也会被Kill掉,从而导致Topology的整体性能下降。
问题二,资源的不合理分配,假如有一个拓扑包括三个Spout和一个Bolt,两个Worker进程,Spout需要5G内存,Bolt需要10G内存,由于Storm中每个Worker的资源配置是相同的,而且其中一个Worker要运行一个Spout和一个Bolt,所有就要为每个Worker预分配15G内存,两个Worker共30G内存,而实际情况只需分配25G内存就可以了,导致5G内存的浪费。
问题三,Worker进程内部线程设计不合理。熟悉Storm的同学们应该知道,每个Worker进程有个全局的接收线程,负责接收上游Socket数据,并路由到指定的Executor线程,也有个全局的发送线程,负责将该进程内所有Executor产生的数据发送到下游的Worker中。在Executor内部,也包含两个线程,一个是用户逻辑线程,负责执行具体的Spout/Bolt工作,另一个是本地发送线程,负责将Executor产生的数据发送到Worker全局的数据发送队列中。这样一来,Tuple从进入Worker到从Worker出来,一共会经过四个线程,线程间的切换开销较大,同时多个Executor都在往一个全局的发送队列发送数据,也会产生队列竞争问题。 - Nimbus负担过重:在Storm设计中,Nimbus节点承担了多个任务,例如所有Topology的任务调度,监控以及JAR包的分发,当集群运行的Topology非常多时,Nimbus则会成为一个性能瓶颈。
问题一,Nimbus在任务调度时,不支持细粒度的资源分配和资源隔离。运行在同一台机器上的不同Topology的Worker可能会相互影响,从而会出现一些很难定位的性能问题。
问题二,Zookeeper性能瓶颈,Topology的状态信息均保存在Zookeeper集群中,所有Worker以及Supervisor的心跳信息都由Zookeeper来管理,Zookeeper内部数据是写入到磁盘的,所以当Topology和Worker的数量规模很大时,Zookeeper则会成为一个性能瓶颈。
问题三,Nimbus单点失败。 - 缺少反压机制:反压的意思是说当流系统下游的组件处理速度变慢时,通知上游的组件降低数据发送速度。通俗的讲,是这样,嘿,哥们,我已经处理不过来了,你先停停,别着急往我这发。
- 处理效率:这里Twitter结合生产环境实际使用情况,列举了一些降低系统性能的主要原因:
问题一,非最优的Replay机制。在Storm中,如果在Tuple在Tuple Tree中任何一个环节发生错误,就会触发Tuple Failure,然后进行Replay,当整个拓扑的扇出特别高时,则会经常性发生Tuple Replay,从而降低系统的处理效率。
问题二,较长的垃圾回收周期。比如说Worker进程消耗了大量内存,在进行垃圾回收时,花费的时间较长,然后则会导致一系列的其他问题,如Nimbus有可能会认为该Worker进程已经挂掉了,或者Tuple延迟过高触发Tuple Replay。
问题三,队列竞争,这个问题之前提到过了,Worker进程内部多个Executor都在往一个全局的发送队列发送数据,引起队列竞争。
Storm社区解决方案
论文阐述的这些问题不光Twitter公司意识到了,Storm社区同样也意识到了,上述有些问题社区也提供了相应的解决方案。比如说在解决实现Worker进程资源隔离上,Storm采用了CGroup机制。在解决Zookeeper 心跳风暴问题上,Storm引入了Pacemaker来降低Zookeeper的负载,具体可查看Storm 2.0.0-SNAPSHOT版本的文档Document。关于反压机制,淘宝的JStorm据说也有相应的实现,感兴趣的同学们可以去研究研究。
Heron系统设计及实现
讲了Storm的一些问题,那么Twitter的大神是怎么解决的呢?经过一番思想斗争,大神们准备放弃Storm,去开发一套的新的流式计算系统Heron,原因是改造一个旧框架的代价,还不如实现一个新系统,Storm就这样被狠狠的抛弃了。但是,新的系统Heron在流式计算模型上和Storm仍然保持一致,也是由一个包括多个组件的Topology组成,每个组件相互连接实现数据的流动。个人认为,Heron的最大改善就是从系统框架上的变化,它支持可插拔的集群资源管理及调度框架(如YARN, Mesos 和Docker),把资源的管理交给这些调度器去实现。还有一点变化比较大的,就是在Heron中为了能够提升系统调试能力以及性能的可预测性,每个Task对应一个进程,这个后面会讲到。下图为Heron的系统架构。
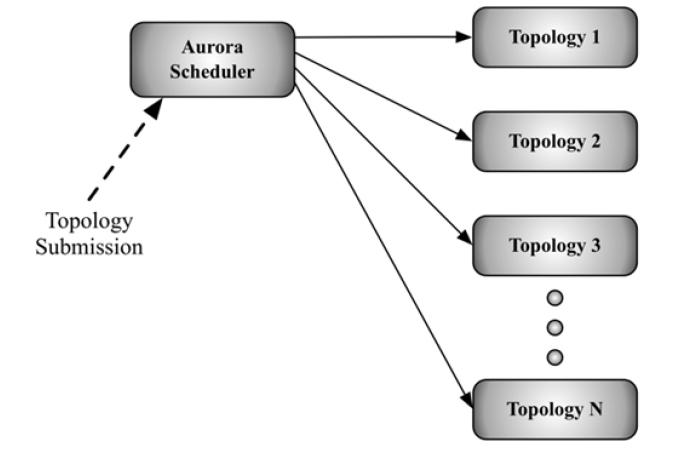
用户可以通过Heron命令行提交拓扑到Aurora Scheduler(Twitter公司内部使用的基于Mesos的资源调度器),每个Aurora Job则包含多个容器(container),熟悉YARN,Mesos的同学们应该对容器这个概念比较清楚,一个Aurora Job则对应一个Topology,这样一来,每个Topology都要各自的容器,Topology之间相互不影响。Heron中Topology 架构如下图所示。
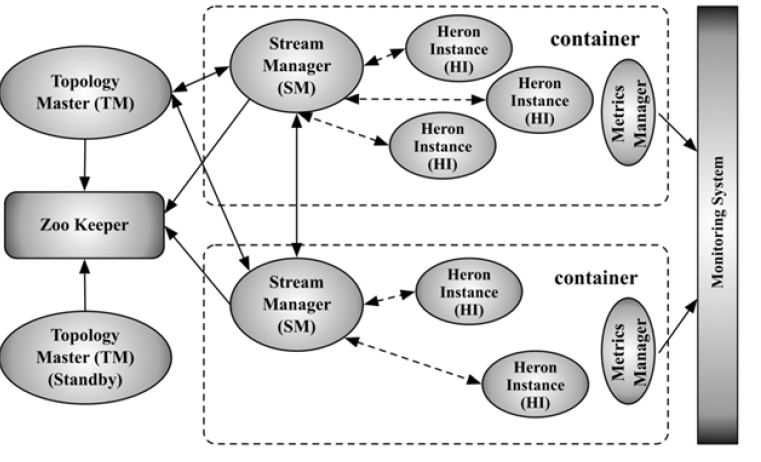
Heron拓扑中,第一个容器运行Topology Master(TM)进程,该进程负责管理整个拓扑,剩下的容器则运行Stream Manager(SM)进程、Metric Manager进程以及多个Heron Instance(HI)进程, 其中用户逻辑代价(Spout/Bolt)运行在HI进程中。为了提高可用性,增加了一个Standby TM,主备TM通过Zookeeper共享数据,Zookeeper存储了拓扑的启动时间以及拓扑的其他详细信息(如任务分配结果)。Topology Master的功能类似YARN中的Application Manager的功能,TM在启动时,会把自己的地址以临时节点的方式写入到Zookeeper中,该拓扑的其他进程可以从Z ookeeper上获取TM的地址。
Stream Manager
Stream Manager主要负责管理Tuple的路由,也就是说,在Tuple流动过程中起到一个Hub的作用,每个HI通过本地的SM来发送和接收Tuple,不同容器内部的HI进程通信,都要通过各自本地的Stream Manager,这样做的目的是降低通信网络的规模,当SM个数为k时, 网络规模则为O(k*k), 而不是O(n*n)(n为HI的个数,一般情况下n远大于k)。
那么,Heron是怎么实现反压的呢??
Heron通过降低Spout的发射速率来实现反压,当下游处理速度变慢时,直接控制源头的速率,实现上下游处理速度的协调一致。具体实现方式:当SM检测到一个或者多个HI处理速度变慢时(Streaming Manager的发送缓存变满),则SM停止从本地的Spout接收数据,接着发送 startbackpressure 消息到其他SM,通知其他SM停止接收它们本地的Spout数据。当HI处理速度提高以后,再发送 stopbackpressure 消息到其他SM, 开始继续接收本地的Spout数据。这种方式实现起来较为简单,但是不是最优的,因为有时只需要反压上游的某个Bolt的数据就可以了,不一定反压源头Spout的数据。
Heron Instance
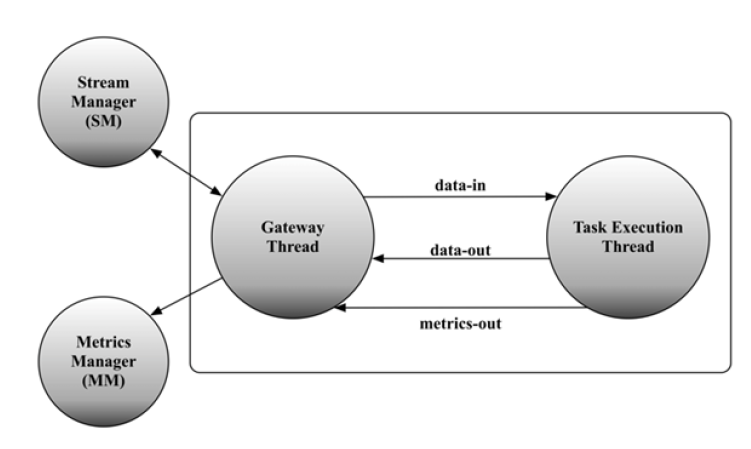
终于轮到真正实现代码逻辑的进程登场了,Twitter的大神估计在系统调试中受到了不少苦头,于是在Heron设计中,把每个Spout/Bolt作为一个进程设计,从而针对一个Spout或者Bolt,能够更方便调试和调优。
那么,HI进程内部又包含几个线程呢??两个,一个Gateway Thread,顾名思义,这个线程主要负责通信和数据交互,另外一个线程为Task Execution Thread,负责具体的逻辑实现工作。HI内部构造如下图所示:
Heron架构特点
Heron的架构总结起来主要有以下几点:
- 在资源分配与管理上,Heron采用了可插拔的资源调度器以及容器技术
- 每个Task对应一个HI进程,方便使用jstack以及heap dump进行调试
- 容易识别出拓扑中哪个组件出现问题或者性能下降,定位问题变得简单
- 实现组件级别的资源分配,减少资源的浪费
- 一个Topology Master管理一个Topology,拓扑之间彼此不受影响
- 通过反压机制实现上下游处理速率的一致
论文中,Twitter公司在实验评估的结论是,与Storm相比,Heron能大幅度的降低资源开销,同时吞吐量上有6-14倍的提升,Tuple延迟上有5-10的下降。根据论文的结果可以看出,Heron的性能与Storm相比,提升了很多。
总结
- 这篇论文没有提到Topology任务调度算法,Spout/Bolt Task如何高效的分配到各个容器上,没有提到。
- Heron的架构比Storm先进了许多,但是Storm经过最近这几年的发展(目前最新版本Version: 2.0.0-SNAPSHOT),在任务调度(Storm最新提出了一些新的调度算法)、资源分配、系统调试、功能提升以及与其他系统的集成方面也改进了许多,性能上也有了相应的提升,再加上淘宝JStorm的强势抱团,所以最新版本的Storm性能与Heron相比,只能等Heron开源以后知道了。
- 随着流式计算的应用场景越来越多,流式计算的系统也越来越多。Storm,Spark Steaming,最近开源的Apache Apex(实时分析公司datatorrent开源),如果Heron开源后,流式计算系统大家庭的成员越来越多。所以,哪个系统能够得到更多用户的青睐,可以关注一下。目前来看,还是Storm比较流行。















 609
609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









