







hive
hive概念
- 基于hadoop的数据仓库解决方案
将结构化的数据文件映射为数据库表
提供类sql的查询语言HQL(Hive Query Language)
Hive让更多的人使用Hadoop - Hive成为Apache顶级项目
Hive始于2007年的Facebook
官网:hive.apache.org
hive的优势和特点
- 提供了一个简单的优化模型
HQL类SQL语法,简化MR开发
支持在不同的计算框架上运行
支持在HDFS和HBase上临时查询数据
支持用户自定义函数、格式
成熟的JDBC和ODBC驱动程序,用于ETL和BI
稳定可靠(真实生产环境)的批处理
有庞大活跃的社区
数据库和数据仓库区别
数据库是为某种目的将结构化的数据放在一起的,放在自身database里面,主要用于事务处理
数据仓库用于OLAP(On-Line Analytical Processing),支持复杂的分析操作,存储结构化、非结构化、半结构化数据。不放在自身,数据放在hdfs。
安装zookeeper
####### 安装zookeeper #######
前置条件安装完hadoop集群
下载zoopkeeper稳定版,拖进linux里的/opt目录下
tar -zxf zookeeper-3.4.5-cdh5.14.2.tar.gz
mv zookeeper-3.4.5-cdh5.14.2 soft/zk345
cp zoo_sample.cfg zoo.cfg
修改zoo.cfg
vi zoo.cfg
dataDir=/opt/soft/zk345/tmp
如果是完全分布式还需要在其他机器上布置zookeeper并在此配置文件下根据建立例如server.0=xxx:2287:3387 多台之间端口可以重复
配置环境变量
a)Export ZOOKEEPER_HOME=/zookeeper解压路径
b)Export PATH=……:$ZOOKEEPER_HOME/bin
启动zookeeper
zkServer.sh start
安装hive
######### 安装hive #########
tar -zxf hive-1.1.0-cdh5.14.2.tar.gz
mv zookeeper-3.4.5-cdh5.14.2 soft/zk345
修改hive-site.xml
配置环境变量
a)Export HIVE_HOME=/hive解压路径
b)Export PATH=……:$HIVE_HOME/bin
schematool -dbType mysql -initSchema 初始化hive
hive --service metastore 启动hive
hiveserver2 启动beeline
beeline -u jdbc:hive2://主机地址:10000 -n root 进入beeline
hive 进入hive
!quit 退出beeline
修改mysql登录密码
修改mysql登陆密码:
set password for 'root'@'localhost'=password('1234'); 给数据库mysql设置密码
grant all privileges on *.* to 'root' @'%' identified by '1234'; 授予远程权限
flush privileges; 刷新权限
show variables like '%character%'; 设置编码格式
数据库
表的集合,hdfs中表现为一个文件夹
默认在hive.metastore.warehouse.dir属性目录下
如果没有指定数据库,默认使用default数据库
create database if not exists myhivebook;
use myhivebook;
show databases;
// 比show显示更多的细节,例如定位
describe database default;
// 改变数据库的主人
alter database myhivebook set owner user dayongd;
// cascade说明把该数据库包括表全部删除
drop database if exists myhivebook cascade;
🌰
// 插入数据
create database mydemo;
use mydemo;
create table userinfos(userid int, username string, age int);
insert into userinfos values(1,'zs',21),(2,'ls',22),(3,'ww',23);
// 查看数据
!hdfs dfs -text /usr/hive/warehouse/mydemo.db/userinfos/...
- 用完先删表,再删库,再删元数据里面的表
hive> drop table userinfos;
hive> drop database mydemo;
hive> drop table mydemo;
数据表
- 分为内部表和外部表
- 内部表(管理表)
hdfs中所属数据库目录下的子文件夹
数据完全由hive管理,删除表(元数据)会删除数据 - 外部表(External Tables)
数据保存在指定位置的hdfs路径中
hive不完全管理数据,删除表(元数据)不会删除数据
- 内部表(管理表)
hive建表语句
// IF NOT EXISTS可选,如果表存在,则忽略
CREATE EXTERNAL TABLE IF NOT EXISTS employee_external(
// 列出所有列和数据类型
name string,
work_place ARRAY<string>,
sex_age STRUCT<sex:string,age:int>,
skills_score MAP<string,int>,
depart_title MAP<STRING,ARRAY<STRING>>
)
// COMMENT可选
COMMENT 'This is an external table'
ROW FORMAT DELIMITED
// 如何分割列(字段)
FIELDS TERMINATED BY '|'
// 如何分割集合和映射
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
// 文件存储格式
STORED AS TEXTFILE
// 数据存储路径(HDFS)
LOCATION '/user/root/employee';
🌰
// 建内部表
create table class(class_id int, class_name string)
row format delimited
fields terminated by ','
stored as textfile;
插入数据:
insert into class values(1,'kb03'),(2,'kb06');
// 建外部表
create external table student(
stu_id int,
stu_name string,
age int
)
row format delimited fields terminated by ','
location '/data';
插入数据:
在外部建立数据文件d1.csv,拖进/opt,
hdfs dfs -put d1.csv /data/
hive和MapReduce
MapReduce执行效率更快,hive开发效率更快
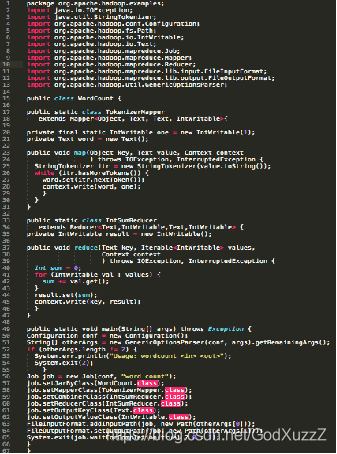
hive元数据管理
- 记录数据仓库中模型的定义、各层级间的映射关系
- 存储在关系数据库中
- 默认Derby,轻量级内嵌SQL数据库
Derby非常适合测试和演示
存储在.metastore_db目录中 - 实际生产一般存储在MySql中
修改配置文件hive-site.xml
- 默认Derby,轻量级内嵌SQL数据库
- HCatalog
将hive元数据共享给其他应用程序
hive元数据结构
| 数据结构 | 描述 | 逻辑关系 | 物理存储(hdfs) |
|---|---|---|---|
| database | 数据库 | 表的集合 | 文件夹 |
| table | 表 | 行数据的集合 | 文件夹 |
| partition | 分区 | 用于分割数据 | 文件夹 |
| buckets | 分桶 | 用于分布数据 | 文件 |
| row | 行 | 行记录 | 文件中的行 |
| columns | 列 | 列记录 | 每行中指定的位置 |
| views | 视图 | 逻辑概念,可跨越多张表 | 不存储数据 |
| index | 索引 | 记录统计数据信息 | 文件夹 |
数据类型----复杂数据类型
ARRAY:存储的数据为想同类型
MAP:具有相同类型的键值对
STRUCT:封装了一组字段
| 类型 | 格式 | 定义 | 示例 |
|---|---|---|---|
| ARRAY | [‘Apple’,‘Orange’,‘Mongo’] | ARRAY<string.> | a[0] = ‘Apple’ |
| MAP | {‘A’:‘Apple’,‘O’:‘Orange’} | MAP<string,string> | b[‘A’] = ‘Apple’ |
| STRUCT | {‘Apple’,2} | STRUCT<fruit:string,weight:int> | c.weight = 2 |
数据分层

- ODS 层
原始数据层,存放原始数据,直接加载原始日志、数据,数据保持原貌不做处理。 - DWD层
明细数据层
结构和粒度与ods层保持一致,对ods层数据进行清洗(去除空值,脏数据,超过极限范围的数据),也有公司叫dwi。 - DWS层
服务数据层
以dwd为基础,进行轻度汇总。一般聚集到以用户当日,设备当日,商家当日,商品当日等等的粒度。
在这层通常会有以某一个维度为线索,组成跨主题的宽表,比如 一个用户的当日的签到数、收藏数、评论数、抽奖数、订阅数、点赞数、浏览商品数、添加购物车数、下单数、支付数、退款数、点击广告数组成的多列表。 - ADS层
数据应用层, 也有公司或书把这层成为app层、dal层、dm层,叫法繁多。
面向实际的数据需求,以DWD或者DWS层的数据为基础,组成的各种统计报表。
统计结果最终同步到RDS以供BI或应用系统查询使用。
hive建表-Storage SerDe
Hive支持不同类型的Storage SerDe
LazySimpleSerDe: TEXTFILE
BinarySerializerDeserializer: SEQUENCEFILE
ColumnarSerDe: ORC, RCFILE
ParquetHiveSerDe: PARQUET
AvroSerDe: AVRO
OpenCSVSerDe: for CST/TSV
JSONSerDe
RegExSerDe
HBaseSerDe
hive建表高阶语句-CTAS and WITH
CTAS - as select方式建表
CTAS不能创建partition,external,bucket table
CREATE TABLE ctas_employee as SELECT * FROM employee;
CTE(CTAS with Common Table Expression)
CREATE TABLE cte_employee AS
WITH
r1 AS (SELECT name FROM r2 WHERE name = 'Michael'),
r2 AS (SELECT name FROM employee WHERE sex_age.sex= 'Male'),
r3 AS (SELECT name FROM employee WHERE sex_age.sex= 'Female')
SELECT * FROM r1 UNION ALL SELECT * FROM r3;
Like
CREATE TABLE employee_like LIKE employee;
🌰
查询userinfos表里的每个学生的分数在每个班总分的占比
select r.username,r.classname,r.score,(r.score/l.countScore*100) rate
from (select classname,sum(score) countScore from scores group by classname) l
inner join
(select u.*,s.classname,s.score from userinfos u inner join scores s on u.userid=s.userid) r
on l.classname=r.classname
with
a1 as (select classname,sum(score) countScore from scores group by classname),
a2 as (select u.*,s.classname,s.score from userinfos u inner join scores s on u.userid=s.userid)
select a2.username,a2.classname,a2.score,(a2.score/a1.countScore*100) from a1 inner join a2 on a1.classname=a2.classname
创建临时表
临时表是应用程序自动管理在复杂查询期间生成的中间数据的方法
表只对当前session有效,session退出后自动删除
表空间位于/tmp/hive-<user_name>(安全考虑)
如果创建的临时表表名已经存在,实际用的是临时表
CREATE TEMPORARY TABLE tmp_table_name1 (c1 string);
CREATE TEMPORARY TABLE tmp_table_name2 AS..
CREATE TEMPORARY TABLE tmp_table_name3 LIKE..
表操作-删除/修改表
删除表
// with perge直接删除(可选),否则会放到.Trash目录
drop table if exists employee [with perge];
// 清空表数据
truncate table employee;
修改表(alter针对元数据)
// 修改表名,常用于数据备份
alter table 表名 rename to 新表名;
// 修正表文件格式
alter table 表名 set fileformat rcfile;
// 修改列名
alter table 表名 change 旧表名 新表名 数据类型;
// 添加列
alter table 表名 add columns(列名 数据类型);
// 删除列
alter table 表名 drop [column] 列名
// 替换列
alter table 表名 replace columns (col_spec[,col_spec...])
hive分区(partitions)
- 分区主要用于提高性能
分区列的值将表划分为segments(文件夹)
查询时使用“分区”列和常规列类似
查询时hive自动过滤掉不用于提高性能的分区 - 分为静态分区和动态分区
- // 默认分区数量最大为100个,修改分区数量方法:
set hive.exec.max.dynamic.partitions.pernode=100000;
set hive.exec.max.dynamic.partitions=1000000;
set hive.exec.max.created.files=1000000;
hive分区操作-定义分区
静态分区操作
手动输入区名和区的数量
// 定义分区
create table mypart(mpid int, mapname string)
partitioned by(gender string)
row format delimited fields terminated by ',';
// 分区插入数据
create table userinfos(userid int, username string, age int, gender string);
insert into userinfos values(1,'zs',21,'male'),(2,'ls',22,'male'),(3,'ww',23,'female');
insert overwrite into mypart partition(gender='male')
select userid,username from userinfos;
// 静态分区
alter table mypart add partition(gender='male') partition(gender='female');
// 删除分区
alter table mypart drop partition(gender='male');
动态分区操作
// 设置属性
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
// 向分区插入数据
insert into table mypart partition(gender)
select userid,username,gender from userinfos;
// 向userinfos表添加列birthday
alter table userinfos add columns (birthday date);
// 创建userinfos表
create table userinfos(
userid int,
username string,
age int,
gender string,
birthday date
)
partitioned by (year int, month int)
row format delimited fields terminated by ',';
create table customs(
userid int,
username string,
age int,
gender string,
birthday string
)
row format delimited fields terminated by ',';
// 导入外部数据,把下图的表拖入linux的/opt目录下
load data local inpath '/opt/data.csv' overwrite into table mydemo.customs;
insert overwrite table userinfos partition(year,month)
select userid,username,age,gender,regexp_replace(birthday,'/','-'),split(birthday,'/')[0] as year,split(birthday,'/')[1] from customs as month;

分桶
- 分桶对应于hdfs中的文件
更高的查询处理效率
使抽样更高效
根据“桶列”的哈希函数将数据分桶 - 分桶只有动态分桶
set hive.enforce.bucketing=true; - 定义分桶,分桶的列是表中已有的列,分桶数是最好是2的n次方
clustered by (employee_id) into 2 buckets - 必须使用insert方式加载数据
create table mycust(
> userid int,
> username string,
> age int,
> gender string,
> bir string
> )
> clustered by(gender) into 2 buckets
> row format delimited fields terminated by ',';
load data local inpath '/opt/mydata.csv' into table mycust;
set hive.enforce.bucketing = true; 开启桶表
hive侧视图
常与表生成函数结合使用,将函数的输入和输出连接
outer关键字:即使output为空也会生成结果
select name,work_place,loc from employee lateral view outer explode(split(null,',')) a as loc;
支持多层级
select name,wps,skill,score from employee
lateral view explode(work_place) work_place_single as wps
lateral view explode(skills_score) sks as skill,score;
通常用于规范化行或解析json
// explode
select explode(split('hello,world',','));
// 行转列
select userid,
> sum(if(subject='chinese',score,0)) as chinese,
> sum(if(subject='math',score,0)) as math
> from tb_score
> group by userid;
// 列转行
union会去重,union all不会
select userid,'chinese' as subject,chinese as score from view_sc
> union all
> select userid,'math' as subject,math as score from view_sc;
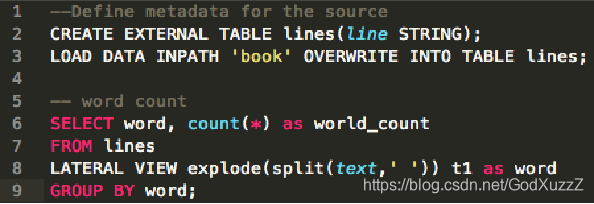
🌰
create table words(line string);
load data inpath '/opt/abc.txt' overwrite into table mydemo.words;
select word,count(*) as world_count
from words
laternal view explode(split(line,' ')) t as word
group by word;















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









