







文章目录
一、简介
1.两种部署的方式:
(1)堆放 etcd 的拓扑结构
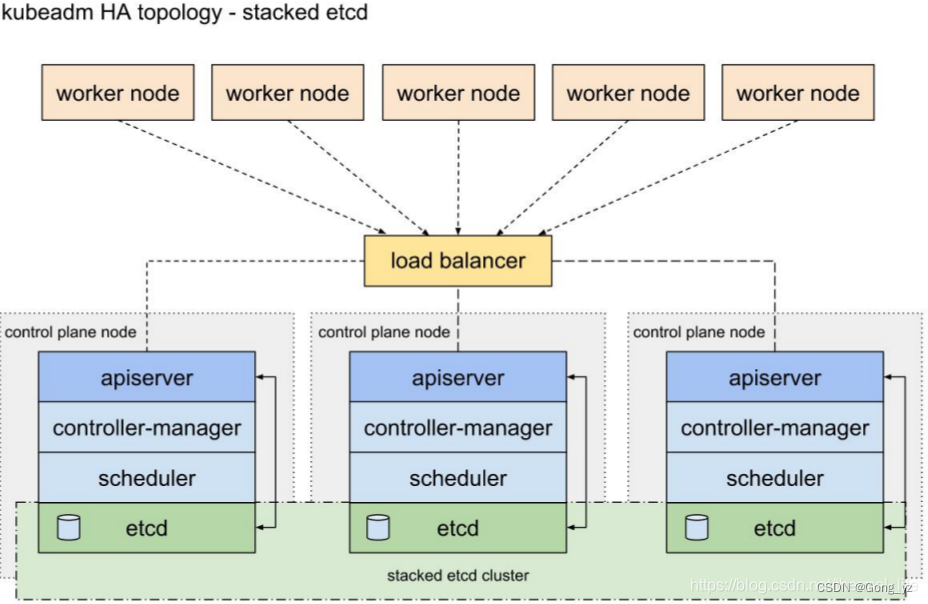
下面的三个结点是master节点,每个master节点都有完整的应用,也包括 etcd,就是说他们有独立的存储,并且有他们上层的 LB 进行负载均衡。
(2)外部etcd集群的拓扑结构
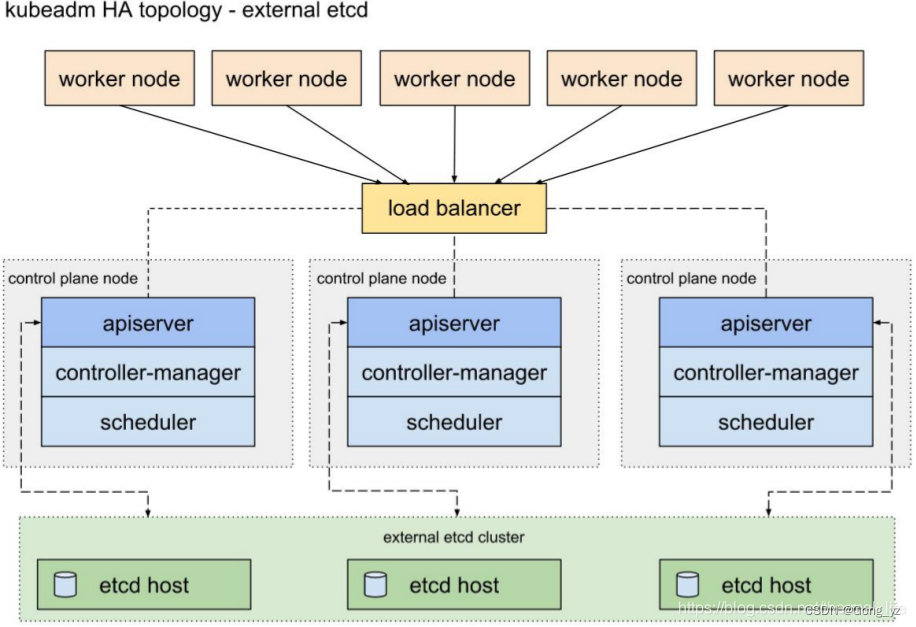
分布式的etcd 集群,将master 结点中的存储独立出来,保证了数据的高可用和冗余控制。
2.keepalived和haproxy
k8s集群用到的高可用技术主要是keepalived和haproxy
- keepalived
Keepalived主要是通过虚拟路由冗余来实现高可用功能。Keepalived一个基于VRRP(Virtual Router Redundancy Protocol - 虚拟路由冗余协议) 协议来实现的 LVS 服务高可用方案,可以利用其来解决单点故障。一个LVS服务会有2台服务器运行Keepalived,一台为主服务器(MASTER),一台为备份服务器(BACKUP),但是对外表现为一个虚拟IP,主服务器会发送特定的消息给备份服务器,当备份服务器收不到这个消息的时候,即主服务器宕机的时候, 备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。- haproxy:系统自带
haproxy 类似于nginx, 是一个负载均衡、反向代理软件。 nginx 采用master-workers 进程模型,每个进程单线程,多核CPU能充分利用。 haproxy 是多线程,单进程就能实现高性能,虽然haproxy 也支持多进程。
进程和线程的区别:
进程:进程是正在运行的程序,进程是系统进行资源分配和调用的独立单位,每一个进程都有它自己的内存空间和系统资源。
线程: 线程分为单线程和多线程,线程是进程中的单个顺序控制流,是一条执行路径。
单线程:一个进程如果只有一条执行顺序,则称为单线程程序,例如记事本,当你打开记事本的设置时,你不能再继续输入内容,必须把设置界面关闭之后才能继续输入内容,这种就是单线程程序。
多线程:一个进程如果有多条执行顺序,则称为多线程程序,例如扫雷,当你没点到炸弹时,时间会一直增加,不会等你动了之后再增加。这种就是多线程程序。
二、实验环境
| 主机名 | IP | 角色 |
|---|---|---|
| k8s1 | 192.168.56.11 | harbor仓库 |
| k8s2 | 192.168.56.12 | control-plane |
| k8s3 | 192.168.56.13 | control-plane |
| k8s4 | 192.168.56.14 | control-plane |
| k8s5 | 192.168.56.15 | haproxy,pacemaker |
| k8s6 | 192.168.56.16 | haproxy,pacemaker |
| k8s7 | 192.168.56.17 | worker node |
注:实验时master结点的cpu至少要两个,node节点1G即可;本实验采用:堆放 etcd 的拓扑结构、haproxy负载均衡
三、haproxy负载均衡:load balancer
所有的访问通过load balancer节点进行负载均衡
首先配置节点解析,所有节点解析保持一致
[root@k8s5 haproxy]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.11 k8s1 reg.westos.org
192.168.56.12 k8s2
192.168.56.13 k8s3
192.168.56.14 k8s4
192.168.56.15 k8s5
192.168.56.16 k8s6
192.168.56.17 k8s7
[root@k8s5 ~]# yum install -y haproxy net-tools
[root@k8s5 ~]# cd /etc/haproxy/
[root@k8s5 haproxy]# vim haproxy.cfg
#---------------------------------------------------------------------
defaults
mode http
log global
#option httplog ##注释掉
option dontlognull
option http-server-close
#option forwardfor except 127.0.0.0/8 #注释掉
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen status *:80 #监控;添加;便于访问,先用80端口
stats uri /status
stats auth admin:westos ##认证:用户和密码
#---------------------------------------------------------------------
# main frontend which proxys to the backends
#---------------------------------------------------------------------
frontend main *:6443 ##6443就是apiserver端口;前端
mode tcp
default_backend k8s
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend k8s ##后台,定义前端访问6443端口,后端访问哪些
mode tcp ##模式为tcp
balance roundrobin ##负载均衡
server app1 192.168.56.12:6443 check #注意:需要修改为自己的k8s control-plane地址
server app2 192.168.56.13:6443 check #注意:需要修改为自己的k8s control-plane地址
server app3 192.168.56.14:6443 check #注意:需要修改为自己的k8s control-plane地址
[root@k8s5 haproxy]# systemctl start haproxy

访问监控页面:http://192.168.56.15/status
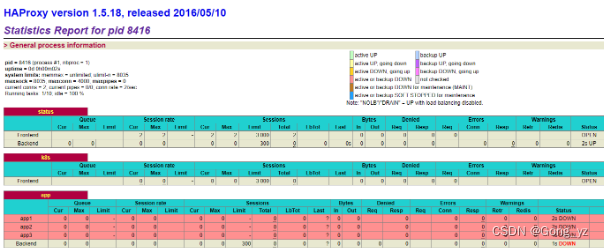
测试成功后关闭服务,不要设置自启动:资源交给高可用集群
[root@k8s5 haproxy]# systemctl stop haproxy
设置免密:方便给k8s6传输文件,因为k8s5和k8s6的配置文件基本一致
[root@k8s5 haproxy]# ssh-keygen
[root@k8s5 haproxy]# ssh-copy-id k8s6
k8s6节点安装haproxy软件
[root@k8s6 ~]# yum install -y haproxy
从k8s5拷贝配置文件至k8s6
[root@k8s5 haproxy]# scp haproxy.cfg k8s6:/etc/haproxy/
测试服务
[root@k8s6 haproxy]# systemctl start haproxy

测试成功后关闭服务,不要设置自启动
[root@k8s6 haproxy]# systemctl stop haproxy
四、pacemaker高可用:集群资源管理器
pacemaker:集群资源管理器,crm
本实验暂不采用keepalived高可用,keepalived更适合和LVS整合;pacemaker高可用对有状态的应用性能更好些

[root@k8s5 ~]# cd /etc/yum.repos.d/
[root@k8s5 yum.repos.d]# vim dvd.repo
[dvd]
name=rhel7.6
baseurl=file:///media
gpgcheck=0
[HighAvailability]
name=rhel7.6 HighAvailability
baseurl=file:///media/addons/HighAvailability ##添加高可用路径
gpgcheck=0
同步配置文件至k8s6节点
[root@k8s5 yum.repos.d]# scp dvd.repo k8s6:/etc/yum.repos.d/
安装软件
[root@k8s5 yum.repos.d]# yum install -y pacemaker pcs psmisc policycoreutils-python #pcs服务下载好了后,可以使用pcs命令
[root@k8s6 ~]# yum install -y pacemaker pcs psmisc policycoreutils-python
[root@k8s5 ~]# ssh k8s6 yum install -y pacemaker pcs psmisc policycoreutils-python ##ssh远程安装,和上一步效果一致
启动pcsd服务
[root@k8s5 ~]# systemctl enable --now pcsd.service
[root@k8s5 ~]# ssh k8s6 systemctl enable --now pcsd.service
设置用户密码:hacluster是集群的意思,下载服务后会自动创建hacluster用户
[root@k8s5 ~]# echo westos | passwd --stdin hacluster
[root@k8s5 ~]# ssh k8s6 'echo westos | passwd --stdin hacluster' ##可以cat /etc/shadow进行确认
节点认证
[root@k8s5 ~]# pcs cluster auth k8s5 k8s6
Username: hacluster ##输入
Password: westos ##输入
k8s5: Authorized ##认证成功
k8s6: Authorized ##认证成功
创建集群:加的节点必须是认证过的
[root@k8s5 ~]# pcs cluster setup --name mycluster k8s5 k8s6 ##只需要在k8s5或k8s6其中之一执行
Destroying cluster on nodes: k8s5, k8s6...
k8s6: Stopping Cluster (pacemaker)...
k8s5: Stopping Cluster (pacemaker)...
k8s6: Successfully destroyed cluster
k8s5: Successfully destroyed cluster
Sending 'pacemaker_remote authkey' to 'k8s5', 'k8s6'
k8s5: successful distribution of the file 'pacemaker_remote authkey'
k8s6: successful distribution of the file 'pacemaker_remote authkey'
Sending cluster config files to the nodes...
k8s5: Succeeded
k8s6: Succeeded
Synchronizing pcsd certificates on nodes k8s5, k8s6...
k8s5: Success
k8s6: Success
Restarting pcsd on the nodes in order to reload the certificates...
k8s5: Success
k8s6: Success
启动集群
[root@k8s5 ~]# pcs cluster start --all
k8s5: Starting Cluster (corosync)...
k8s6: Starting Cluster (corosync)...
k8s6: Starting Cluster (pacemaker)...
k8s5: Starting Cluster (pacemaker)...
集群自启动
[root@k8s5 ~]# pcs cluster enable --all
k8s5: Cluster Enabled
k8s6: Cluster Enabled
禁用stonith(禁用爆头)
[root@k8s5 ~]# pcs property set stonith-enabled=false
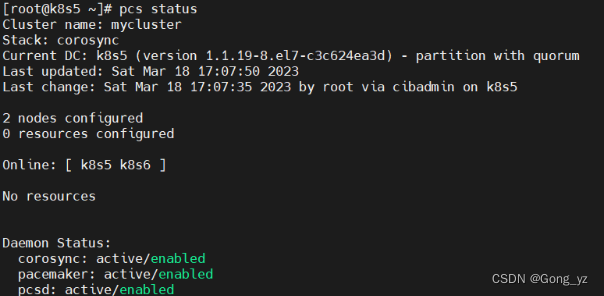
添加集群资源:
[root@k8s5 ~]# pcs resource create --help ##进行帮助;op monitor interval=30s监控频率为30s
[root@k8s5 ~]# pcs resource create vip ocf:heartbeat:IPaddr2 ip=192.168.56.200 op monitor interval=30s ##添加vip(VirtualIP)
[root@k8s5 ~]# pcs resource describe system:haproxy ##查看参数
[root@k8s5 ~]# pcs resource create haproxy systemd:haproxy op monitor interval=60s
[root@k8s5 ~]# pcs resource group add hagroup vip haproxy ##添加组;功能①约束vip和haproxy必须在同一个节点②得按照定义的顺序启动
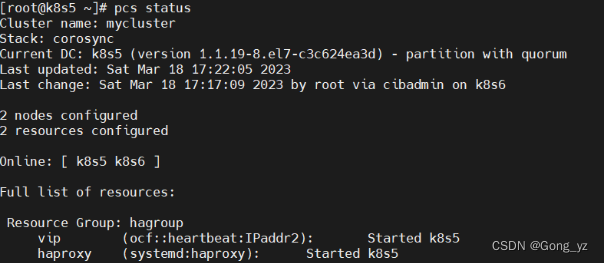
1.模拟单机故障
[root@k8s5 ~]# pcs node standby
则资源全部迁移到k8s6
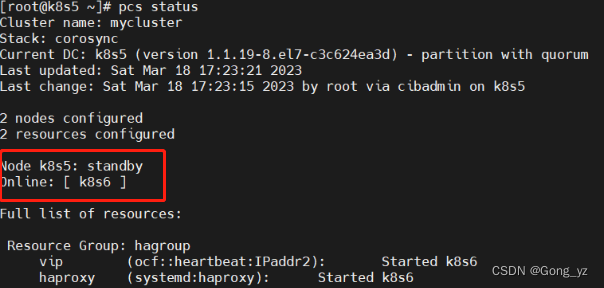
恢复后:两个节点配置一致,资源不会切回来
[root@k8s5 ~]# pcs node unstandby
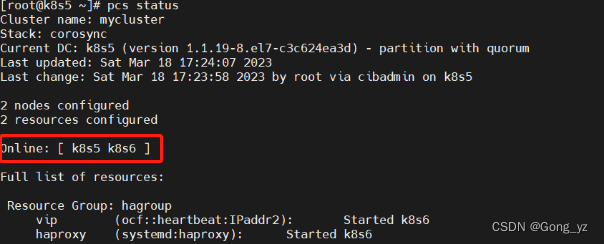
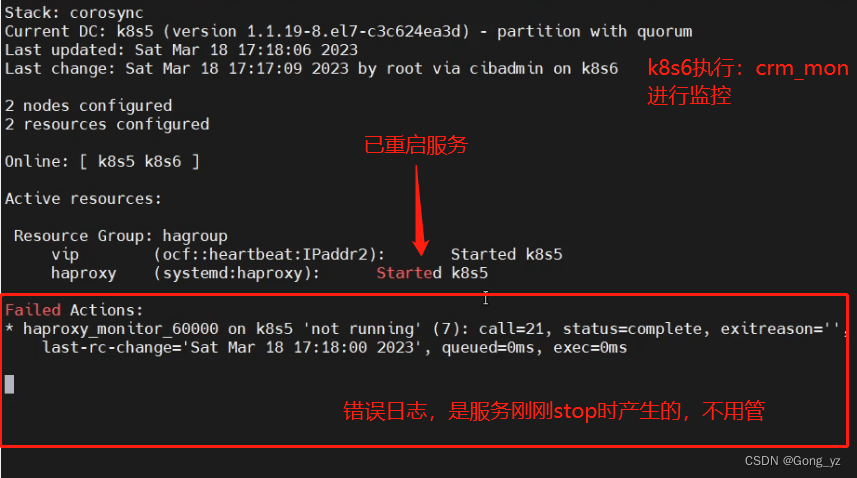
2.模拟停止haproxy/网络故障
[root@k8s5 ~]# systemctl stop haproxy.server
没有切换节点至k8s6,直接将 haproxy.server服务重启;如果重启失败,才会切换节点
模拟网络故障:
[root@k8s5 ~]# ip addr del 192。168.56.200/24 dev eth0
等待30秒后再次查看
发现pcs会报告vip掉了,但是它会自动修复
完成以上配置,之后control-plane和work node节点都是通过添加的vip:192.168.56.200:6443端口接入,达到haproxy负载后端的3个control-plane节点
五、部署containerd
k8s2、k8s3、k8s4由于之前实验的配置,所以在本实验开始前需要重置节点
【之前实验:k8s2为master节点,k8s3和k8s4为slave节点】
[root@k8s2 ~]# kubeadm reset
[root@k8s3 ~]# kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
[root@k8s4 ~]# kubeadm reset --cri-socket unix:///var/run/cri-dockerd.sock
禁用所有节点docker和cri-docker服务:k8s3、k8s4依次操作即可
[root@k8s2 ~]# systemctl disable docker
[root@k8s2 ~]# systemctl disable cri-docker
重置后k8s2、k8s3、k8s4全部节点重启:重启后/var/run/cri.docker.sock才会不存在
因为之前k8s2、k8s3、k8s4均部署过docker,所以containerd默认已经安装

生成containerd的配置文件,并修改配置
[root@k8s2 ~]# containerd config default | tee /etc/containerd/config.toml ##| tee把管道传过来的文件写到一个文件进行保存
[root@k8s2 ~]# cd /etc/containerd/
[root@k8s2 containerd]# vim config.toml ##修改内容也可见下图
...
sandbox_image = "reg.westos.org/k8s/pause:3.8" ##原来的镜像地址拉取不下来
...
SystemdCgroup = true ##


启动containerd:
[root@k8s2 containerd ]# systemctl enable containerd ##有了/var/run/containerd/containerd.sock文件
[root@k8s2 containerd ]# systemctl restart containerd ##修改后需要重启生效
[root@k8s2 ~]# crictl config runtime-endpoint unix:///run/containerd/containerd.sock
##定义runtime-endpoint路径
##/var/run软链接到/run,所以理解上面的路径和初始化的路径相同
[root@k8s2 ~]# crictl img ##img为简写,image,images均可;删镜像:crictl rmi
[root@k8s2 ~]# crictl pull reg.westos.org/k8s/pause:3.8 ##拉取镜像测试
配置harbor私有仓库
[root@k8s2 containerd]# vim /etc/containerd/config.toml
…
[plugins.“io.containerd.grpc.v1.cri”.registry]
config_path = “/etc/containerd/certs.d” ##添加存仓库的证书路径

配置container使用harbor私有仓库:
[root@k8s2 containerd]# mkdir -p /etc/containerd/certs.d/docker.io
[root@k8s2 containerd]# vim /etc/containerd/certs.d/docker.io/hosts.toml
server = "https://registry-1.docker.io"
[host."https://reg.westos.org"] ##访问默认的docker.io仓库时,直接访问https://reg.westos.org
capabilities = ["pull", "resolve", "push"]
skip_verify = true
拷贝证书
[root@k8s2 containerd]# mkdir -p /etc/containerd/certs.d/reg.westos.org
[root@k8s2 containerd]# cp /etc/docker/certs.d/reg.westos.org/ca.crt /etc/containerd/certs.d/reg.westos.org/
重启服务
[root@k8s2 containerd]# systemctl restart containerd
配置其它节点:(遇到问题,配置其他节点后可重启containerd;曾经阻塞两天的问题重启该服务得以解决!!!)
配置其它节点
[root@k8s2 containerd]# scp -r certs.d/ config.toml k8s3:/etc/containerd/
[root@k8s2 containerd]# scp -r certs.d/ config.toml k8s4:/etc/containerd/
其它节点启动containerd服务
[root@k8s3 ~]# systemctl disable --now docker cri-docker
[root@k8s3 ~]# systemctl enable --now containerd
[root@k8s3 ~]# crictl config runtime-endpoint unix:///run/containerd/containerd.sock
[root@k8s4 ~]# systemctl disable --now docker cri-docker
[root@k8s4 ~]# systemctl enable --now containerd
[root@k8s4 ~]# crictl config runtime-endpoint unix:///run/containerd/containerd.sock
六、部署control-plane
加载内核模块:在所有集群节点执行:k8s2、k8s3、k8s4
[root@k8s2 ~]# vim /etc/modules-load.d/k8s.conf
overlay
br_netfilter
[root@k8s2 ~]# modprobe overlay ##
[root@k8s2 ~]# modprobe br_netfilter ##加载模块
[root@k8s2 ~]# vim /etc/sysctl.d/docker.conf
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
[root@k8s2 ~]# sysctl --system ##查看是否读取加载的模块
确认软件版本
[root@k8s2 ~]# rpm -q kubeadm kubelet kubectl
kubeadm-1.25.0-0.x86_64
kubelet-1.25.0-0.x86_64
kubectl-1.25.0-0.x86_64
1.初始化集群
生成初始化配置文件,并进行修改
生成初始化配置文件
[root@k8s2 ~]# kubeadm config print init-defaults > kubeadm-init.yaml
修改配置
[root@k8s2 ~]# vim kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.56.12 ##192.168.56.12为本机ip
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock ####.sock
imagePullPolicy: IfNotPresent
name: k8s2 ##k8s2为本机主机名
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.56.200:6443" ##负载均衡地址;新添加
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: reg.westos.org/k8s ##本地私有仓库
kind: ClusterConfiguration
kubernetesVersion: 1.25.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16 #pod分配地址段
scheduler: {}
--- ##以下为新添加
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: ipvs #配置ipvs模式
初始化集群:
在k8s2初始化,使用生成的token在k8s3、k8s4执行,生成control-plane节点;
k8s7执行,生成node节点,生产环境中,有新加入node,执行生成的token即可
[root@k8s2 ~]# kubeadm init --config kubeadm-init.yaml --upload-certs
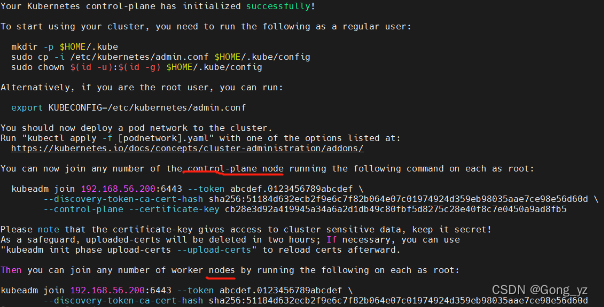
部署网络组件:否则有的pod无法就绪【flannel或者calico均可】
进入以前的calico目录,编辑文件后部署即可
[root@k8s2 calico]# kubectl apply -f calico.yaml
IPIP模块禁掉

网段为10.244,接口为eth0

测试效果如下
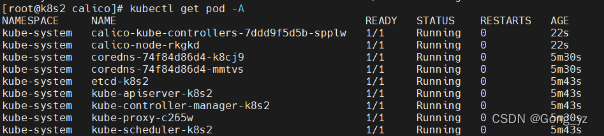
2.添加其它control-plane节点
k8s3和k8s4分别执行生成的token:建议一个节点就绪后,再加入另一个节点
[root@k8s3 containerd]# kubeadm join 192.168.56.200:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:51184d632ecb2f9e6c7f82b064e07c01974924d359eb98035aae7ce98e56d60d --control-plane --certificate-key cb28e3d92a419945a34a6a2d1db49c80fbf5d8275c28e40f8c7e0450a9ad8fb5
[root@k8s4 containerd]# kubeadm join 192.168.56.200:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:51184d632ecb2f9e6c7f82b064e07c01974924d359eb98035aae7ce98e56d60d --control-plane --certificate-key cb28e3d92a419945a34a6a2d1db49c80fbf5d8275c28e40f8c7e0450a9ad8fb5
k8s3和k8s4分别执行下面export…命令后,k8s3和k8s4节点也可以操作集群【误操作后,可用unset KUB错误的去除】

注:因为本实验的3个节点,每个etcd的原因,所以至少得有2个节点正常,只允许down一台control-plane节点
down掉的节点重启后,会自动加入集群
七、部署worker node
由于k8s7为新添加的准备作为node的节点,所以需要初始化配置
1.禁用selinux、firewalld、swap分区、添加解析
2.部署containerd
3.安装相应版本的:kubelet、kubeadm、kubectl
4.配置内核模块
添加解析
[root@k8s7 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.56.171 k8s1 reg.westos.org
192.168.56.12 k8s2
192.168.56.13 k8s3
192.168.56.14 k8s4
192.168.56.15 k8s5
192.168.56.16 k8s6
192.168.56.17 k8s7
禁用swap
[root@k8s7 ~]# swapoff -a
[root@k8s7 ~]# vim /etc/fstab

安装containerd、kubelet、kubeadm、kubectl
从其它节点拷贝repo文件
[root@k8s4 yum.repos.d]# scp k8s.repo docker.repo k8s7:/etc/yum.repos.d/
安装软件
[root@k8s7 yum.repos.d]# yum install -y containerd.io kubeadm-1.25.0-0 kubelet-1.25.0-0 kubectl-1.25.0-0
自启动服务
[root@k8s7 ~]# systemctl enable --now containerd
[root@k8s7 ~]# systemctl enable --now kubelet
拷贝containerd的配置文件
[root@k8s4 containerd]# ls
certs.d config.toml
[root@k8s4 containerd]# scp -r * k8s7:/etc/containerd/
重启服务
[root@k8s7 containerd]# systemctl restart containerd
[root@k8s7 containerd]# crictl config runtime-endpoint unix:///run/containerd/containerd.sock ##定义runtime-endpoint
[root@k8s7 containerd]# crictl pull myapp:v1 ##测试看能否从私有仓库拉取
配置内核模块
[root@k8s4 containerd]# cd /etc/modules-load.d/
[root@k8s4 modules-load.d]# scp k8s.conf k8s7:/etc/modules-load.d/
[root@k8s4 modules-load.d]# cd /etc/sysctl.d/
[root@k8s4 sysctl.d]# scp docker.conf k8s7:/etc/sysctl.d/
[root@k8s7 ~]# modprobe overlay
[root@k8s7 ~]# modprobe br_netfilter
[root@k8s7 ~]# sysctl --system
使用k8s2生成的token加入集群
[root@k8s7 ~]# kubeadm join 192.168.56.200:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:8845bd441093179e02b51a239075a64b5386085bb702c11397c21abebb132d25
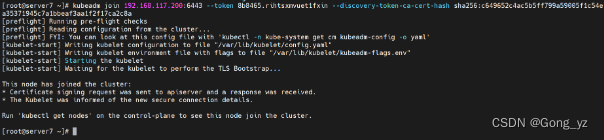
注意:加入work成功后,显示如上图
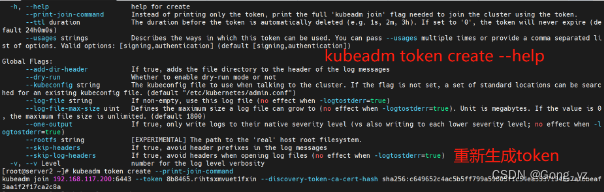
如果token失效/丢失,可以使用以下命令生成
八、测试:完成部署
[root@k8s2 ~]# kubectl get node
[root@k8s2 ~]# kubectl create deployment myapp --image myapp:v1
[root@k8s2 ~]# kubectl get pod -o wide
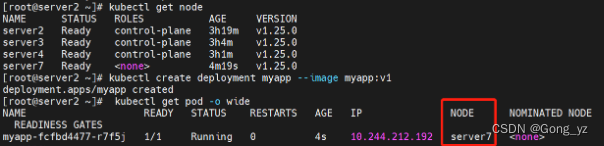
总结:以上完成k8s高可用集群的部署!,down掉一个control-plane节点、或者一台loadbalance节点不影响集群运行















 1325
1325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









