






写在前面
遵循着三天打鱼两天晒网的准则, leetcode 刷题在周末暂且休息一下,来写个爬虫玩玩
本文发布已经知乎用户- 稳重 许可
Motivation:
一个同学的文章太厉害了,同学们几乎都是他的粉丝,借由大家在假期都回到了自己的 IP 地址之地,我们只需要知道同学的出生地就能“盒”到账号
尝试使用 request
爬虫最简单的应该也就是直接用 request 和 BeautifulSoup 了吧
分析网页结构
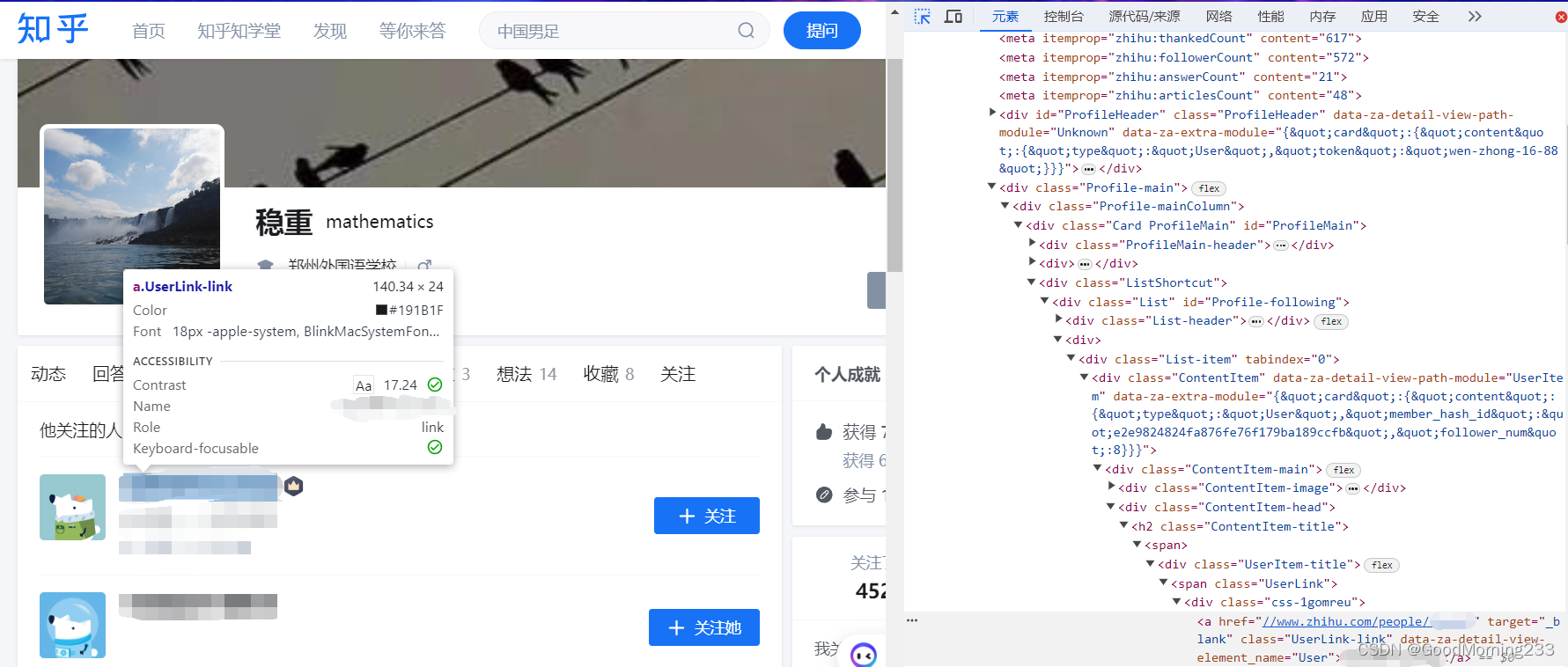
要爬取的是处于 div class="css-1gomreu" 中的元素,以此编写以下代码
def get_user():
url='https://www.zhihu.com/people/wen-zhong-16-88/followers?page=2'
response = requests.get(url)
soup = BeautifulSoup(response.text,'html.parser')
elements = soup.find_all('css-1gomreu')
PRINT(elements)但怎么只打印了个空方框!怎么回事?
再打印一下 status_code. 好! 200 没有问题
接着一步一步往上排查,让我们打印一下 response.text

不对啊,这是能跑出来的,那是 find 操作有问题吗?Ctrl+F 让我搜搜有没有 css-1gomreu :
![]()
0 result!难道我被反爬了吗,加上 cookie 什么的再看看?
def get_user():
url='https://www.zhihu.com/people/wen-zhong-16-88/followers?page=2'
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Cookie": "略"
,"X-Zse-93":"略"
,"X-Zse-96":"略"
,"X-Zst-81":"略"
}
response = requests.get(url,headers=headers)好!还是没有搜出来!(后续以为是在同一 url 中有请求 再加了params ,亦无果)
那就让我们把打印出来的 response.text 直接放浏览器里好了
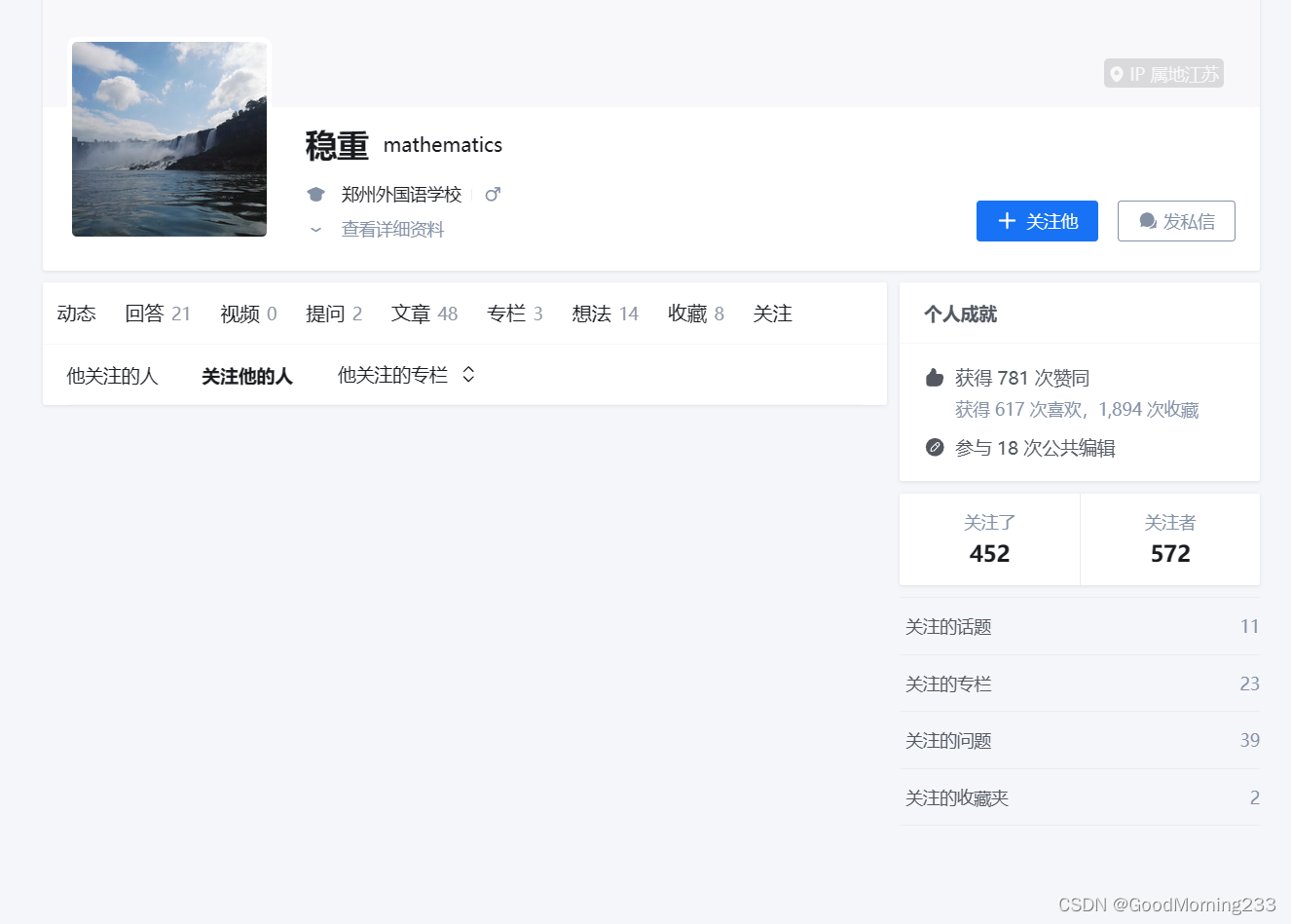
结果也是非常 Amazing 啊!除了我想要的元素以外都显示出来了
(这是在没用 headers 的情况,用了显示的就是 3 秒后跳转知乎首页了)
此时把 QQ 状态改成 emo 中,先歇一下
尝试使用 selenium
考虑到使用 request 还是蛮抽象的,毕竟也是看不见摸不着,让我们直接调一个浏览器看看吧
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.zhihu.com")
time.sleep(30)
driver.get("https://www.zhihu.com/people/wen-zhong-16-88/followers?page=3")
time.sleep(600)
driver.quit()(尝试过写登录模块,但检索不到【密码登录】,还是留 30 秒自己来登算了),可以得到以下画面
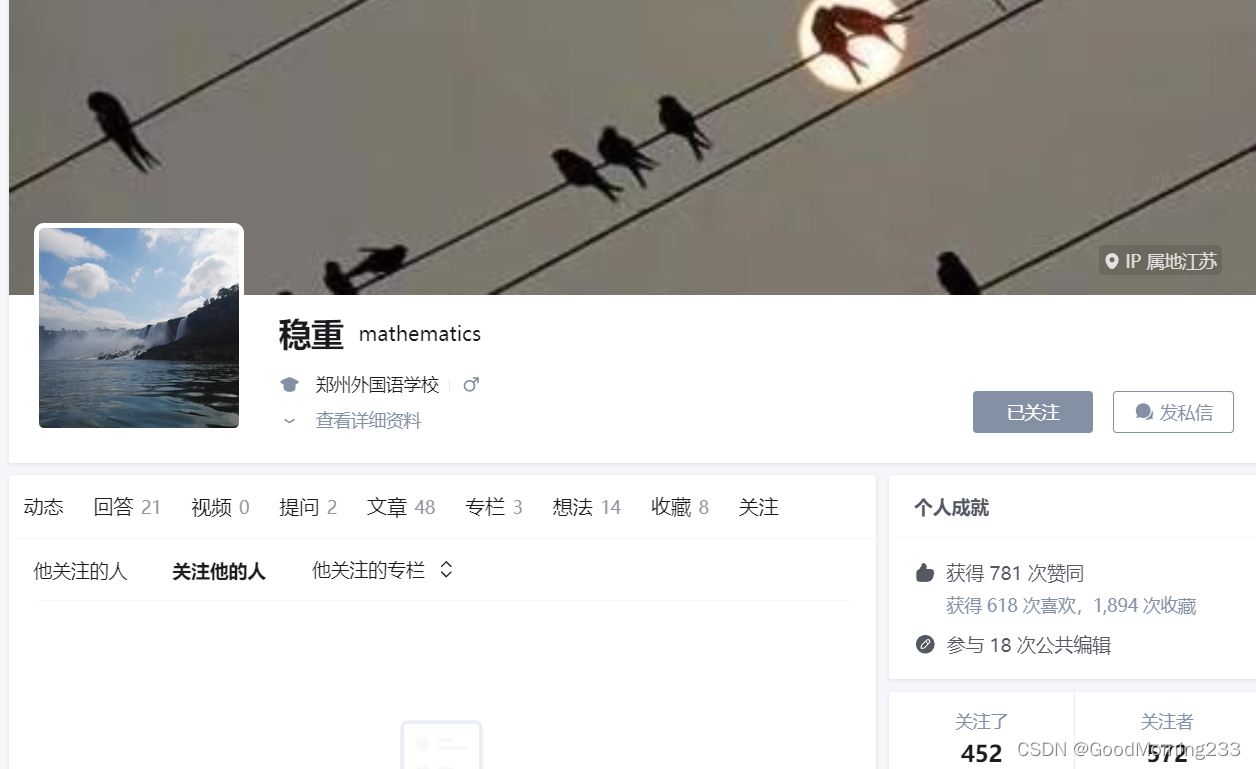
结果也是非常的神奇,后面索性将 url 改为官网,想看看是不是应该一步一步跳转才行,发现结果是一致
顿时想到我在想着拿爬虫抢课时许佬和我讲的一句话
“你都上 selenium 了,怎么不直接写脚本”
Javascript 脚本实现寻找特定 html
那就写!当然读者可能会疑惑,标题中的“面向 AI ”到底在何处还未露面?就在此处
鉴于网上对 js 脚本的课程较少,直接上 ChatGPT
(未用官网是因为懒)
寻找特定元素
如何写js脚本查找所有在某个class中的元素
要编写一个 JavaScript 脚本来查找在特定类别(class)中的所有元素,可以使用 `document.getElementsByClassName()` 方法。这个方法可以通过类名获取文档中所有具有相同类名的元素。
以下是一个示例脚本,它将查找具有指定类名的所有元素,并将它们打印到控制台:
// 获取所有具有指定类名的元素 var elements = document.getElementsByClassName('your-class-name'); // 遍历所有找到的元素并打印它们 for (var i = 0; i < elements.length; i++) { console.log(elements[i]); }在上面的代码中,将 `your-class-name` 替换为你要查找的类名。这个脚本将返回一个 HTMLCollection 对象,其中包含了匹配的所有元素。然后,使用一个循环遍历这个集合,并使用 `console.log()` 将每个元素打印到控制台。
但其实我也不知道这东西打印到哪里,于是我想着用 alert 实现 ,再加上每 5 秒执行一次(这样的想法显然是来源于抢课,不过其实是因为要等待 html 加载完毕,而我不知道等待加载完毕的 js 怎么写)
我希望你写一个js脚本,每5秒查找一次网页上class为css-1gomreu的元素并用alert打通知,如果查找不到就发通知说没找到
当然,我可以为您编写这样的 JavaScript 脚本。请注意,由于我是一个纯文本模型,无法直接在浏览器中执行 JavaScript。我将提供一个示例代码,您可以将其复制到您的项目中并在浏览器中运行。
function checkElement() { var element = document.querySelector('.css-1gomreu'); if (element) { alert('找到了!'); } else { alert('未找到!'); } } setInterval(checkElement, 5000);这段代码定义了一个
checkElement函数,它使用document.querySelector方法查找网页上具有css-1gomreu类名的元素。如果找到该元素,它将使用alert弹出一个提示框,显示 "找到了!";如果未找到,它将显示 "未找到!"。然后,我们使用
setInterval函数每隔 5 秒调用一次checkElement函数,以实现每5秒钟检查一次。请确保将此代码放在您的网页的
<script>标签中,以便在加载页面时执行脚本。
找到了的话,打印所有的element到alert里
function checkElement() { var elements = document.querySelectorAll('.css-1gomreu'); if (elements.length > 0) { var elementList = ''; for (var i = 0; i < elements.length; i++) { elementList += elements[i].outerHTML + '\n'; } alert('找到了以下元素:\n\n' + elementList); } else { alert('未找到!'); } } setInterval(checkElement, 5000);
(上图已略去其他描述的话)但接下来打印的元素中就较为繁琐
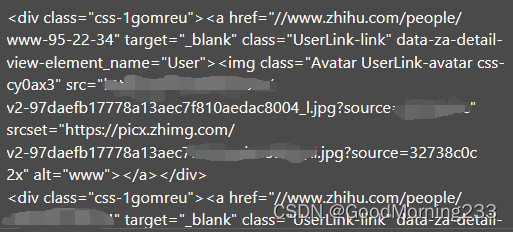
唉,没关系,起码是找到了;不过,由上图我们可以发现,如果把 class 检索改为 UserLink-link ,可以得到更简略的信息;至此完成第一步:寻找到特定 html
下载 html
function checkElement() { var elements = document.querySelectorAll('.UserLink-link'); if (elements.length > 0) { var elementList = ''; for (var i = 0; i < elements.length; i++) { elementList += elements[i].outerHTML + '\n'; alert(elements[i].outerHTML); } //alert('找到了以下元素:\n\n' + elementList); } else { alert('未找到!'); } } setInterval(checkElement, 5000);如何把获取到的 Element下载到一个文档中
// 将元素列表写入文本文件 var fileContent = '找到了以下元素:\n\n' + elementList; var blob = new Blob([fileContent], { type: 'text/plain' }); var fileName = 'elementList.txt'; // 创建一个虚拟链接并下载文件 var link = document.createElement('a'); link.href = window.URL.createObjectURL(blob); link.download = fileName; link.click();
接下来,我们只需要对每一页的粉丝都运行一下这个脚本,我们就可以下载到含有所有粉丝的数据了(此处应该可以批量处理,但我想了一下对完全不会的我来说,还是自己下更快点)

使用 BeautifulSoup 处理
接下来就是对文本批量处理,首先由以下指令得到文件名总汇
file_names = ['elementList ({}).txt'.format(i) for i in range(1, 28)]
print(file_names)接下来,我们要做的事情就是首先访问粉丝的主页,再由主页信息的 IP 进行筛选(此处以江苏举例)
我得到一份文档,如何使用request访问文档中href后的网址,并且满足,访问的网址的html中如果含有“江苏”,返回网址
keyword = "属地江苏" for link in links: href = link.get('href') # 检查链接是否存在 if href: # 使用requests访问链接 response = requests.get(href) # 检查响应状态码 if response.status_code == 200: # 检查网页内容是否包含关键字 if keyword in response.text: print("满足条件的链接:", href)
但此时出现报错:1-编码错误;2-网址以“ // ”开头,无法访问,做一些调整
#加上
href = "https:"+link.get('href')
#with open('your_document.html', 'r') as file: 改为
with open('elementList (1).txt', 'r', encoding='utf-8') as file:再有最后一步:筛选出网址后返回用户名,我们注意到在源 html 中用户名如此实现
<div class="ProfileHeader-contentHead"><h1 class="ProfileHeader-title"><span class="ProfileHeader-name">示例用户名<style da根据 GPT 回复,如此即可
username_match = re.search('<span class="ProfileHeader-name">(.+?)<', response.text)
username = username_match.group(1)其实每个用户的链接会出现两次,为此我们创建一个全局变量即可,再将所有 html 文件放到与程序相同文件夹,执行以下程序
from bs4 import BeautifulSoup
import requests
import re
num=0
file_names = ['elementList.txt', 'elementList (1).txt', 'elementList (2).txt', 'elementList (3).txt', 'elementList (4).txt', 'elementList (5).txt', 'elementList (6).txt', 'elementList (7).txt', 'elementList (8).txt', 'elementList (9).txt', 'elementList (10).txt', 'elementList (11).txt', 'elementList (12).txt', 'elementList (13).txt', 'elementList (14).txt', 'elementList (15).txt', 'elementList (16).txt', 'elementList (17).txt', 'elementList (18).txt', 'elementList (19).txt', 'elementList (20).txt', 'elementList (21).txt', 'elementList (22).txt', 'elementList (23).txt', 'elementList (24).txt', 'elementList (25).txt', 'elementList (26).txt', 'elementList (27).txt']
for file_name in file_names:
with open(file_name, 'r', encoding='utf-8') as file:
# 使用BeautifulSoup解析文档
document_content = file.read()
soup = BeautifulSoup(document_content, 'html.parser')
# 提取所有链接
links = soup.find_all('a')
keyword = "属地江苏"
for link in links:
href = "https:" + link.get('href')
# 检查链接是否存在
if href:
# 使用requests访问链接
response = requests.get(href)
# 检查响应状态码
if response.status_code == 200:
# 检查网页内容是否包含关键字
if keyword in response.text:
num+=0.5
if(num%1==0):
username_match = re.search('<span class="ProfileHeader-name">(.+?)<', response.text)
username = username_match.group(1)
print("满足条件的链接:", href, "第", int(num), "个,名字是", username)即可得到结果

Q.E.D.
(本人非计算机专业学生,并不熟悉 Javascript 的具体操作,对 Python 也不精通,在实现过程中难免走了弯路,望大佬轻喷。如果认为该行为侵犯到了您的权益,请联系作者删除)














 1823
1823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









